Clear Sky Science · es
Un método de diagnóstico de fallos en rodamientos para sistemas complejos basado en una base de reglas de creencia extendida mejorada
Por qué es importante mantener sanas las máquinas giratorias
Desde aerogeneradores hasta cintas transportadoras industriales, muchas máquinas dependen de rodamientos y engranajes que giran a alta velocidad durante años. Cuando estas piezas ocultas comienzan a fallar, pueden paralizar líneas de producción enteras o incluso provocar accidentes peligrosos. Este artículo presenta una forma nueva de detectar tales fallos de manera temprana y fiable, incluso cuando los datos del mundo real son desordenados, ruidosos y están fuertemente sesgados hacia el funcionamiento normal.
El problema de los fallos raros y las señales ruidosas
En el uso cotidiano, los rodamientos y engranajes están sanos la mayor parte del tiempo, por lo que los registros de vibración contienen muchos más ejemplos normales que defectuosos. Los métodos convencionales basados en datos, como las redes neuronales, pueden aprender patrones impresionantes pero tienden a centrarse en la clase mayoritaria, pasando a menudo por alto las firmas de fallo raras que más importan. Al mismo tiempo, los sensores de vibración operan en entornos hostiles llenos de ruido mecánico y eléctrico, lo que difumina los detalles finos necesarios para distinguir entre tipos de fallo como daño en la pista interna, daño en la pista externa o defectos en las bolas. En conjunto, estos problemas dificultan construir sistemas de diagnóstico que sean precisos y fiables fuera del laboratorio.
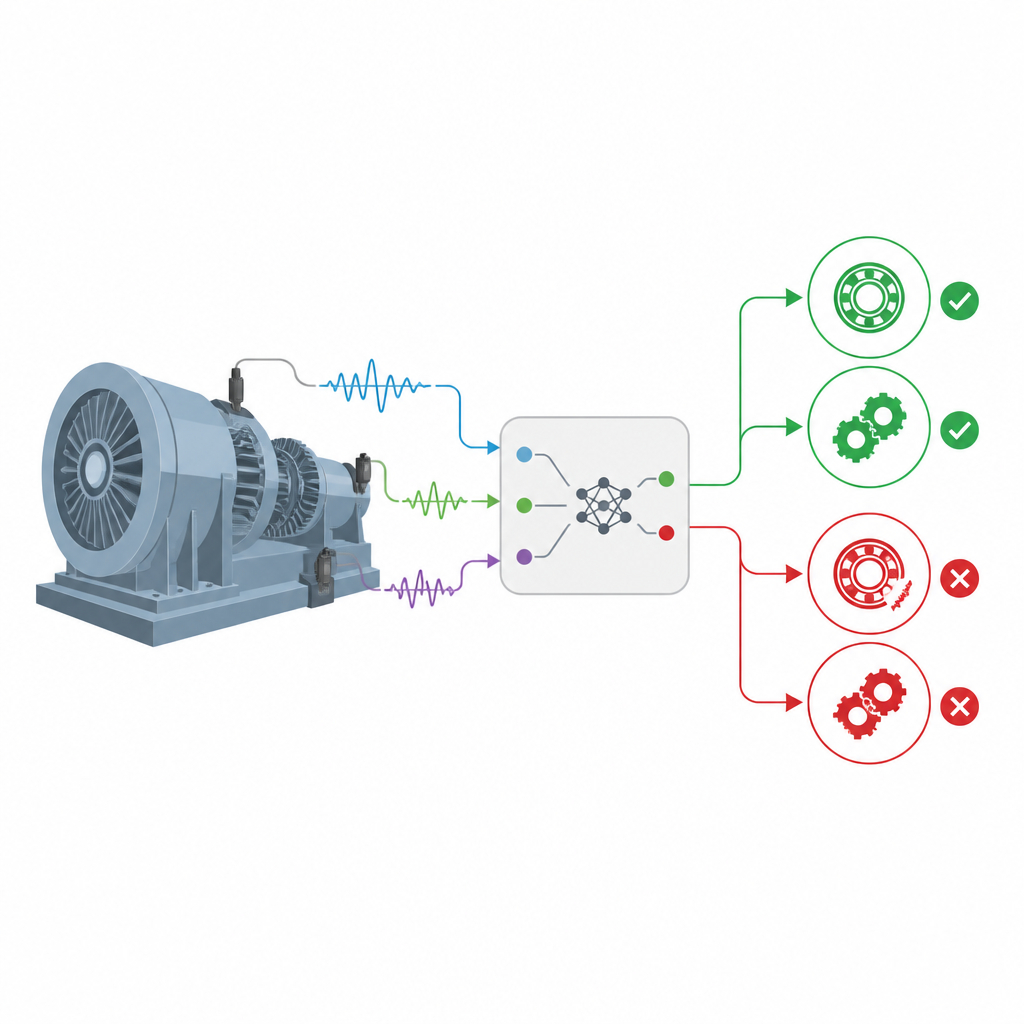
Mezclando reglas de expertos con estadísticas más inteligentes
Los autores se apoyan en una familia de modelos conocidos como bases de reglas de creencia, que combinan reglas de expertos del tipo “SI ciertas características se parecen a esto, ENTONCES el rodamiento está en ese estado” con probabilidades que expresan incertidumbre. Una versión extendida de este marco, llamada EBRB, convierte las mediciones crudas del sensor en niveles de creencia graduados (por ejemplo, muy bajo, medio o muy alto) en lugar de umbrales rígidos. Esto facilita tratar información vaga o incompleta. Sin embargo, versiones anteriores dependían de distancia geométrica simple para decidir cuán bien un nuevo patrón de vibración coincide con una regla almacenada, una elección que no refleja completamente las diferencias en las distribuciones de probabilidad subyacentes cuando las señales son ruidosas.
Medir información en lugar de distancia
Para captar mejor los cambios sutiles en los patrones de vibración, el artículo sustituye la distancia simple por una herramienta de la teoría de la información llamada divergencia de Kullback–Leibler. En lugar de preguntar qué tan lejos están dos puntos en el espacio, esta medida evalúa cuánta información se pierde cuando un patrón de probabilidad se usa para imitar a otro. Al calcular una versión simétrica de esta divergencia entre los perfiles de creencia de los datos entrantes y cada regla, el modelo puede juzgar las concordancias prestando atención a cómo se distribuye la masa de probabilidad, no solo a cuánto es. Esto conduce a una activación de reglas más precisa, especialmente cuando distintos fallos presentan una intensidad global similar pero difieren en la distribución de sus características.
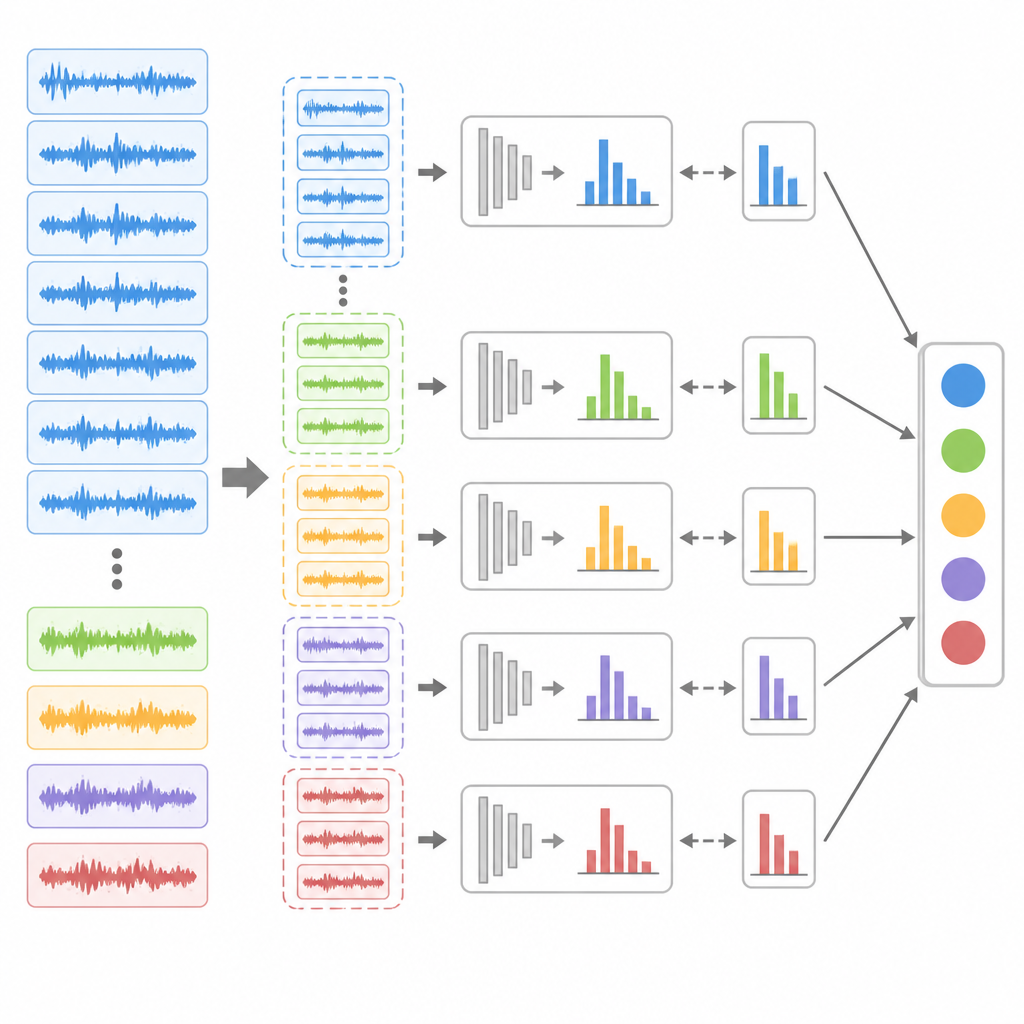
Dar a los fallos raros un voto justo
Aun con un emparejamiento mejor, un conjunto de datos desequilibrado puede seguir sesgando el aprendizaje hacia el estado mayoritario sano. Para contrarrestarlo, los autores introducen una estrategia de submuestreo en conjunto. Recortan repetidamente las abundantes muestras sanas y las combinan con todas las muestras de fallo disponibles para crear varios subconjuntos de entrenamiento balanceados. Para cada subconjunto entrenan un modelo extendido de base de reglas de creencia y, a continuación, afinan sus pesos internos usando un algoritmo de evolución diferencial, un método de búsqueda poblacional bien adaptado a paisajes complejos. En tiempo de predicción, todos estos submodelos analizan los mismos datos entrantes y un esquema de votación decide la etiqueta final de salud, dando a los patrones de fallo raros múltiples oportunidades para ser reconocidos.
Qué tan bien funciona el método en la práctica
El equipo prueba su enfoque en dos conjuntos de referencia ampliamente usados: uno para rodamientos y otro para engranajes. Para imitar condiciones realistas, entrenan con datos de vibración registrados bajo una frecuencia de muestreo u operación y prueban con datos tomados bajo otra, manteniendo un fuerte desequilibrio de clases en ambos conjuntos. En una gama de medidas como precisión, precisión por clase (precision), exhaustividad (recall) y puntuación F1, el nuevo método supera de forma consistente a los sistemas tradicionales de bases de reglas de creencia, a modelos estándar de aprendizaje automático y a técnicas populares para manejar el desequilibrio. Muestra ganancias especialmente sólidas en las clases de fallo minoritarias y mantiene un rendimiento alto incluso cuando se añade ruido artificial a características clave de la señal.
Qué significa esto para las máquinas reales
Para un no especialista, el mensaje clave es que este método ofrece a rodamientos y engranajes un “chequeo de salud” más fiable bajo las condiciones desordenadas que se encuentran en plantas reales. Al combinar reglas al estilo experto con una forma más inteligente de comparar patrones de probabilidad y un sistema de votación justo para eventos raros, el enfoque reduce el riesgo de que las señales tempranas de daño queden ahogadas por la avalancha de datos normales y el ruido de fondo. Los autores concluyen que su base de reglas de creencia en conjunto puede proporcionar un diagnóstico de fallos preciso, interpretable y resistente al ruido, y sugieren extenderlo a otras piezas rotativas mientras automatizan cuántos subconjuntos de datos son necesarios para un rendimiento óptimo.
Cita: Yan, X., Li, N., Nan, S. et al. A bearing fault diagnosis method for complex system based on improved extended belief rule base. Sci Rep 16, 15827 (2026). https://doi.org/10.1038/s41598-026-44629-8
Palabras clave: diagnóstico de fallos en rodamientos, diagnóstico de fallos en engranajes, monitorización por vibraciones, aprendizaje en conjunto, base de reglas de creencia