Clear Sky Science · en
A bearing fault diagnosis method for complex system based on improved extended belief rule base
Why keeping spinning machines healthy matters
From wind turbines to factory conveyors, many industrial machines rely on rolling bearings and gears that spin at high speed for years on end. When these hidden parts begin to fail, they can bring entire production lines to a halt or even trigger dangerous accidents. This paper presents a new way to spot such faults early and reliably, even when real-world data are messy, noisy, and heavily skewed toward normal operation.
The trouble with rare faults and noisy signals
In everyday use, bearings and gears are healthy most of the time, so vibration records contain far more normal examples than faulty ones. Standard data-driven methods, such as neural networks, can learn impressive patterns but tend to focus on the majority class, often overlooking the rare fault signatures that matter most. At the same time, vibration sensors sit in harsh environments filled with mechanical and electrical noise, which blurs the fine details needed to distinguish between different fault types like inner race damage, outer race damage, or ball defects. Together, these issues make it hard to build diagnostic systems that are both accurate and trustworthy outside the lab.
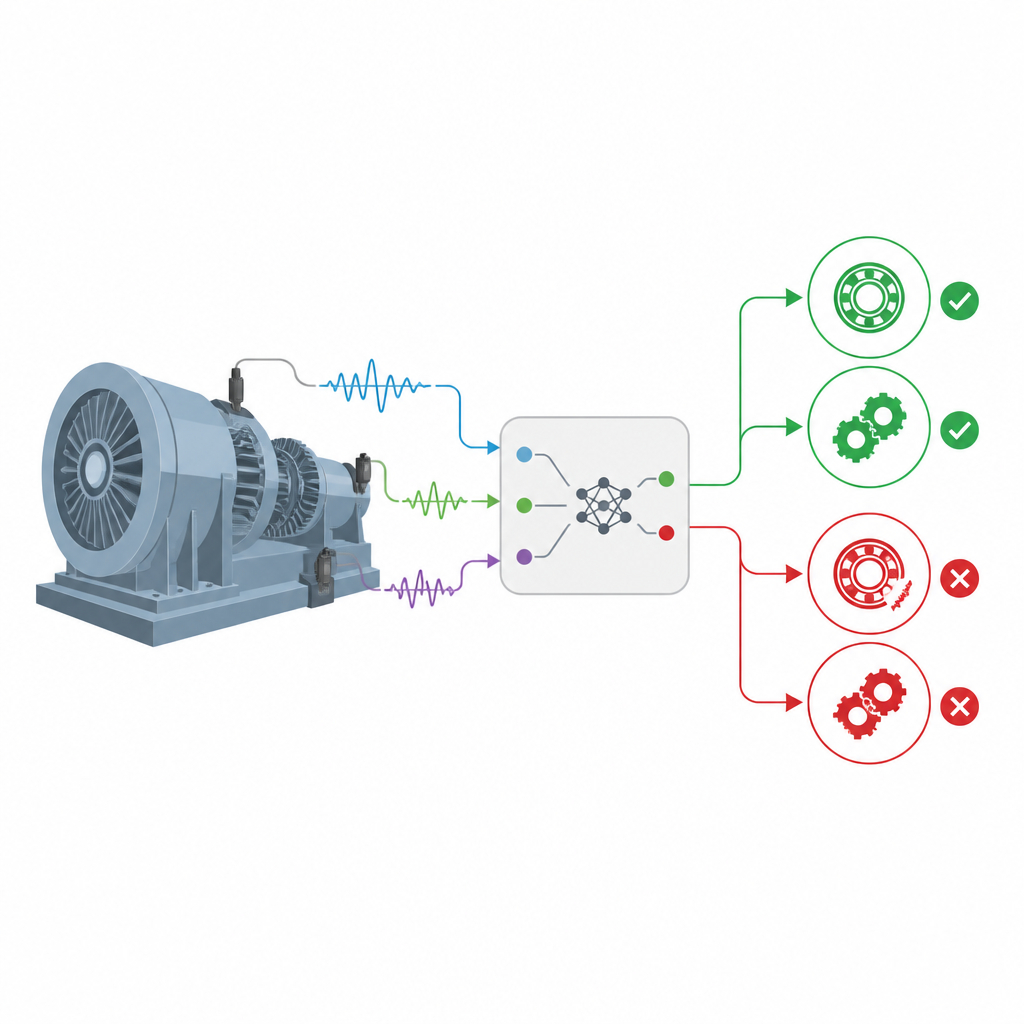
Blending expert rules with smarter statistics
The authors build on a family of models known as belief rule bases, which combine expert rules of the form “IF certain features look like this, THEN the bearing is in that state” with probabilities that express uncertainty. An extended version of this framework, called EBRB, turns raw sensor measurements into graded belief levels (for example, very low, medium, or very high) instead of hard thresholds. This makes it easier to cope with vague or incomplete information. However, earlier versions relied on simple geometric distance to decide how well a new vibration pattern matches a stored rule, a choice that does not fully reflect differences in underlying probability distributions when signals are noisy.
Measuring information instead of distance
To better capture subtle changes in vibration patterns, the paper replaces plain distance with a tool from information theory called Kullback–Leibler divergence. Rather than asking how far two points are in space, this measure asks how much information is lost when one probability pattern is used to mimic another. By computing a symmetric version of this divergence between the belief profiles of incoming data and each rule, the model can judge matches in a way that pays attention to how probability mass is arranged, not just how big it is. This leads to more precise rule activation, especially when different faults look similar in overall strength but differ in the distribution of their features.
Giving rare faults a fair vote
Even with better matching, an imbalanced dataset can still bias learning toward the majority healthy state. To counter this, the authors introduce an ensemble undersampling strategy. They repeatedly trim down the abundant healthy samples and combine them with all available fault samples to create several balanced training subsets. For each subset, they train a separate extended belief rule model and then fine-tune its internal weights using a differential evolution algorithm, a population-based search method well suited to complex landscapes. At prediction time, all these sub‑models analyze the same incoming data, and a voting scheme decides the final health label, giving rare fault patterns multiple opportunities to be recognized.
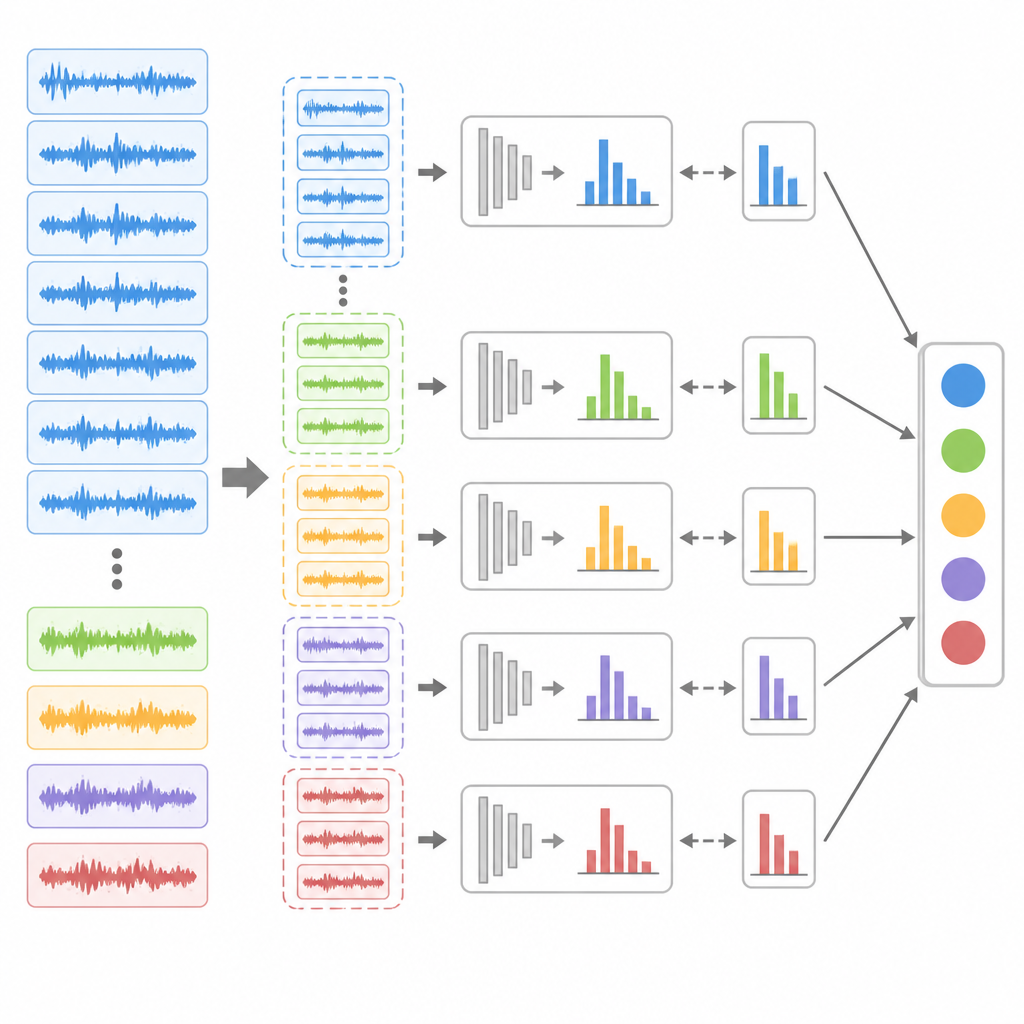
How well the method works in practice
The team tests their approach on two widely used benchmark datasets: one for rolling bearings and one for gears. To mimic realistic conditions, they train on vibration data recorded under one sampling frequency or operating condition and test on data taken under another, while preserving strong class imbalance in both sets. Across a range of measures such as accuracy, precision, recall, and F1‑score, the new method consistently beats traditional belief rule systems, standard machine learning models, and popular imbalance-handling techniques. It shows especially strong gains on the minority fault classes and maintains high performance even when artificial noise is added to key signal features.
What this means for real machines
For a non‑specialist, the key message is that this method gives bearings and gears a more reliable “health check” under the messy conditions found in real plants. By combining expert-style rules with a smarter way to compare probability patterns and a fair voting system for rare events, the approach reduces the risk that early signs of damage will be drowned out by the flood of normal data and background noise. The authors conclude that their ensemble belief rule base can provide accurate, interpretable, and noise‑resistant fault diagnosis, and they suggest extending it to other rotating parts while automating how many data subsets are needed for best performance.
Citation: Yan, X., Li, N., Nan, S. et al. A bearing fault diagnosis method for complex system based on improved extended belief rule base. Sci Rep 16, 15827 (2026). https://doi.org/10.1038/s41598-026-44629-8
Keywords: bearing fault diagnosis, gear fault diagnosis, vibration monitoring, ensemble learning, belief rule base