Clear Sky Science · it
Un metodo di diagnosi dei guasti dei cuscinetti per sistemi complessi basato su una base di regole di credenza estesa migliorata
Perché è importante mantenere in salute le macchine rotanti
Dalle turbine eoliche ai nastri trasportatori di fabbrica, molte macchine industriali si affidano a cuscinetti volventi e ingranaggi che girano ad alta velocità per anni. Quando queste parti nascosto iniziano a guastarsi, possono fermare intere linee di produzione o persino causare incidenti pericolosi. Questo articolo presenta un nuovo modo per individuare tali guasti precocemente e in modo affidabile, anche quando i dati reali sono disordinati, rumorosi e fortemente sbilanciati verso il funzionamento normale.
Il problema dei guasti rari e dei segnali rumorosi
Nell’uso quotidiano, cuscinetti e ingranaggi sono per lo più in buono stato, quindi i registri di vibrazione contengono molti più esempi normali che difettosi. I metodi data‑driven standard, come le reti neurali, possono apprendere schemi impressionanti ma tendono a concentrarsi sulla classe di maggioranza, trascurando spesso le firme di guasto rare che contano di più. Allo stesso tempo, i sensori di vibrazione operano in ambienti severi pieni di rumore meccanico ed elettrico, che sfuma i dettagli fini necessari per distinguere tra tipi di guasto come danni alla pista interna, alla pista esterna o difetti delle sfere. Insieme, questi aspetti rendono difficile costruire sistemi diagnostici accurati e affidabili al di fuori del laboratorio.
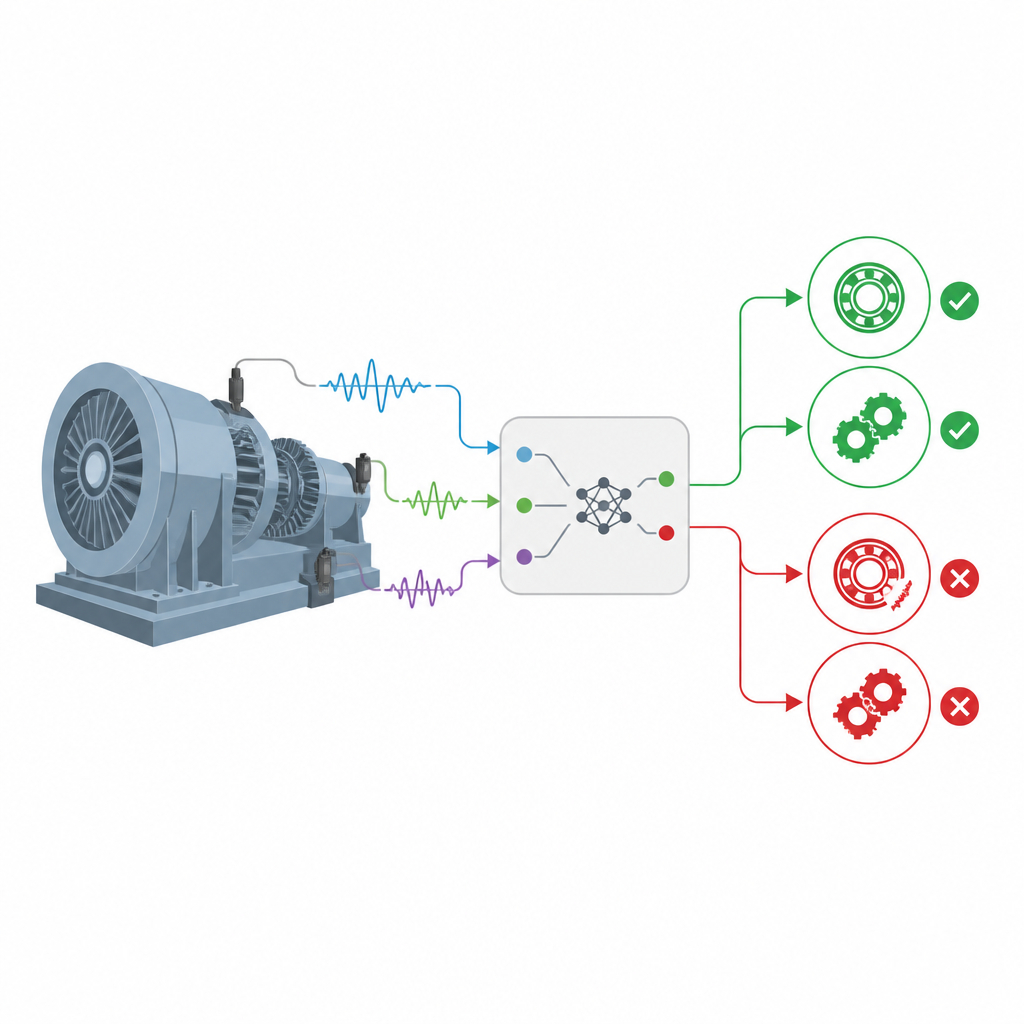
Fondere regole di esperti con statistiche più intelligenti
Gli autori partono da una famiglia di modelli noti come basi di regole di credenza, che combinano regole esperte del tipo “SE certe caratteristiche appaiono così, ALLORA il cuscinetto si trova in quello stato” con probabilità che esprimono incertezza. Una versione estesa di questo framework, chiamata EBRB, trasforma le misure grezze dei sensori in livelli di credenza graduati (ad esempio molto basso, medio o molto alto) invece di soglie rigide. Questo facilita la gestione di informazioni vaghe o incomplete. Tuttavia, le versioni precedenti si basavano su una semplice distanza geometrica per decidere quanto un nuovo pattern di vibrazione corrispondesse a una regola memorizzata, scelta che non riflette pienamente le differenze nelle distribuzioni di probabilità sottostanti quando i segnali sono rumorosi.
Misurare l’informazione invece della distanza
Per catturare meglio i cambiamenti sottili nei pattern di vibrazione, l’articolo sostituisce la distanza semplice con uno strumento della teoria dell’informazione chiamato divergenza di Kullback–Leibler. Piuttosto che chiedersi quanto sono lontani due punti nello spazio, questa misura valuta quanta informazione si perde quando un pattern di probabilità viene usato per imitare un altro. Calcolando una versione simmetrica di questa divergenza tra i profili di credenza dei dati in arrivo e ciascuna regola, il modello può giudicare le corrispondenze in modo da considerare come la massa di probabilità è distribuita, non solo la sua entità. Ciò porta ad una attivazione delle regole più precisa, soprattutto quando diversi guasti appaiono simili in intensità complessiva ma differiscono nella distribuzione delle loro caratteristiche.
Dare ai guasti rari un voto equo
Anche con un matching migliore, un dataset sbilanciato può ancora indurre il modello ad apprendere a favore dello stato sano maggioritario. Per contrastare questo, gli autori introducono una strategia di undersampling in ensemble. Ripetutamente riducono il numero di campioni abbondanti della classe sana e li combinano con tutti i campioni di guasto disponibili per creare diversi sottoinsiemi di addestramento bilanciati. Per ogni sottoinsieme, addestrano un modello esteso di regole di credenza separato e ne ottimizzano i pesi interni usando un algoritmo di evoluzione differenziale, un metodo di ricerca basato su popolazione adatto a paesaggi complessi. In fase di predizione, tutti questi sub‑modelli analizzano gli stessi dati in ingresso e uno schema di voto decide l’etichetta finale di salute, dando alle firme di guasto rare più opportunità di essere riconosciute.
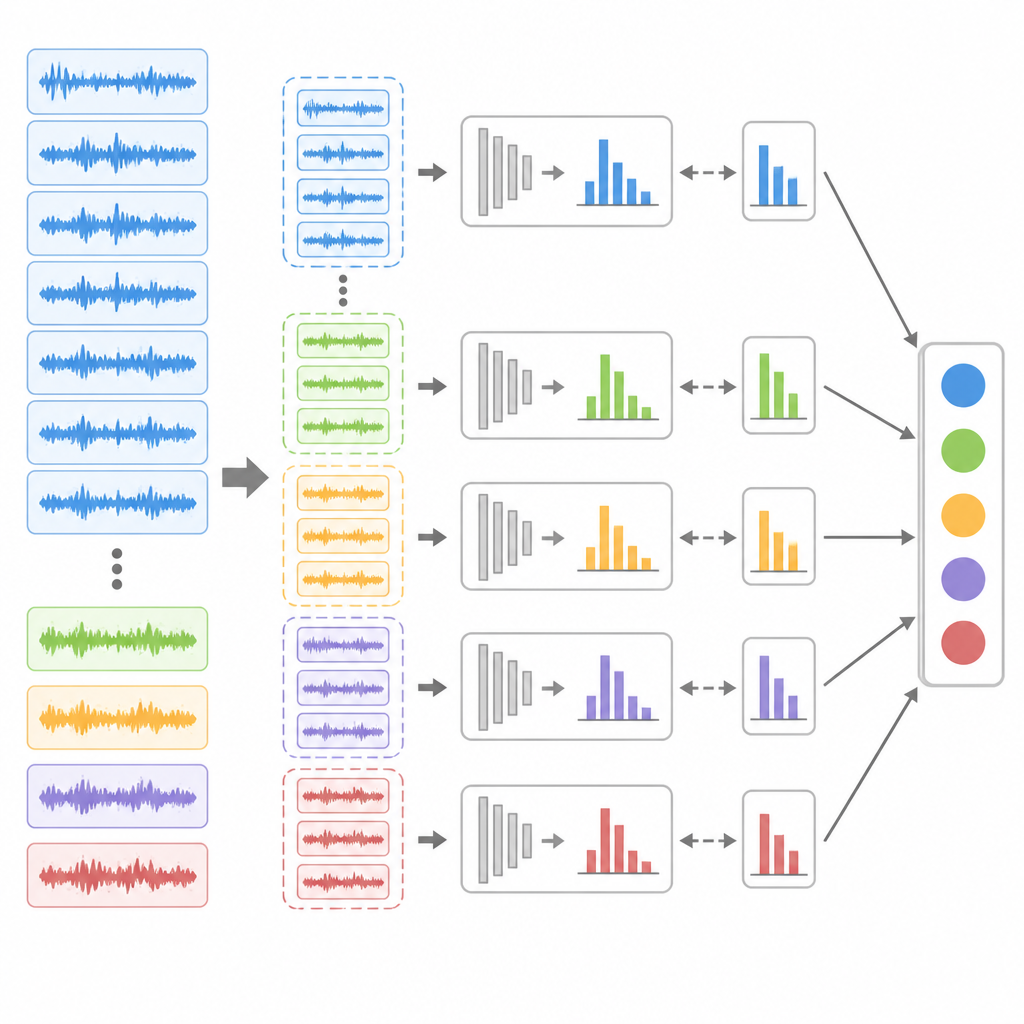
Quanto bene funziona il metodo nella pratica
Il team testa il loro approccio su due dataset di riferimento ampiamente usati: uno per i cuscinetti volventi e uno per gli ingranaggi. Per simulare condizioni realistiche, addestrano su dati di vibrazione registrati a una frequenza di campionamento o condizione operativa e testano su dati presi in un’altra, mantenendo un forte sbilanciamento di classe in entrambi i set. Su una gamma di metriche come accuratezza, precisione, recall e F1‑score, il nuovo metodo supera costantemente i sistemi tradizionali di regole di credenza, i modelli di machine learning standard e le tecniche popolari per la gestione dello sbilanciamento. Mostra guadagni particolarmente marcati sulle classi di guasto minoritarie e mantiene prestazioni elevate anche quando viene aggiunto rumore artificiale a caratteristiche chiave del segnale.
Cosa significa per le macchine reali
Per un non specialista, il messaggio chiave è che questo metodo fornisce un “check‑up” più affidabile per cuscinetti e ingranaggi nelle condizioni disordinate tipiche degli impianti reali. Combinando regole in stile esperto con un modo più intelligente di confrontare i pattern di probabilità e con un sistema di voto equo per gli eventi rari, l’approccio riduce il rischio che i segni precoci di danneggiamento vengano sommersi dall’abbondanza di dati normali e dal rumore di fondo. Gli autori concludono che la loro base di regole di credenza in ensemble può offrire una diagnosi di guasto accurata, interpretabile e resistente al rumore, suggerendo di estenderla ad altre parti rotanti e di automatizzare la scelta del numero di sottoinsiemi di dati necessari per ottenere le migliori prestazioni.
Citazione: Yan, X., Li, N., Nan, S. et al. A bearing fault diagnosis method for complex system based on improved extended belief rule base. Sci Rep 16, 15827 (2026). https://doi.org/10.1038/s41598-026-44629-8
Parole chiave: diagnosi dei guasti dei cuscinetti, diagnosi dei guasti agli ingranaggi, monitoraggio delle vibrazioni, ensemble learning, base di regole di credenza