Clear Sky Science · zh
通过 M-LoRA 微调 LLAMA-3 和基于人工反馈的 PPO 强化学习提升雅思写作自动评分
更智能的作文帮助为何重要
每年有数百万人通过雅思考试获得出国留学、工作或移民的机会。然而,许多考生在写作部分困难重重——获得清晰、可靠的反馈并不容易,而请人工导师费用又可能很高。本文探索了一种利用人工智能的新方法,不仅用于为雅思作文评分,还用于提供详尽、类人化的建议,帮助写作者真正提升,并且使反馈与真实评分员的判断保持高度一致。

评判写作的挑战
评估一篇作文的质量比检查拼写或计数单词要复杂得多。人工评分员会关注考生是否回答了题目、思路组织是否清晰、词汇是否丰富且准确、以及语法是否正确且多样。现有的自动评分系统常常只在狭窄、固定的问题集上表现良好,而且在接触新类型作文时可能会“遗忘”如何判断早期类型的文章。像 GPT-4 这样的巨型语言模型展现了潜力,但直接使用时仍难以完全匹配人工评分,并且往往给出泛泛、千篇一律的反馈。
构建丰富的雅思写作数据集
为了突破这些限制,作者首先构建了一个新的私有数据集,包含 5,088 篇由中国学习者撰写的真实雅思写作第二任务(Task 2)作文。每篇作文都由有经验的雅思教师按照四项官方评分标准给出分数:任务回应(Task Response)、衔接与连贯(Coherence and Cohesion)、词汇资源(Lexical Resource)以及句法范围与准确性(Grammatical Range and Accuracy)。更重要的是,教师还提供了细粒度的反馈,指出诸如观点不清、句间衔接僵硬或词汇薄弱等问题,并提出改写建议。这类丰富的标注远超典型的公开数据集,成为训练和测试新系统的基础。
三步式智能写作教练
所提出的系统基于 LLaMA‑3 这一现代大型语言模型,并使用一种称为多任务 LoRA(Multi‑task LoRA)的轻量级微调方法进行增强。第一步,模型被训练以同时处理多项任务:对于任一作文,它预测四项雅思评分标准的分数区间(band score),并为每个方面生成针对性评论。分别的“头”聚焦于各个特质,同时共享对文本的通用理解,这有助于模型在面对多样化提示时避免通常的“灾难性遗忘”。
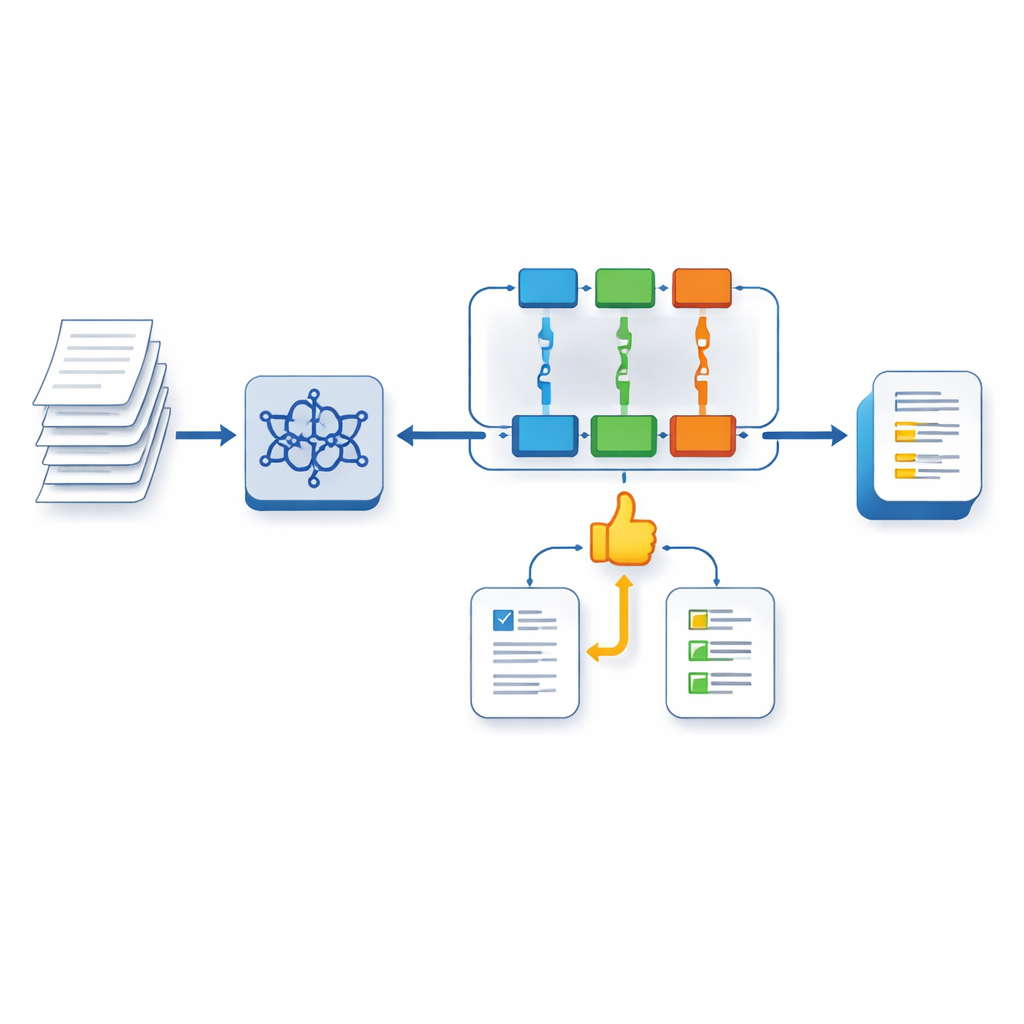
教会 AI 重视高质量反馈
第二步,作者训练了一个独立的奖励模型,该模型通过比较模型生成的评论与教师撰写的评论来学习评估反馈本身的质量。该奖励模型在训练中充当人工评分员的替代。第三步,使用一种称为 PPO 的强化学习方法对主系统进行进一步优化。在此过程中,模型生成反馈,奖励模型对该反馈与专家偏好的一致性进行评分,系统在多轮迭代中调整行为,以朝着更高质量、更接近评分员风格的回应方向改进。
对学习者与教师的意义
测试结果显示,新系统在与人工评分的一致性上优于包括各种提示方式下的 GPT‑4 在内的强劲替代方案,并产生了在自动度量和人工评审中更接近专家评论的反馈。尽管评分准确性的数值提升有限,系统的真正优势在于提供详尽、基于评分细则且个性化的建议,类似于一位经验丰富教师可能写出的评语。对雅思考生而言,这种方法指向一种负担得起、随时可用的写作支持,它不仅给出分数,还解释原因并指导下一步如何改进。
引用: Xu, W., Kassim, M.S.S. & Mahmud, R. Enhancing IELTS writing automated scoring with M-LoRA fine-tuned LLAMA-3 and human feedback-driven PPO reinforcement learning. Sci Rep 16, 10865 (2026). https://doi.org/10.1038/s41598-026-43318-w
关键词: 自动作文评分, 雅思写作, 大型语言模型, 教学反馈, 强化学习