Clear Sky Science · he
שיפור הדירוג האוטומטי של החיבור ב‑IELTS באמצעות M‑LoRA שמותאם ל‑LLAMA‑3 ולמידת חיזוק PPO המונחית על‑ידי משוב אנושי
מדוע סיוע חכם יותר בכתיבה משמעותי
בשנה, מבחן ה‑IELTS פותח דלתות ללימודים, לעבודה או להגירה לחו"ל עבור מיליונים. עם זאת, רבים מהמבחנים נתקלים בקשיים בעיקר בחלק הכתיבה, שבו קבלת משוב ברור ואמין קשה ולעתים יקרה כשמסתמכים על מורים אנושיים. מאמר זה חוקר גישה חדשה לשימוש בבינה מלאכותית לא רק לציון חיבורים ב‑IELTS, אלא גם למתן הצעות מפורטות בדומה לאדם שעוזרות לכותבים להשתפר בפועל, תוך שמירה על התאמה קרובה לאופן שבו בוחנים אמיתיים שופטים.

האתגר בהערכת כתיבה
הערכת איכות חיבור מורכבת יותר מבדיקת איות או ספירת מילים. בוחנים אנושיים בוחנים עד כמה הכותב עונה על השאלה, עד כמה הרעיונות מאורגנים בבירור, כמה העושר והדיוק של אוצר המילים, וכמה נכונה ומגוונת הדקדוק. מערכות דירוג אוטומטיות קיימות לעתים עובדות היטב רק על מערכי שאלות צרים וקבועים ועלולות "לשכוח" איך להעריך סוגי חיבורים ישנים כשהן נחשפות לחדשים. מודלים שפתיים גדולים כגון GPT‑4 הראו פוטנציאל, אך בשימוש ישיר הם עדיין מתקשים להתאים לציוני אנוש ונוטים לתת משוב כללי ואחיד.
בניית מאגר נתוני כתיבת IELTS עשיר
כדי להתגבר על מגבלות אלה, הכותבים יצרו תחילה מאגר נתונים פרטי חדש של 5,088 חיבורים אמיתיים למטלה 2 ב‑IELTS שנכתבו על ידי לומדים סיניים. לכל חיבור צורפו ציונים ממורים מנוסים ב‑IELTS על ארבעת הקריטריונים הרשמיים: מענה למשימה, קוהרנטיות וקוהזיה, משאבי לקסיקליים, והיקף ודיוק דקדוקי. חשוב מכך, המורים סיפקו גם משוב עד רמת פירוט קטנה שהצביע על בעיות כמו רעיונות לא ברורים, קישורים מסורבלים בין משפטים או אוצר מילים חלש, וכן הצעות ניסוח מחודשות. האנוטציה העשירה הזו חורגת בהרבה ממאגרי נתונים ציבוריים טיפוסיים ומהווה את הבסיס לאימון ולבדיקת המערכת החדשה.
מאמן כתיבה חכם בשלושה שלבים
המערכת המוצעת בנויה על LLaMA‑3, מודל שפתי גדול מודרני, המשודרג באמצעות שיטת כיוונון קלה בשם Multi‑task LoRA. בשלב הראשון, המודל מאומן להתמודד עם מספר משימות במקביל: עבור כל חיבור הוא חוזה ציון רצועה לכל אחד מהארבעה קריטריונים ומייצר תגובות ממוקדות לכל תחום. "ראשים" נפרדים מתמקדים בכל תכונה, תוך שיתוף הבנה משותפת של הטקסט, דבר המסייע למודל להימנע מ"שכחה קטסטרופלית" בדרך כלל כאשר הוא מתמודד עם פקודות רבות ושונות.
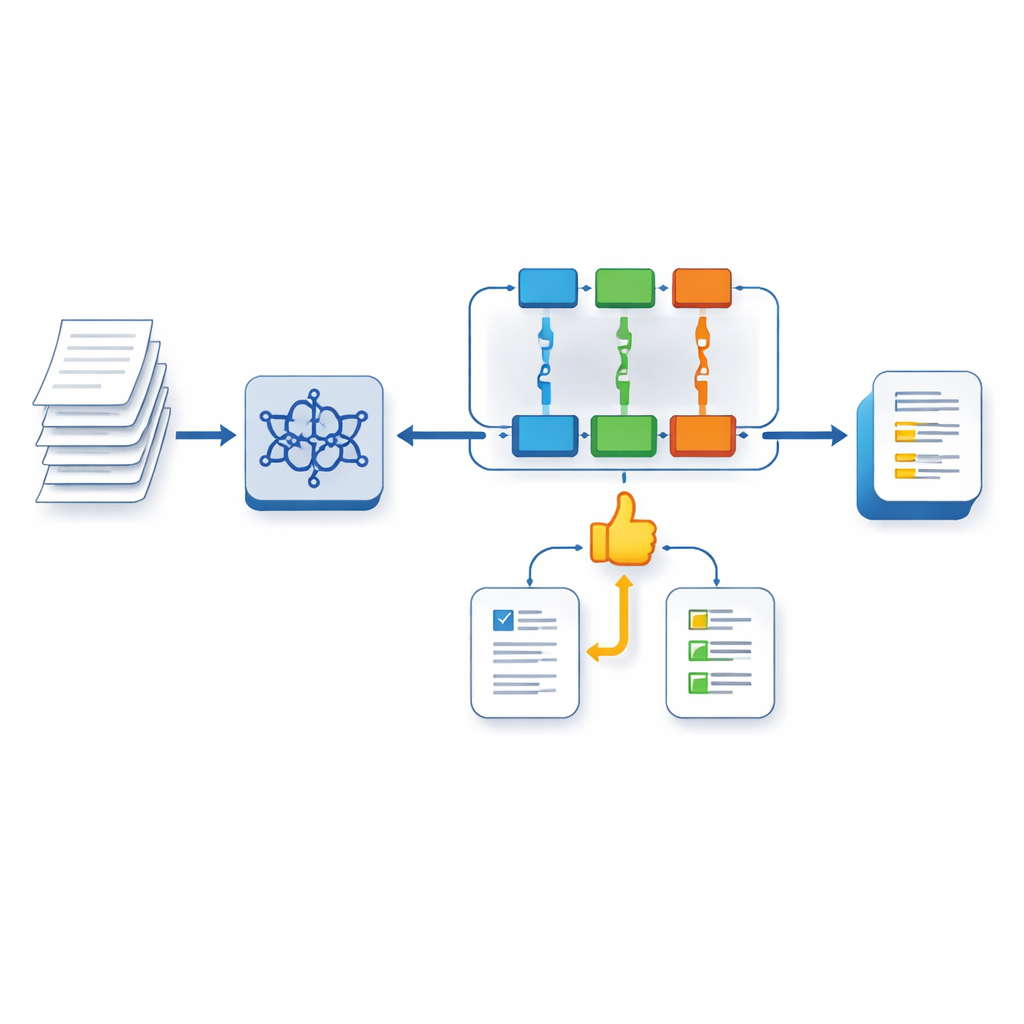
ללמד את ה‑AI להעריך משוב טוב
בשלב השני, הכותבים מאמנים מודל תגמול נפרד שלומד לשפוט את איכות המשוב עצמו על‑ידי השוואת תגובות שנוצרו על‑ידי המודל לאלו שנכתבו על‑ידי המורים. מודל התגמול הזה משמש כתחליף לבוחנים אנושיים במהלך האימון. בשלב השלישי, המערכת הראשית משופרת עוד באמצעות שיטת למידת חיזוק הידועה בשם PPO. כאן המודל מייצר משוב, מודל התגמול נותן ציון עד כמה המשוב הזה תואם להעדפות המומחים, והמערכת משנה את התנהגותה כדי להתקרב לתגובות איכותיות יותר המזכירות יותר את סגנון הבוחנים על פני מחזורים רבים.
מה המשמעות של התוצאות ללומדים ולמורים
במבחנים, המערכת החדשה השיגה התאמה גבוהה יותר עם ציוני אנוש לעומת חלופות חזקות, כולל GPT‑4 עם דרכים שונות של הנחיה, ויצרה משוב שמדדים אוטומטיים ושופטים אנושיים מצאו קרוב יותר להערות המומחים. בעוד שהשיפורים המספריים בדיוק הציונים צנועים, החוזק האמיתי של המערכת טמון במתן ייעוץ מפורט, מבוסס קריטריונים ואישי, הדומה למה שמורה מיומן עשוי לכתוב. עבור מועמדי IELTS, גישה זו מצביעה על אפשרות לקבלת סיוע בכתיבה זול וזמין בכל עת שעושה יותר מאשר להקצות ציון — היא מסבירה מדוע ואיך להשתפר בפעם הבאה.
ציטוט: Xu, W., Kassim, M.S.S. & Mahmud, R. Enhancing IELTS writing automated scoring with M-LoRA fine-tuned LLAMA-3 and human feedback-driven PPO reinforcement learning. Sci Rep 16, 10865 (2026). https://doi.org/10.1038/s41598-026-43318-w
מילות מפתח: דירוג מאמרים אוטומטי, כתיבה ב‑IELTS, מודלים שפתיים גדולים, משוב חינוכי, למידת חיזוק