Clear Sky Science · ar
تعزيز الدرجات الآلية لكتابة اختبار IELTS باستخدام M-LoRA لضبط LLAMA-3 وتعلّم التعزيز PPO المدفوع بتغذية راجعة بشرية
لماذا تهم المساعدة الأذكى في كتابة المقالات
لملايين الأشخاص كل عام، يمكن لاختبار IELTS أن يفتح أبواباً للدراسة أو العمل أو الهجرة إلى الخارج. ومع ذلك، يواجه كثير من المتقدمين صعوبات أكبر في قسم الكتابة، حيث يكون الحصول على تغذية راجعة واضحة وموثوقة أمراً صعباً، وقد تكون تكاليف المدرّسين البشريين باهظة. تستكشف هذه الورقة طريقة جديدة لاستخدام الذكاء الاصطناعي ليس فقط لتقييم مقالات IELTS، بل أيضاً لتقديم اقتراحات مفصّلة شبيهة بتلك البشرية تساعد الكتّاب على التحسّن فعلياً، مع المحافظة على توافق وثيق مع كيفية تفكير المقيمين الحقيقيين.

تحدي تقييم الكتابة
تقييم جودة المقال أعقد من مجرد التحقق من الإملاء أو عدّ الكلمات. ينظر المقيمون البشريون إلى مدى إجابة الكاتب على السؤال، ووضوح تنظيم الأفكار، وغنى ودقة المفردات، وصحة وتنوّع القواعد النحوية. غالباً ما تعمل أنظمة التقييم الآلي الموجودة بشكل جيد فقط على مجموعات أسئلة ضيقة وثابتة، وقد «تنسى» كيفية تقييم أنواع مقالات سابقة عند تعرّضها لأنماط جديدة. أظهرت نماذج اللغة الكبيرة مثل GPT-4 وعداً، لكن عند استخدامها مباشرة لا تزال تكافح لمضاهاة درجات البشر وتميل إلى إعطاء تغذية راجعة عامة وموحّدة.
بناء مجموعة بيانات غنية لكتابة IELTS
لدفع الحدود أبعد من ذلك، أنشأ المؤلفون أولاً مجموعة بيانات خاصة جديدة تضم 5,088 مقالة حقيقية من مهمة الكتابة 2 في IELTS كتبها متعلمون صينيون. كل مقالة كانت مصحوبة بدرجات من معلمين ذوي خبرة في IELTS على المعايير الرسمية الأربعة: الاستجابة للمهمة، التماسك والتماسك الداخلي، مصادر المفردات، ومدى تنوّع وصحة القواعد النحوية. والأهم أن المعلمين قدّموا أيضاً تغذية راجعة مفصّلة تشير إلى مشكلات مثل الأفكار غير الواضحة، الروابط المحرجة بين الجمل، أو المفردات الضعيفة، إلى جانب اقتراحات لإعادة الصياغة. تتجاوز هذه التعليقات الغنية ما توفره مجموعات البيانات العامة النموذجية وتشكّل أساساً لتدريب واختبار النظام الجديد.
مدرّب كتابة ذكي من ثلاث خطوات
النظام المقترح مبني على LLaMA‑3، وهو نموذج لغة كبير حديث، مُحسّن باستخدام طريقة ضبط خفيفة تُسمى Multi‑task LoRA. في الخطوة الأولى، يتم تدريب النموذج للتعامل مع عدة مهام في آن واحد: لأي مقالة، يتنبأ بدرجة (band score) لكل من المعايير الأربعة ويولد تعليقات مستهدفة لكل مجال. تركز «رؤوس» منفصلة على كل سمة، مع مشاركة فهم مشترك للنص، مما يساعد النموذج على تجنّب مشكلة «النسيان الكارثي» المعتادة عند مواجهة مطالبات متنوعة.
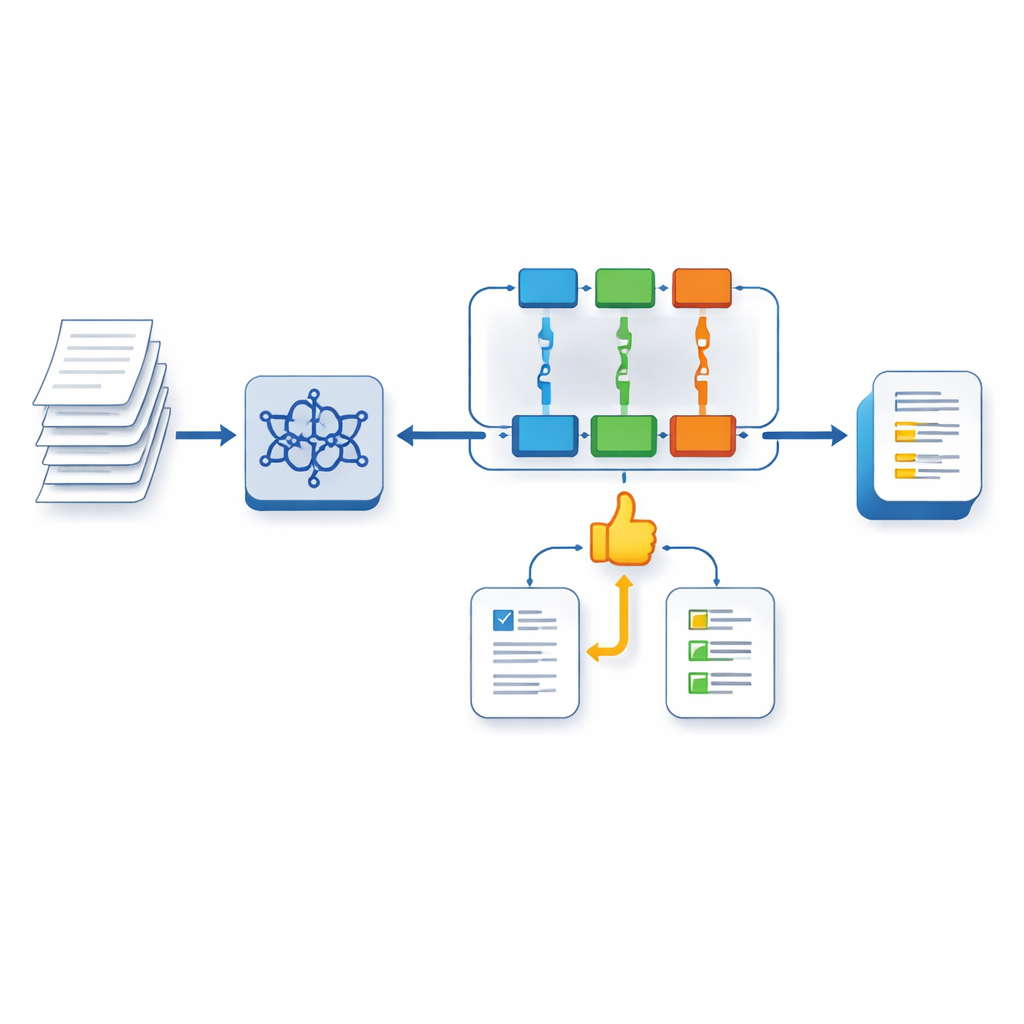
تعليم الذكاء الاصطناعي قيمة التغذية الراجعة الجيدة
في الخطوة الثانية، يدرب المؤلفون نموذج مكافأة منفصل يتعلّم تقييم جودة التغذية الراجعة نفسها بمقارنة التعليقات المولَّدة آلياً مع التعليقات المكتوبة من المعلمين. يعمل هذا النموذج كممثل عن المقيمين البشريين أثناء التدريب. في الخطوة الثالثة، يتم تنقية النظام الرئيسي أكثر باستخدام طريقة تعلّم تعزيز تعرف باسم PPO. هنا، يولّد النموذج تغذية راجعة، ويقيّم نموذج المكافأة مدى توافق تلك التغذية الراجعة مع تفضيلات الخبراء، ويعدّل النظام سلوكه نحو استجابات أعلى جودة وأكثر شبيهة بملاحظات المقيمين عبر دورات تدريبية متعددة.
ماذا تعني النتائج للمتعلمين والمدرّسين
عند الاختبار، حقق النظام الجديد توافقاً أعلى مع درجات البشر مقارنة ببدائل قوية، بما في ذلك GPT‑4 الموجه بطرق متعددة، وأنتج تغذية راجعة وجدتها مقاييس آلية ومقيّمون بشريون أقرب للتعليقات الخبيرة. وعلى الرغم من أن المكاسب الرقمية في دقة التقييم متواضعة، تكمن القوة الحقيقية للنظام في تقديم نصائح مفصّلة قائمة على جداول التقييم وشخصية تشبه ما قد يكتبه مدرس ماهر. بالنسبة لمرشحي IELTS، يشير هذا النهج إلى دعم كتابي ميسور ومتوافر دائماً يتجاوز مجرد إعطاء درجة—فهو يشرح السبب وكيفية التحسّن في المرة القادمة.
الاستشهاد: Xu, W., Kassim, M.S.S. & Mahmud, R. Enhancing IELTS writing automated scoring with M-LoRA fine-tuned LLAMA-3 and human feedback-driven PPO reinforcement learning. Sci Rep 16, 10865 (2026). https://doi.org/10.1038/s41598-026-43318-w
الكلمات المفتاحية: تقييم المقالات الآلي, كتابة IELTS, نماذج اللغة الكبيرة, التغذية الراجعة التعليمية, تعلّم التعزيز