Clear Sky Science · zh
基于RAG的架构:使用紧凑型大模型检索药物不良反应
这对日常医疗为何重要
任何拿到新处方的人大概都会想:“这颗药会不会导致我的头痛或皮疹?”医生和病人每天都要面对成千上万次类似的疑问,但答案散落在厚重的手册和数据库中。这项研究探讨了如何让更小、更高效的人工智能系统调用已有的药物不良反应目录,提供快速、精确且有证据依据的回答——并避免编造信息。

追踪药物不良反应的挑战
药物不良反应是全球发病、就诊甚至死亡的重要原因。新药出现的速度远快于临床医生记住其风险的速度,且患者的用药历史日益复杂。传统工具——印刷手册、电子病历和上报系统——功能强大但在繁忙诊室中检索缓慢。大型语言模型,即驱动聊天机器人的那类AI,看似理想,因为它们可以用通俗语言回答问题。然而,当被问到像“这种药会导致这种特定不良反应吗?”这样具体的问题时,即便是现成的超大模型也常常猜测或产生幻觉,给出与最佳证据不符的答案。
教AI去查找信息而不是猜测
作者通过改变AI访问信息的方式而不是简单地把模型做得更大来应对这个问题。他们以一个经整理的资源SIDER为起点,该数据库列出哪些已上市药物与哪些不良反应有关。随后他们构建了两种“开卷”系统,这些系统不是依赖模型在训练期间学到的记忆,而是在提问时显式检索相关事实并将其提供给紧凑型语言模型。在基于文本的方法中,药物-不良反应信息以书面条目形式存储,并使用相似性引擎检索最相关的片段。在名为GraphRAG的图形方法中,每种药物和每种不良反应都是网络中的一个节点,节点之间的连线表示该药物已报告过该不良反应。两种系统的最终步骤都是让小型语言模型给出简单的“是”或“否”答案,并基于仅检索到的证据提供简短解释。
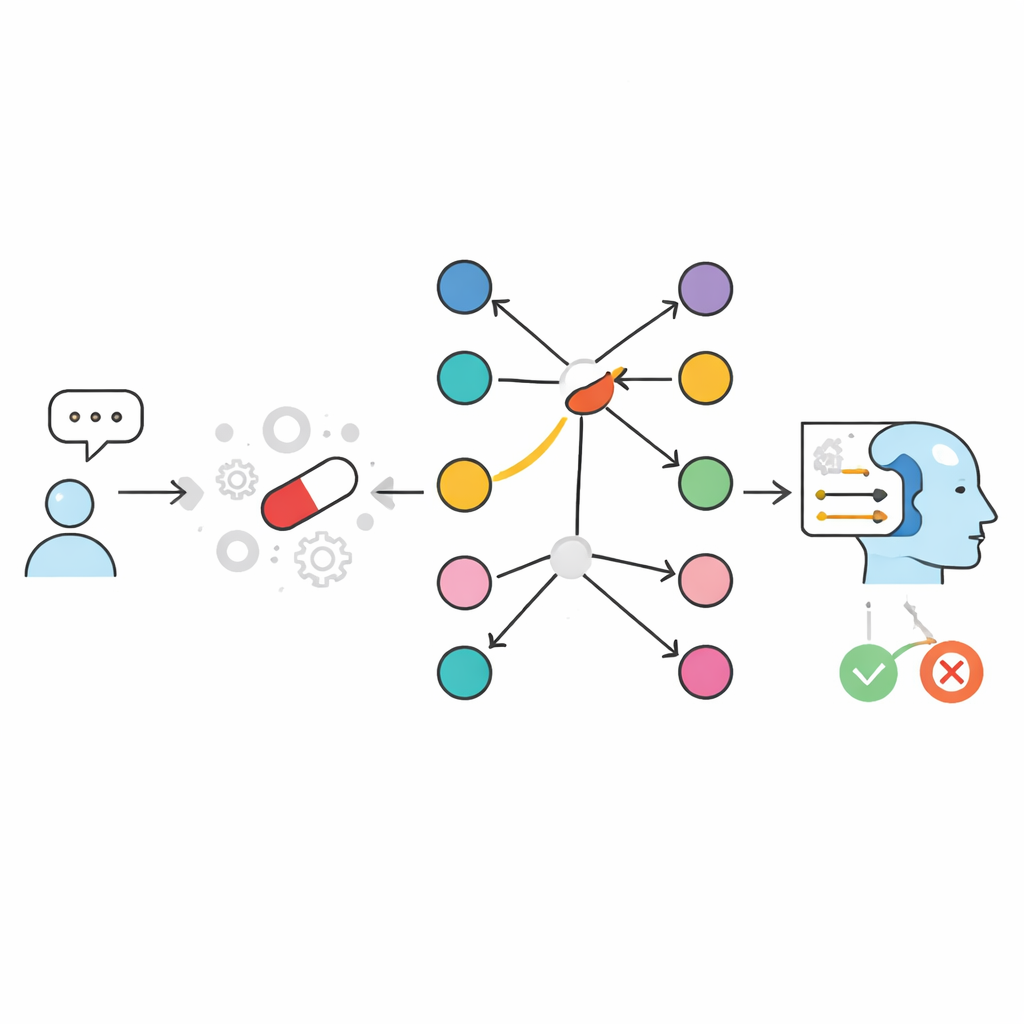
图谱方法如何改变局面
为测试这些设计,团队基于SIDER创建了一个近两万对药物—不良反应的庞大且均衡的基准数据集。对每种药物,他们既包含了已知与之相关的不良反应,也包含未关联的项。单独工作的紧凑型语言模型、没有任何检索时,仅答对约三分之二——与或低于常见的通用聊天机器人。加入检索后,性能跃升。将每个药物—不良反应对存为一句话的文本型设置达到约98–99%的准确率。基于图的GraphRAG表现更佳,几乎达到了完美分数:在几乎所有情况下,如果SIDER中存在连线,系统就回答“是”,如果没有连线则回答“否”。剩余的极少错误来自语言模型最终措辞,而非底层检索本身。
找出导致同一症状的所有药物
作者还考察了临床医生常关心的逆向问题:“哪些药物已知会导致这一具体不良反应?”在这里,系统不是给出单一的是/否,而是必须列出所有匹配的药物。图谱方法再次表现突出。因为它可以从某一不良反应节点直接展开到所有连接的药物节点,所以即使涉及数百种药物,也能在极低延迟下返回精确列表。强效的文本方法也能接近同等的完整性,但需要扫描并拼接许多独立文本片段,因而速度显著较慢。团队还加入了一个小的规范化步骤,使用紧凑型语言模型在检索前纠正药名的常见拼写错误,大幅提高了对现实查询(如将“floxetine”写作而非“fluoxetine”)的鲁棒性。
这对患者和临床医生意味着什么
简言之,这项工作表明,要让AI在药物不良反应问题上更安全,最明智的做法不是单纯构建更大的模型,而是将更小的模型与组织良好的医学知识相连接。通过将已知的药物—不良反应关联表示为简单的图谱,并强制AI基于该结构给出答案,作者几乎消除了目录化关联的猜测成分。结果是一个能快速告诉医生或患者某一报告的症状是否出现在权威不良反应列表中、以及哪些药物与之相关的系统,同时仍能用日常语言解释答案。尽管它不会发现新的不良反应或替代谨慎的临床判断,但这种方法为构建可信赖、可扩展的互动工具提供了实用的基础,帮助人们了解所用药物的风险。
引用: Nygren, S., Erdogan, O., Avci, P. et al. RAG-based architectures for drug side effect retrieval using compact LLMs. Sci Rep 16, 12754 (2026). https://doi.org/10.1038/s41598-026-41495-2
关键词: 药物不良反应, 医学人工智能, 知识图谱, 检索增强生成, 药物监测