Clear Sky Science · nl
RAG-gebaseerde architecturen voor het opzoeken van bijwerkingen met compacte LLM's
Waarom dit ertoe doet in de dagelijkse geneeskunde
Iemand die een nieuw recept heeft gekregen, heeft zich waarschijnlijk wel eens afgevraagd: “Kan dit pilletje mijn hoofdpijn of uitslag veroorzaken?” Artsen en patiënten krijgen die vraag duizenden keren per dag, maar de antwoorden zitten verstopt in dikke handboeken en databases. Deze studie onderzoekt hoe kleinere, efficiëntere kunstmatige-intelligentiesystemen kunnen putten uit een bestaande catalogus van bekende geneesmiddelbijwerkingen om snel, precies en op bewijs gebaseerde antwoorden te geven — zonder feiten te verzinnen.

De uitdaging van het volgen van bijwerkingen
Bijwerkingen van geneesmiddelen zijn een belangrijke oorzaak van ziekte, ziekenhuisbezoek en zelfs sterfte wereldwijd. Nieuwe medicijnen verschijnen sneller dan drukbezette artsen de risico’s kunnen onthouden, en patiënten hebben steeds complexere behandelgeschiedenissen. Traditionele hulpmiddelen — gedrukte naslagwerken, elektronische medische dossiers en meldingssystemen — zijn krachtig maar traag te doorzoeken in een hectische kliniek. Grote taalmodellen, het type AI achter chatbots, lijken ideaal omdat ze vragen in gewone taal kunnen beantwoorden. Toch gokken deze modellen, zelfs de zeer grote, vaak of hallucineren ze wanneer ze specifieke vragen krijgen zoals “Geeft dit medicijn deze specifieke bijwerking?”, waardoor antwoorden niet overeenkomen met het beste beschikbare bewijs.
AI leren opzoeken in plaats van gissen
De auteurs pakken dit probleem aan door te veranderen hoe AI informatie benadert in plaats van alleen modellen groter te maken. Ze beginnen met een gecureerde bron genaamd SIDER, een database die aangeeft welke op de markt zijnde geneesmiddelen met welke bijwerkingen worden geassocieerd. Vervolgens bouwen ze twee “open-boek”-systemen die, in plaats van te vertrouwen op wat het model tijdens training heeft geleerd, expliciet relevante feiten opzoeken op het moment van de vraag en die aan een compact taalmodel voorleggen. In een tekstgebaseerde aanpak wordt informatie over geneesmiddel–bijwerking als geschreven vermeldingen opgeslagen en doorzocht met een gelijkenismotor die de meest relevante fragmenten vindt. In een grafgebaseerde aanpak, GraphRAG genoemd, is elk geneesmiddel en elke bijwerking een knooppunt in een netwerk, en een verbinding ertussen betekent dat die bijwerking voor dat geneesmiddel is gemeld. Beide systemen vragen tenslotte een klein taalmodel om een eenvoudig JA of NEE te geven, plus een korte verklaring die uitsluitend is gebaseerd op het opgehaalde bewijs.
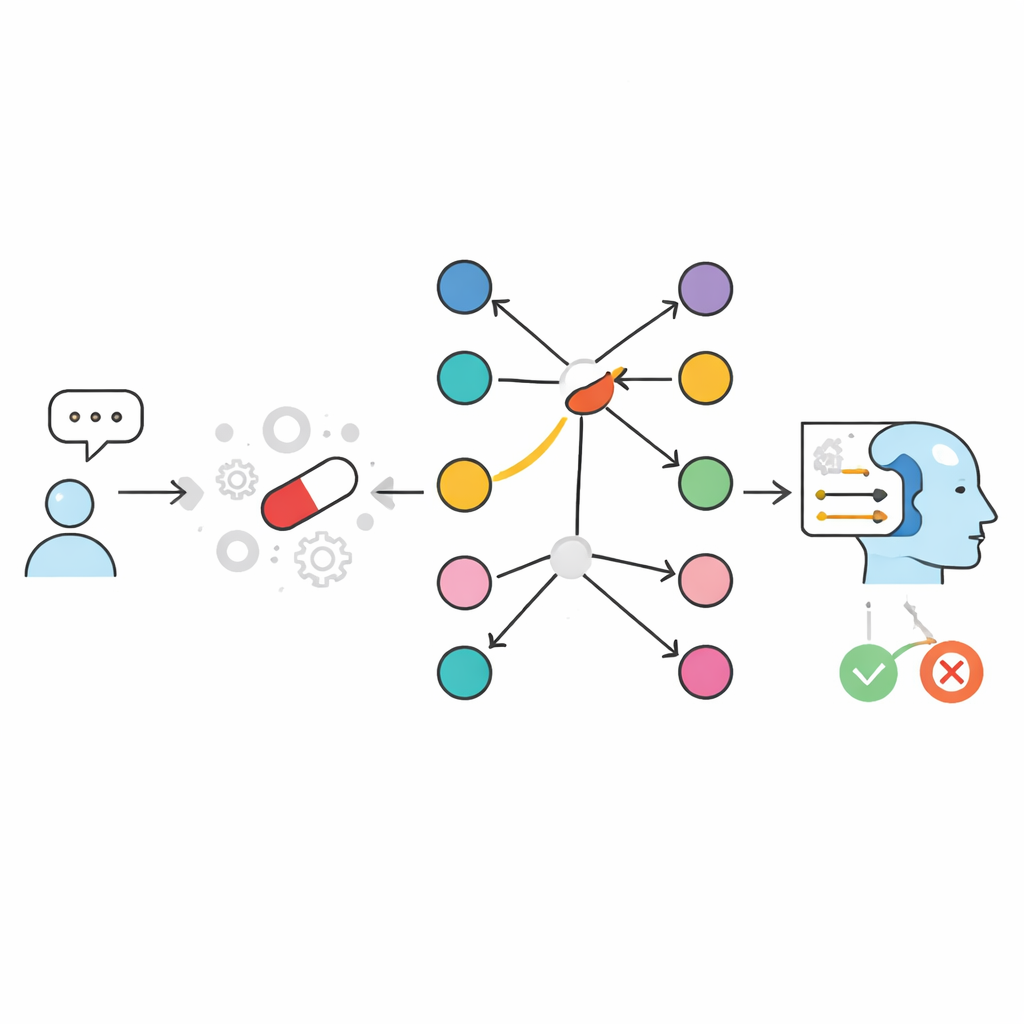
Hoe de grafaanpak het spel verandert
Om deze ontwerpen te testen creëerde het team een grote, gebalanceerde benchmark van bijna twintigduizend geneesmiddel–bijwerkingparen afkomstig uit SIDER. Voor elk geneesmiddel namen ze sommige bijwerkingen op die bekend waren als gekoppeld eraan en andere die dat niet waren. Compacte taalmodellen die op zichzelf werkten, zonder enige lookup, hadden slechts ongeveer twee derde van de antwoorden goed — vergelijkbaar met of slechter dan populaire algemene chatbots. Zodra retrieval werd toegevoegd, steeg de prestatie aanzienlijk. Een tekstgebaseerde opzet die één zin per geneesmiddel–bijwerkingspaar opsloeg bereikte rond de 98–99% nauwkeurigheid. De grafgebaseerde GraphRAG ging nog verder en behaalde nagenoeg perfecte scores: in bijna elk geval, als de verbinding in SIDER bestond, antwoordde het systeem JA, en als die er niet was, was het antwoord NEE. De weinige resterende fouten kwamen door de uiteindelijke formulering van het taalmodel, niet door de onderliggende zoekopdracht.
Alle geneesmiddelen vinden achter één symptoom
De auteurs onderzochten ook de omgekeerde vraag die clinici vaak belangrijk vinden: “Welke geneesmiddelen staan er bekend om deze specifieke bijwerking te veroorzaken?” Hier moet het systeem, in plaats van een enkele ja/nee-beslissing, alle bijpassende geneesmiddelen opsommen. Ook hier blonk de grafgebaseerde aanpak uit. Omdat die simpelweg uitbreidt vanaf een gegeven bijwerkingsknooppunt naar alle verbonden geneesmiddelknooppunten, levert het de exacte lijst terug met zeer lage latency, zelfs wanneer honderden geneesmiddelen betrokken zijn. Een sterke tekstgebaseerde methode kon eenzelfde volledigheid benaderen, maar alleen door veel afzonderlijke tekstfragmenten te scannen en samen te voegen, wat het dramatisch trager maakte. Het team voegde verder een kleine normalisatiestap toe die een compact taalmodel gebruikt om veelvoorkomende spelfouten van geneesmiddelnamen te corrigeren vóór de lookup, wat de robuustheid voor echte zoekopdrachten zoals “floxetine” in plaats van “fluoxetine” sterk verbeterde.
Wat dit betekent voor patiënten en clinici
In eenvoudige bewoordingen laat dit werk zien dat de slimste manier om AI veiliger te maken voor vragen over geneesmiddelbijwerkingen niet per se is om steeds grotere modellen te bouwen, maar om kleinere modellen te koppelen aan goed georganiseerde medische kennis. Door bekende geneesmiddel–bijwerkingskoppelingen als een eenvoudige graaf te representeren en de AI te dwingen zijn antwoorden op die structuur te baseren, kunnen de auteurs het giswerk voor gecatalogiseerde associaties vrijwel elimineren. Het resultaat is een systeem dat snel aan een arts of patiënt kan aangeven of een gemeld symptoom voorkomt in een gezaghebbende bijwerkinglijst en welke geneesmiddelen ermee zijn verbonden, terwijl het antwoord in alledaagse taal wordt toegelicht. Hoewel het geen nieuwe bijwerkingen ontdekt of zorgvuldige klinische oordeelsvorming vervangt, biedt deze aanpak een praktische, schaalbare basis voor betrouwbare, interactieve tools die mensen helpen de risico’s van de medicijnen die ze gebruiken beter te begrijpen.
Bronvermelding: Nygren, S., Erdogan, O., Avci, P. et al. RAG-based architectures for drug side effect retrieval using compact LLMs. Sci Rep 16, 12754 (2026). https://doi.org/10.1038/s41598-026-41495-2
Trefwoorden: geneesmiddelbijwerkingen, medische AI, kennisgrafen, retrieval-augmented generation, farmacovigilantie