Clear Sky Science · sv
RAG-baserade arkitekturer för att hämta läkemedelsbiverkningar med kompakta LLM:er
Varför detta är viktigt för vardagsmedicin
Någon som fått ett nytt recept har förmodligen undrat: ”Kan den här tabletten orsaka mitt huvudvärk eller utslag?” Läkare och patienter ställs inför samma fråga tusentals gånger varje dag, men svaren är dolda i tunga handböcker och databaser. Denna studie undersöker hur mindre, mer effektiva artificiella intelligenssystem kan utnyttja en befintlig katalog över kända läkemedelsbiverkningar för att ge snabba, precisa och evidensbaserade svar—utan att hitta på fakta.

Utmaningen att spåra läkemedelsbiverkningar
Läkemedelsbiverkningar är en stor orsak till sjukdom, akutta sjukhusbesök och till och med dödsfall världen över. Nya läkemedel dyker upp snabbare än vad upptagna kliniker kan memorera deras risker, och patienter kommer allt oftare med komplicerade behandlingshistoriker. Traditionella verktyg—tryckta manualer, elektroniska journaler och rapporteringssystem—är kraftfulla men långsamma att söka i en hektisk klinik. Stora språkmodeller, den typ av AI som ligger bakom chattrobotar, verkar idealiska eftersom de kan svara på frågor på vardagligt språk. Ändå, när man ställer specifika frågor som ”Orsakar detta läkemedel denna särskilda biverkning?”, tenderar standardmodeller, även mycket stora sådana, ofta att gissa eller hallucinera och ge svar som inte stämmer överens med bästa tillgängliga evidens.
Att lära AI att slå upp fakta istället för att gissa
Författarna angriper problemet genom att förändra hur AI når information i stället för att enbart göra modellerna större. De utgår från en kurerad resurs kallad SIDER, en databas som listar vilka marknadsförda läkemedel som är kända för att vara förknippade med vilka biverkningar. De bygger sedan två ”öppen-bok”-system som, istället för att förlita sig på vad modellen lärde sig vid träning, uttryckligen söker upp relevanta fakta vid frågetillfället och matar dem till en kompakt språkmodell. I ett textbaserat tillvägagångssätt lagras information om läkemedel–biverkningar som skrivna poster och söks med en likhetsmotor som hittar de mest relevanta utdragen. I ett grafbaserat tillvägagångssätt kallat GraphRAG är varje läkemedel och varje biverkning en nod i ett nätverk, och en länk mellan dem betyder att biverkningen har rapporterats för det läkemedlet. Båda systemen avslutar med att be en liten språkmodell producera ett enkelt JA eller NEJ-svar, plus en kort förklaring som enbart baseras på den hämtade evidensen.
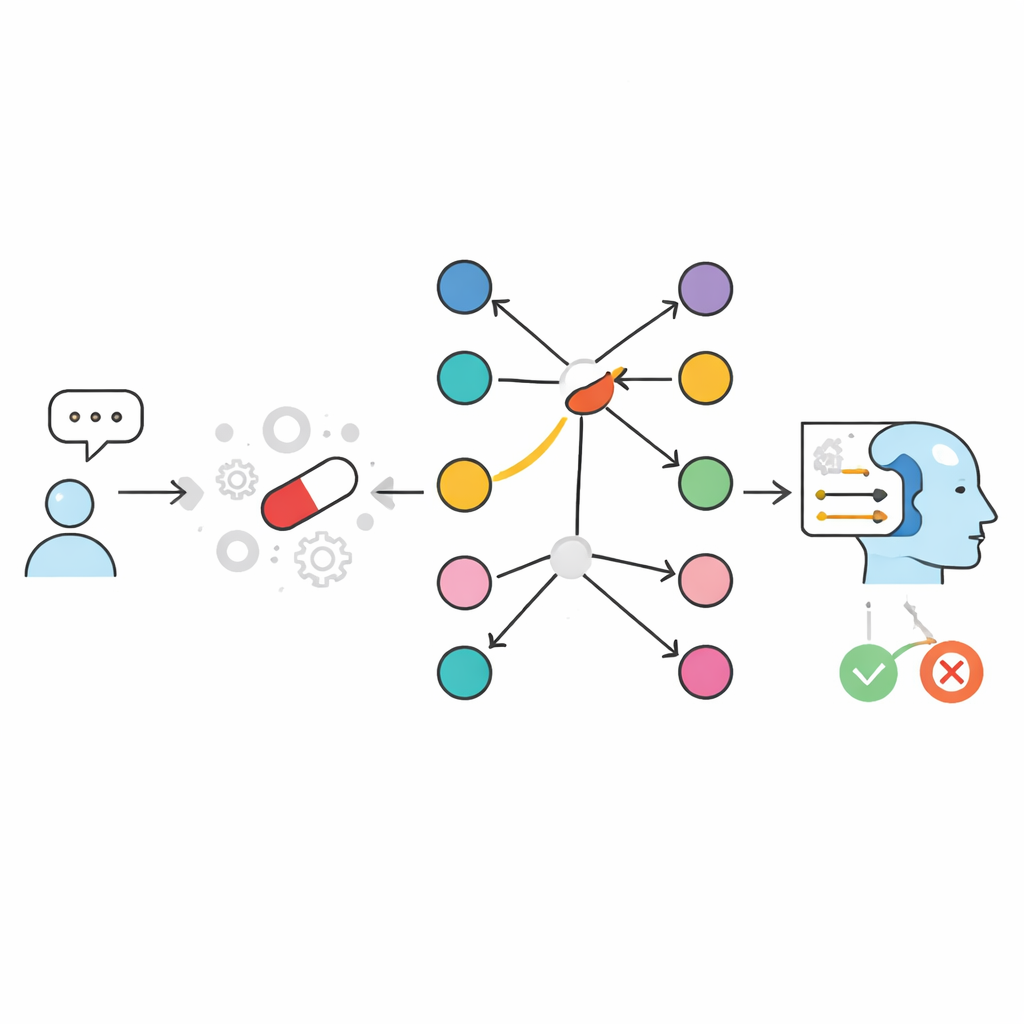
Hur grafmetoden ändrar spelreglerna
För att testa dessa utformningar skapade teamet ett stort, balanserat benchmark med nästan tjugo tusen läkemedel–biverkningspar hämtade från SIDER. För varje läkemedel inkluderade de några biverkningar som var kända för att vara kopplade till det och andra som inte var det. Kompakta språkmodeller som arbetade ensamma, utan någon uppslagning, fick bara ungefär två tredjedelar av svaren rätt—liknande eller sämre än populära allmänna chattrobotar. När uppslagning lades till ökade prestandan kraftigt. En textbaserad inställning som lagrade en mening per läkemedel–biverkningspar nådde omkring 98–99 % noggrannhet. Den grafbaserade GraphRAG gick ännu längre och nådde i princip perfekta resultat: i nästan varje fall, om länken fanns i SIDER svarade systemet JA, och om den inte fanns var svaret NEJ. De få återstående felen kom från språkmodellens slutliga formulering, inte från själva uppslagsinformationen.
Hitta alla läkemedel bakom ett symptom
Författarna undersökte också den omvända frågan som kliniker ofta bryr sig om: ”Vilka läkemedel är kända för att orsaka denna specifika biverkning?” Här, i stället för ett enda ja/nej-beslut, måste systemet lista alla matchande läkemedel. Återigen utmärkte sig grafmetoden. Eftersom den helt enkelt expanderar ut från en given biverknadsnod till alla anslutna läkemedelsnoder returnerar den den exakta listan med mycket låg latens, även när hundratals läkemedel är inblandade. En stark textbaserad metod kunde närma sig samma fullständighet, men endast genom att skanna och sammanställa många separata textstycken, vilket gjorde den dramatiskt långsammare. Teamet lade dessutom till ett litet normaliseringssteg som använder en kompakt språkmodell för att korrigera vanliga stavfel i läkemedelsnamn före uppslagningen, vilket kraftigt förbättrade robustheten för verkliga frågor som ”floxetine” istället för ”fluoxetine”.
Vad detta betyder för patienter och kliniker
Enkelt uttryckt visar detta arbete att det smartaste sättet att göra AI säkrare för frågor om läkemedelsbiverkningar inte bara är att bygga allt större modeller, utan att koppla mindre modeller till välorganiserad medicinsk kunskap. Genom att representera kända läkemedels–biverkningskopplingar som en enkel graf och tvinga AI:n att basera sina svar på den strukturen kan författarna i praktiken eliminera gissningar för katalogiserade associationer. Resultatet är ett system som snabbt kan tala om för en läkare eller patient huruvida ett rapporterat symtom återfinns i en auktoritativ biverkningslista och vilka läkemedel som är kopplade till det, samtidigt som det förklarar svaret på vardagligt språk. Även om det inte upptäcker nya biverkningar eller ersätter noggrant kliniskt omdöme, erbjuder detta tillvägagångssätt en praktisk, skalbar grund för pålitliga, interaktiva verktyg som hjälper människor att navigera riskerna med de läkemedel de använder.
Citering: Nygren, S., Erdogan, O., Avci, P. et al. RAG-based architectures for drug side effect retrieval using compact LLMs. Sci Rep 16, 12754 (2026). https://doi.org/10.1038/s41598-026-41495-2
Nyckelord: läkemedelsbiverkningar, medicinsk AI, kunskapsgrafer, retrieval-augmented generation, farmakovigilans