Clear Sky Science · pl
Architektury oparte na RAG do wyszukiwania działań niepożądanych leków z użyciem kompaktowych LLM
Dlaczego ma to znaczenie dla medycyny codziennej
Każdy, kto otrzymał nową receptę, zastanawiał się zapewne: „Czy ta tabletka może powodować mój ból głowy lub wysypkę?” Lekarze i pacjenci stają przed tym pytaniem tysiące razy dziennie, ale odpowiedzi są ukryte w gęstych podręcznikach i bazach danych. W tym badaniu zbadano, jak mniejsze, bardziej wydajne systemy sztucznej inteligencji mogą korzystać z istniejącego katalogu znanych działań niepożądanych leków, by dostarczać szybkie, precyzyjne i oparte na dowodach odpowiedzi — bez zmyślania faktów.

Wyzwanie śledzenia działań niepożądanych leków
Działania niepożądane leków są istotną przyczyną chorób, wizyt w szpitalu, a nawet zgonów na całym świecie. Nowe leki pojawiają się szybciej, niż zapracowani klinicyści są w stanie zapamiętać ich ryzyka, a pacjenci coraz częściej trafiają z złożoną historią leczenia. Tradycyjne narzędzia — drukowane podręczniki, elektroniczne dokumentacje medyczne i systemy zgłaszania — są potężne, ale wolne w przeszukiwaniu podczas pracowitej wizyty. Duże modele językowe, takie jak te stojące za chatbotami, wydają się idealne, ponieważ potrafią odpowiadać prostym językiem. Jednak przy zadawaniu konkretnych pytań typu „Czy ten lek powoduje ten konkretny efekt uboczny?” gotowe modele, nawet bardzo duże, często zgadują lub halucynują, podając odpowiedzi niezgodne z najlepszymi dostępnymi dowodami.
Nauczanie AI, by wyszukiwała informacje zamiast zgadywać
Autorzy rozwiązują ten problem, zmieniając sposób dostępu AI do informacji, zamiast tylko powiększać modele. Wychodzą od skatalogowanego zasobu o nazwie SIDER — bazy danych wskazującej, które wprowadzone na rynek leki są powiązane z określonymi działaniami niepożądanymi. Budują następnie dwa systemy „z otwartą książką”, które zamiast polegać na tym, czego model nauczył się podczas treningu, jawnie wyszukują odpowiednie fakty w czasie zadawania pytania i przekazują je do kompaktowego modelu językowego. W podejściu tekstowym informacje o parze lek–działanie niepożądane są przechowywane jako zapisy tekstowe i przeszukiwane przez silnik podobieństwa, który znajduje najbardziej istotne fragmenty. W podejściu grafowym, nazwanym GraphRAG, każdy lek i każde działanie niepożądane to węzeł w sieci, a połączenie między nimi oznacza, że działanie niepożądane zostało zgłoszone dla tego leku. Oba systemy kończą pracę, prosząc mały model językowy o wydanie prostej odpowiedzi TAK lub NIE oraz krótkiego wyjaśnienia opartego wyłącznie na pobranych dowodach.
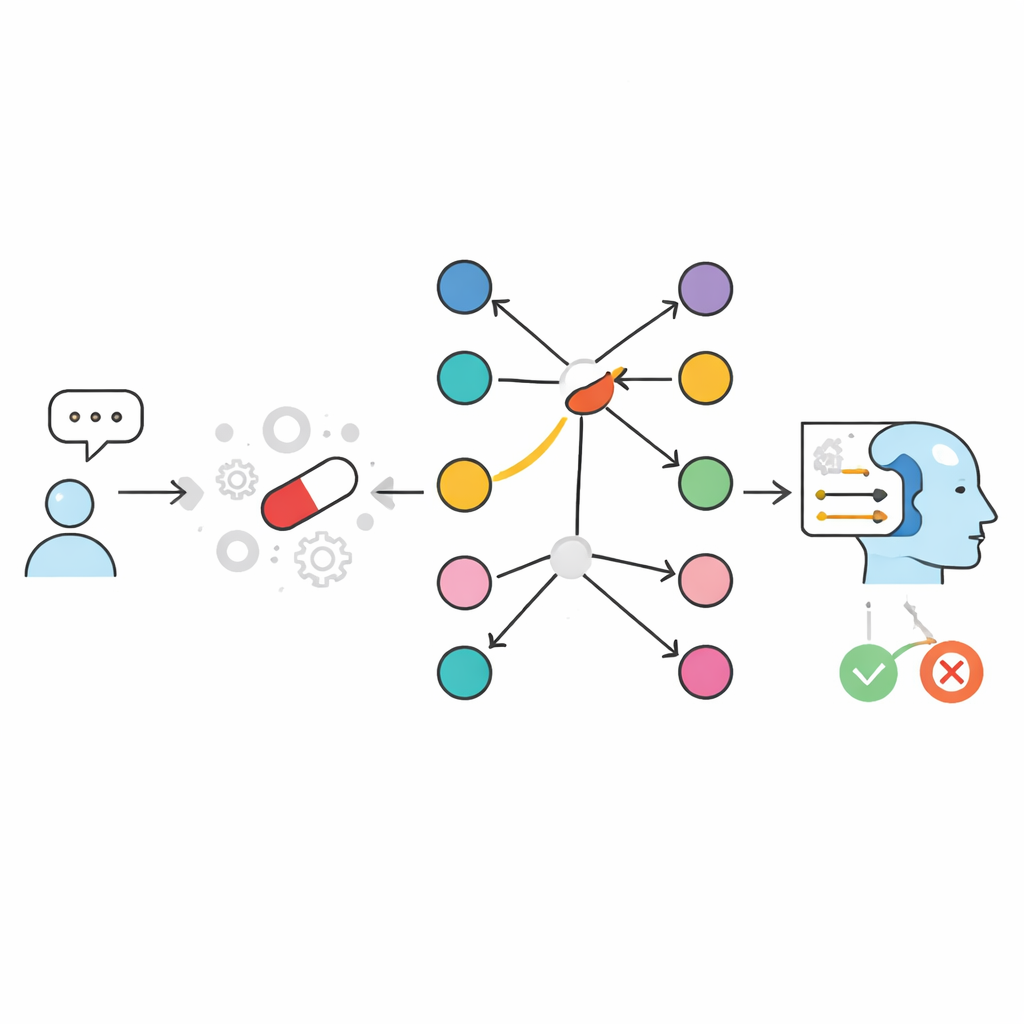
Jak podejście grafowe zmienia zasady gry
Aby przetestować te rozwiązania, zespół stworzył duży, zrównoważony benchmark prawie dwudziestu tysięcy par lek–działanie niepożądane pochodzących z SIDER. Dla każdego leku uwzględniono niektóre działania niepożądane znane jako powiązane z nim oraz inne, które nie były powiązane. Kompaktowe modele językowe działające samodzielnie, bez wyszukiwania, poprawnie odpowiadały tylko w około dwóch trzecich przypadków — podobnie jak lub gorzej niż popularne czatboty ogólnego przeznaczenia. Po dodaniu mechanizmu wyszukiwania wyniki skoczyły. Konfiguracja tekstowa, która przechowywała jedno zdanie na parę lek–działanie niepożądane, osiągnęła około 98–99% trafności. Podejście grafowe GraphRAG posunęło się jeszcze dalej, osiągając praktycznie doskonałe wyniki: niemal we wszystkich przypadkach, jeśli połączenie istniało w SIDER, system odpowiadał TAK, a jeśli nie istniało — NIE. Nieliczne pozostałe błędy wynikały z końcowego sformułowania modelu językowego, a nie z samego wyszukiwania.
Wyszukiwanie wszystkich leków wywołujących dany objaw
Autorzy zbadali także odwrotne pytanie, które często interesuje klinicystów: „Które leki są znane z wywoływania tego konkretnego działania niepożądanego?” Tutaj zamiast pojedynczej decyzji tak/nie system musi wypisać wszystkie pasujące leki. Ponownie wyróżniło się podejście grafowe. Ponieważ po prostu rozszerza się z danego węzła działania niepożądanego do wszystkich powiązanych węzłów leków, zwraca dokładną listę przy bardzo niskim opóźnieniu, nawet gdy zaangażowanych jest setki leków. Silna metoda tekstowa mogłaby osiągnąć podobną kompletność, ale tylko skanując i składając wiele oddzielnych fragmentów tekstu, co czyniło ją dramatycznie wolniejszą. Zespół dodał także mały krok normalizacyjny, w którym kompaktowy model językowy poprawia typowe literówki nazw leków przed wyszukiwaniem, znacznie zwiększając odporność na rzeczywiste zapytania, takie jak „floxetine” zamiast „fluoxetine”.
Co to oznacza dla pacjentów i klinicystów
Mówiąc prosto, ta praca pokazuje, że najinteligentniejszy sposób uczynienia AI bezpieczniejszą w kwestii działań niepożądanych leków to nie tylko budowanie coraz większych modeli, lecz łączenie mniejszych modeli z dobrze zorganizowaną wiedzą medyczną. Reprezentując znane powiązania lek–działanie niepożądane jako prosty graf i zmuszając AI do opierania odpowiedzi na tej strukturze, autorzy niemal eliminują zgadywanie w przypadku skatalogowanych powiązań. Rezultatem jest system, który może szybko powiedzieć lekarzowi lub pacjentowi, czy zgłoszony objaw pojawia się na autorytatywnej liście działań niepożądanych i które leki są z nim powiązane, jednocześnie tłumacząc odpowiedź prostym językiem. Chociaż nie odkrywa nowych działań niepożądanych ani nie zastępuje ostrożnego osądu klinicznego, podejście to zapewnia praktyczną, skalowalną podstawę dla godnych zaufania, interaktywnych narzędzi pomagających ludziom poruszać się w ryzykach związanych z przyjmowanymi lekami.
Cytowanie: Nygren, S., Erdogan, O., Avci, P. et al. RAG-based architectures for drug side effect retrieval using compact LLMs. Sci Rep 16, 12754 (2026). https://doi.org/10.1038/s41598-026-41495-2
Słowa kluczowe: działania niepożądane leków, medyczna sztuczna inteligencja, grafy wiedzy, retrieval-augmented generation, farmakowigilancja