Clear Sky Science · fr
Architectures basées sur RAG pour la recherche d’effets indésirables médicamenteux avec des LLM compacts
Pourquoi cela compte pour la médecine quotidienne
Quiconque a commencé un nouveau traitement s’est probablement demandé : « Est-ce que ce comprimé peut provoquer mon mal de tête ou mon éruption ? » Médecins et patients se posent cette même question des milliers de fois par jour, mais les réponses sont enfouies dans des manuels et des bases de données denses. Cette étude explore comment des systèmes d’intelligence artificielle plus petits et plus efficaces peuvent exploiter un catalogue existant d’effets indésirables connus pour fournir des réponses rapides, précises et fondées sur des preuves—sans inventer d’informations.

Le défi du suivi des effets indésirables médicamenteux
Les effets indésirables des médicaments sont une cause majeure de maladie, d’hospitalisations et même de décès dans le monde. De nouveaux médicaments apparaissent plus vite que les cliniciens surchargés ne peuvent mémoriser leurs risques, et les patients présentent de plus en plus des antécédents de traitements complexes. Les outils traditionnels—manuels imprimés, dossiers médicaux électroniques et systèmes de notification—sont puissants mais lents à consulter dans une clinique agitée. Les grands modèles de langage, ce qui alimente les chatbots, semblent idéaux car ils peuvent répondre en langage courant. Pourtant, lorsqu’on leur pose des questions spécifiques comme « Est-ce que ce médicament provoque cet effet particulier ? », les modèles prêts à l’emploi, y compris les très grands, devinent souvent ou hallucinent, donnant des réponses qui ne correspondent pas aux meilleures preuves disponibles.
Apprendre à l’IA à vérifier l’information plutôt qu’à deviner
Les auteurs abordent ce problème en modifiant la façon dont l’IA accède à l’information plutôt qu’en augmentant simplement la taille des modèles. Ils partent d’une ressource organisée appelée SIDER, une base de données qui répertorie quels médicaments commercialisés sont associés à quels effets indésirables. Ils construisent ensuite deux systèmes « à livre ouvert » qui, au lieu de s’appuyer sur ce que le modèle a appris pendant l’entraînement, recherchent explicitement des faits pertinents au moment de la question et les fournissent à un modèle de langage compact. Dans une approche textuelle, l’information médicament–effet indésirable est stockée sous forme d’entrées écrites et recherchée à l’aide d’un moteur de similarité qui retrouve les extraits les plus pertinents. Dans une approche basée sur un graphe, appelée GraphRAG, chaque médicament et chaque effet indésirable est un nœud d’un réseau, et un lien entre eux signifie que l’effet indésirable a été rapporté pour ce médicament. Les deux systèmes terminent en demandant à un petit modèle de langage de produire une réponse simple OUI ou NON, ainsi qu’une courte explication fondée uniquement sur les preuves récupérées.
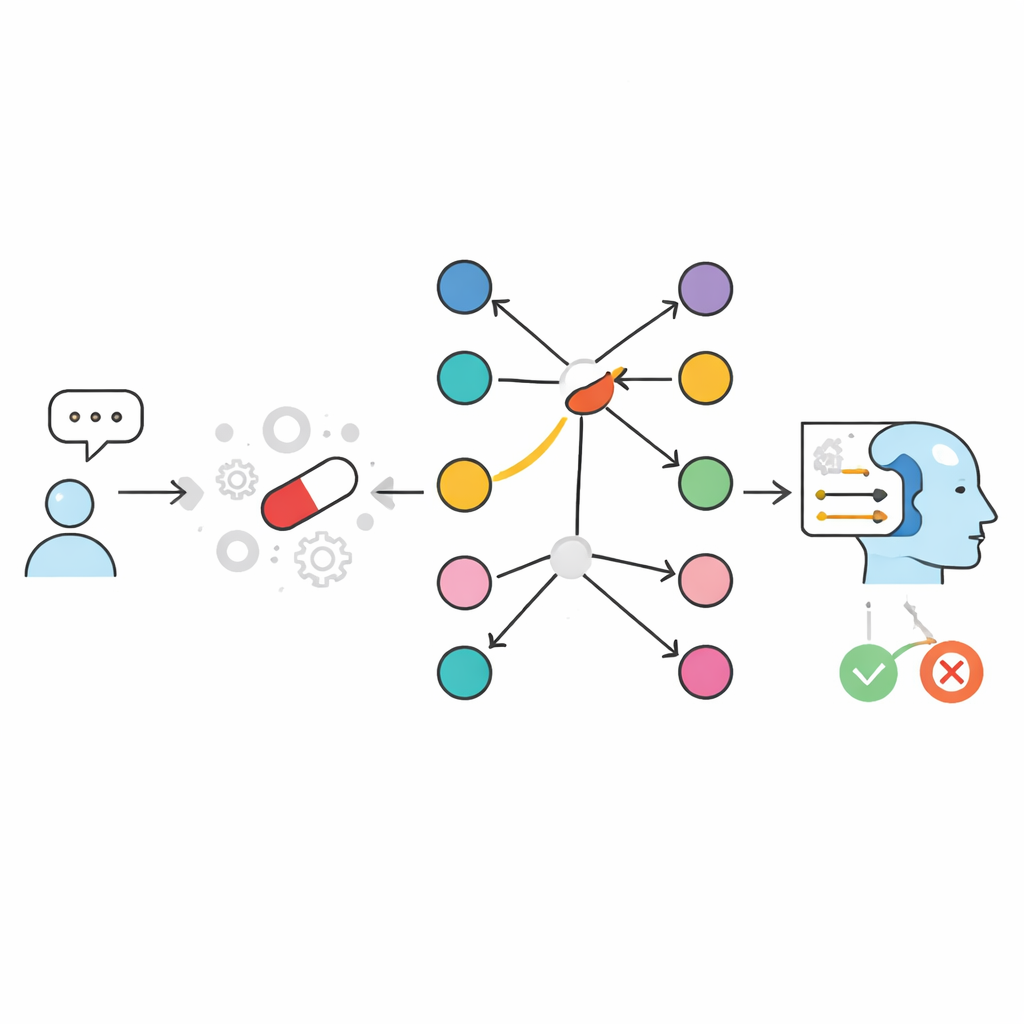
Comment l’approche par graphe change la donne
Pour tester ces conceptions, l’équipe a créé un grand référentiel équilibré d’environ vingt mille paires médicament–effet indésirable dérivées de SIDER. Pour chaque médicament, ils ont inclus certains effets indésirables connus pour être liés et d’autres qui ne l’étaient pas. Les modèles de langage compacts travaillant seuls, sans recherche, n’ont obtenu qu’environ deux tiers des réponses correctes—similaire ou inférieur aux chatbots grand public populaires. Une fois la récupération ajoutée, les performances ont bondi. Une configuration textuelle qui stockait une phrase par paire médicament–effet indésirable a atteint environ 98–99 % de précision. L’approche par graphe GraphRAG est allée encore plus loin, atteignant des scores pratiquement parfaits : dans presque tous les cas, si le lien existait dans SIDER le système répondait OUI, et s’il n’existait pas, la réponse était NON. Les rares erreurs restantes provenaient du libellé final du modèle de langage, et non de la recherche sous-jacente.
Trouver tous les médicaments derrière un symptôme
Les auteurs ont également étudié la question inverse qui intéresse souvent les cliniciens : « Quels médicaments sont connus pour provoquer cet effet indésirable spécifique ? » Ici, au lieu d’une décision binaire, le système doit énumérer tous les médicaments correspondants. Là encore, l’approche par graphe a brillé. Parce qu’elle se contente d’étendre à partir d’un nœud d’effet indésirable donné vers tous les nœuds médicament connectés, elle renvoie la liste exacte avec une très faible latence, même quand des centaines de médicaments sont impliqués. Une méthode textuelle performante pouvait approcher la même exhaustivité, mais seulement en parcourant et en assemblant de nombreux fragments de texte séparés, ce qui la rendait nettement plus lente. L’équipe a en outre ajouté une petite étape de normalisation qui utilise un modèle de langage compact pour corriger les fautes d’orthographe courantes des noms de médicaments avant la recherche, améliorant fortement la robustesse face à des requêtes du monde réel comme « floxetine » au lieu de « fluoxetine ».
Ce que cela signifie pour les patients et les cliniciens
En termes simples, ce travail montre que la meilleure façon de rendre l’IA plus sûre pour les questions sur les effets indésirables médicamenteux n’est pas seulement de construire des modèles toujours plus grands, mais de connecter des modèles plus petits à des connaissances médicales bien organisées. En représentant les liens connus médicament–effet indésirable sous la forme d’un graphe simple et en contraignant l’IA à fonder ses réponses sur cette structure, les auteurs peuvent éliminer pour ainsi dire les conjectures pour les associations répertoriées. Le résultat est un système capable d’indiquer rapidement à un médecin ou à un patient si un symptôme signalé figure dans une liste d’effets indésirables faisant autorité, et quels médicaments y sont liés, tout en expliquant la réponse dans un langage courant. Bien que cela ne découvre pas de nouveaux effets indésirables ni ne remplace le jugement clinique attentif, cette approche offre une base pratique et évolutive pour des outils interactifs dignes de confiance qui aident les personnes à naviguer les risques des médicaments qu’elles utilisent.
Citation: Nygren, S., Erdogan, O., Avci, P. et al. RAG-based architectures for drug side effect retrieval using compact LLMs. Sci Rep 16, 12754 (2026). https://doi.org/10.1038/s41598-026-41495-2
Mots-clés: effets indésirables des médicaments, IA médicale, graphes de connaissances, génération augmentée par récupération, pharmacovigilance