Clear Sky Science · en
RAG-based architectures for drug side effect retrieval using compact LLMs
Why this matters for everyday medicine
Anyone who has picked up a new prescription has probably wondered, “Could this pill be causing my headache or rash?” Doctors and patients face the same question thousands of times a day, but the answers are buried in dense handbooks and databases. This study explores how smaller, more efficient artificial intelligence systems can tap into an existing catalog of known drug side effects to give fast, precise, evidence-based answers—without making things up.

The challenge of tracking drug side effects
Drug side effects are a major cause of illness, hospital visits, and even death worldwide. New medications appear faster than busy clinicians can memorize their risks, and patients increasingly show up with complex treatment histories. Traditional tools—printed manuals, electronic medical records, and reporting systems—are powerful but slow to search in a hectic clinic. Large language models, the kind of AI behind chatbots, seem ideal because they can answer questions in plain language. Yet when asked specific questions like “Does this drug cause this particular side effect?”, off-the-shelf models, including very large ones, often guess or hallucinate, giving answers that do not match the best available evidence.
Teaching AI to look things up instead of guessing
The authors tackle this problem by changing how AI accesses information rather than simply making models bigger. They start from a curated resource called SIDER, a database listing which marketed drugs are known to be associated with which side effects. They then build two “open-book” systems that, instead of relying on whatever the model learned during training, explicitly look up relevant facts at question time and feed them to a compact language model. In a text-based approach, drug–side-effect information is stored as written entries and searched using a similarity engine that finds the most relevant snippets. In a graph-based approach called GraphRAG, each drug and each side effect is a node in a network, and a link between them means the side effect has been reported for that drug. Both systems end by asking a small language model to produce a simple YES or NO answer, plus a short explanation grounded only in the retrieved evidence.
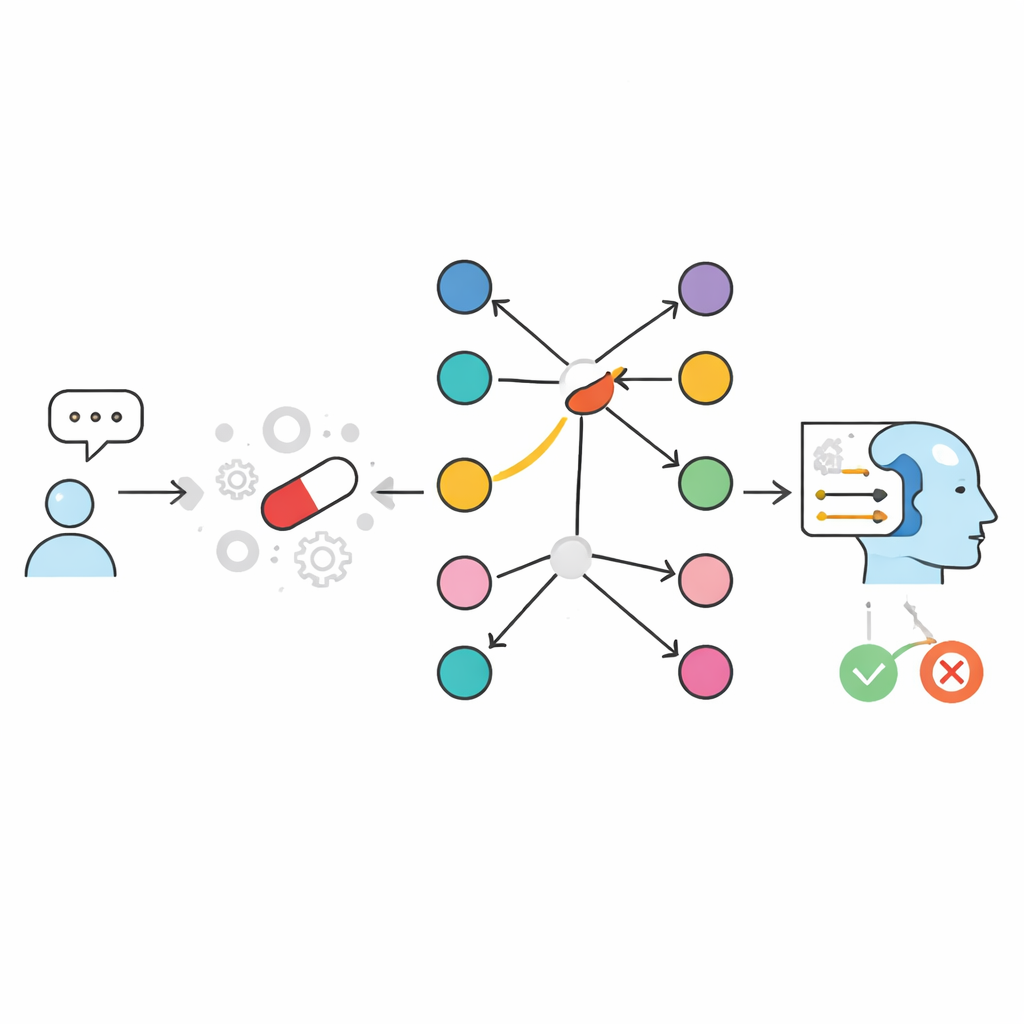
How the graph approach changes the game
To test these designs, the team created a large, balanced benchmark of nearly twenty thousand drug–side-effect pairs derived from SIDER. For each drug, they included some side effects that were known to be linked to it and others that were not. Compact language models working alone, without any lookup, got only about two-thirds of the answers right—similar to or worse than popular general-purpose chatbots. Once retrieval was added, performance jumped. A text-based setup that stored one sentence per drug–side-effect pair reached around 98–99% accuracy. The graph-based GraphRAG went even further, achieving essentially perfect scores: in almost every case, if the link existed in SIDER the system answered YES, and if it did not, the answer was NO. The few remaining errors came from the language model’s final wording, not from the underlying lookup.
Finding all the drugs behind one symptom
The authors also examined the reverse question that clinicians often care about: “Which drugs are known to cause this specific side effect?” Here, instead of a single yes/no decision, the system must list all matching drugs. Again, the graph-based approach shone. Because it simply expands out from a given side-effect node to all connected drug nodes, it returns the exact list at very low latency, even when hundreds of drugs are involved. A strong text-based method could approach the same completeness, but only by scanning and assembling many separate pieces of text, which made it dramatically slower. The team further added a small normalization step that uses a compact language model to correct common misspellings of drug names before the lookup, greatly improving robustness to real-world queries like “floxetine” instead of “fluoxetine.”
What this means for patients and clinicians
In plain terms, this work shows that the smartest way to make AI safer for questions about drug side effects is not just to build ever-larger models, but to connect smaller models to well-organized medical knowledge. By representing known drug–side-effect links as a simple graph and forcing the AI to base its answers on that structure, the authors can all but eliminate guesswork for catalogued associations. The result is a system that can quickly tell a doctor or patient whether a reported symptom appears in an authoritative side-effect list, and which drugs are linked to it, while still explaining the answer in everyday language. Although it does not discover new side effects or replace careful clinical judgment, this approach provides a practical, scalable foundation for trustworthy, interactive tools that help people navigate the risks of the medicines they use.
Citation: Nygren, S., Erdogan, O., Avci, P. et al. RAG-based architectures for drug side effect retrieval using compact LLMs. Sci Rep 16, 12754 (2026). https://doi.org/10.1038/s41598-026-41495-2
Keywords: drug side effects, medical AI, knowledge graphs, retrieval-augmented generation, pharmacovigilance