Clear Sky Science · zh
敏捷软件开发中用于预测分析的智能技术
为何预测软件工作至关重要
任何等待软件修复或新功能的人都了解不知道它何时真正到来的挫折感。在幕后,团队为猜测每项任务需要多长时间而苦恼,这会影响截止日期、预算和客户信任。本文探讨了现代数据驱动方法如何将这些猜测转化为有根据的预测,帮助敏捷软件团队以天为单位规划工作,而不是依赖模糊的“故事点”。 
从粗略猜测到数据驱动的预测
在许多敏捷团队中,工作量估算仍然依赖小组讨论、计划游戏或经验丰富开发者的意见。尽管这些方法很常见,但它们具有主观性:两个团队可能会对同一项工作给出截然不同的估计。早期的研究大多使用私人或付费公司数据,或聚焦于在不同组织间定义各异的特殊单位(如故事点)。这使得跨项目比较结果变得困难,并且几乎不可能让外部人员重现或扩展这些工作。
为敏捷工作建立新的开放窗口
为突破这一壁垒,作者引入了 AgES,这是一个完全由使用敏捷实践的公开 GitHub 项目构建的新开放数据集。AgES 不记录模糊的故事点,而是记录从问题开放到关闭之间的实际天数。每个超过 35,000 条的问题都附带丰富的上下文:谁报告了它、谁参与了处理、吸引了多少评论、以及涉及了哪些标签和组件(例如用户界面、后端或安全)。通过文本处理,团队还推导出更高级别的信息,例如该问题是错误、改进还是新功能,以及每位贡献者在类似工作上的经验程度。
清洗数据以便机器学习
来自真实项目的原始数据往往杂乱:一些问题仍然打开,某些字段缺失,许多细节以自由文本形式出现。研究人员设计了一个细致的清洗和转换管道。他们去除重复或不完整的条目,将文本标签和类别转换为数值形式,并计算诸如贡献者专长等新特征。由于解决时间高度偏斜——大多数问题很快解决,而少数耗时很长——他们应用数学变换和缩放来避免某个因素主导学习过程。其结果是一个精简且格式一致的数据集,计算机可以用它在问题特征与解决所需天数之间识别模式。 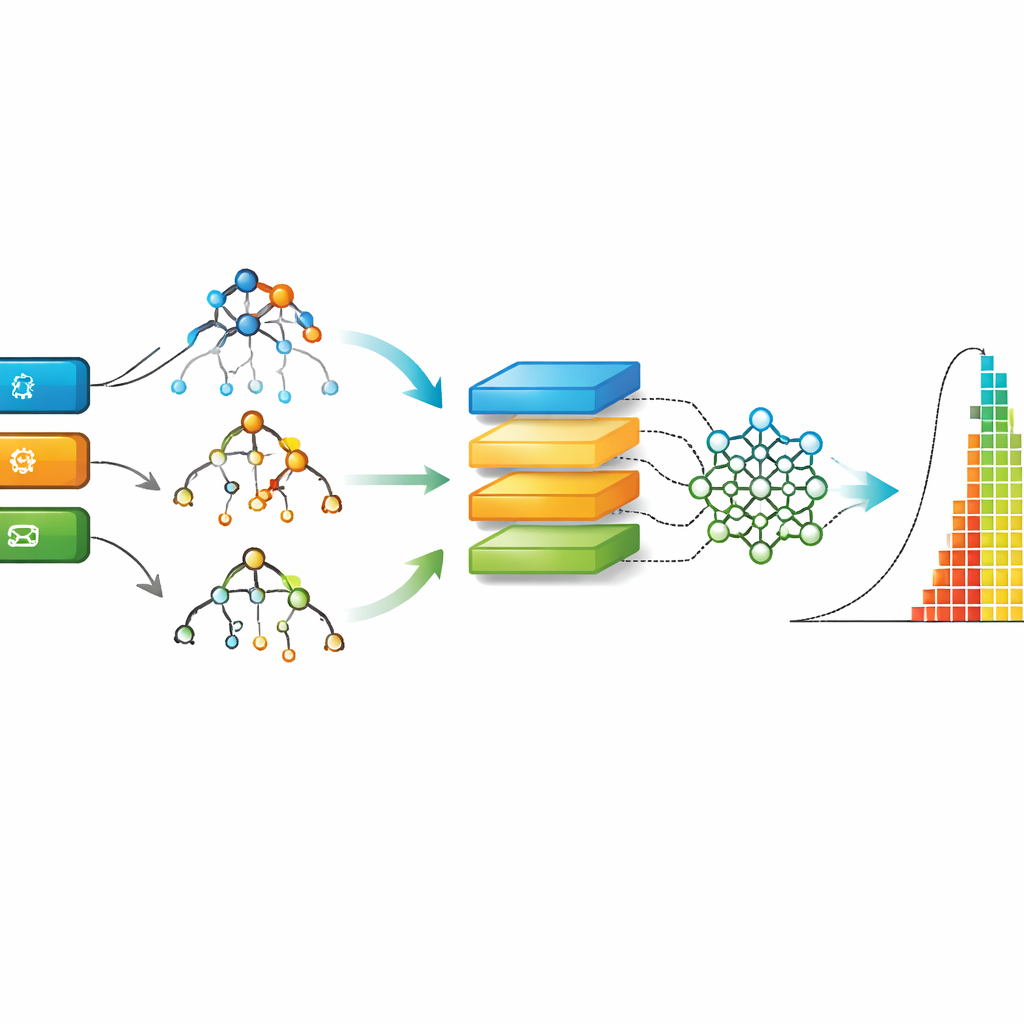
对多种智能方法进行测试
在清洗后的 AgES 数据基础上,作者比较了九种不同的机器学习方法,从经典的决策树与随机森林到循环网络与卷积网络等深度学习模型。每种模型在大部分数据上训练,然后在未见过的问题上测试,性能通过预测与真实解决时间的接近程度来衡量。研究使用了若干标准误差度量来同时捕捉典型错误和罕见但严重的误判。它还将 AgES 与早期工作的两个知名敏捷数据集进行基准对比,展示新数据集和模型的表现如何堆叠比较。
效果最佳的方法及其意义
在所有评估指标上,一种称为极端梯度提升(XGBoost)的方法稳定地在 AgES 数据集上提供最准确的预测。像 XGBoost 和随机森林这样的基于树的方法擅长处理真实世界的表格式数据和缺失值,并能捕捉微妙的非线性关系——例如问题类型、组件与开发者经验的组合如何影响周转时间。当相同类别的模型应用于旧数据集时,AgES 与 XGBoost 达到更低的误差,突显了新数据的优势以及该技术在敏捷工作量估算中的适用性。
从研究模型到日常工具
对非专业人士而言,关键信息很直接:通过学习数千个过去的问题,计算机可以以有用的精度预测新问题可能需要的时间,尤其是当它们依赖关于真实项目的丰富开放数据时。这可以内置于轻量级网络工具或接入现有平台,以便在工单创建时,系统基于过去类似工作的记录提供一个解决时间的预测。尽管作者指出在非常大型或封闭的工业环境中结果可能不同,他们的工作展示了一条走向更可靠、透明的敏捷软件开发规划的实用路径——将团队从凭直觉转向基于证据的排期。
引用: Shankar, S.P., Chaudhari, S.S., Mishra, V. et al. Intelligent techniques for predictive analytics in Agile software development. Sci Rep 16, 11195 (2026). https://doi.org/10.1038/s41598-026-41102-4
关键词: 敏捷软件开发, 工作量估算, 预测分析, 机器学习, 项目规划