Clear Sky Science · en
Intelligent techniques for predictive analytics in Agile software development
Why predicting software work matters
Anyone who has waited for a software fix or a new feature knows the frustration of not knowing when it will actually arrive. Behind the scenes, teams struggle to guess how long each task will take, which affects deadlines, budgets, and customer trust. This paper explores how modern data-driven methods can turn those guesses into informed forecasts, helping Agile software teams plan their work in days instead of relying on vague “story points.” 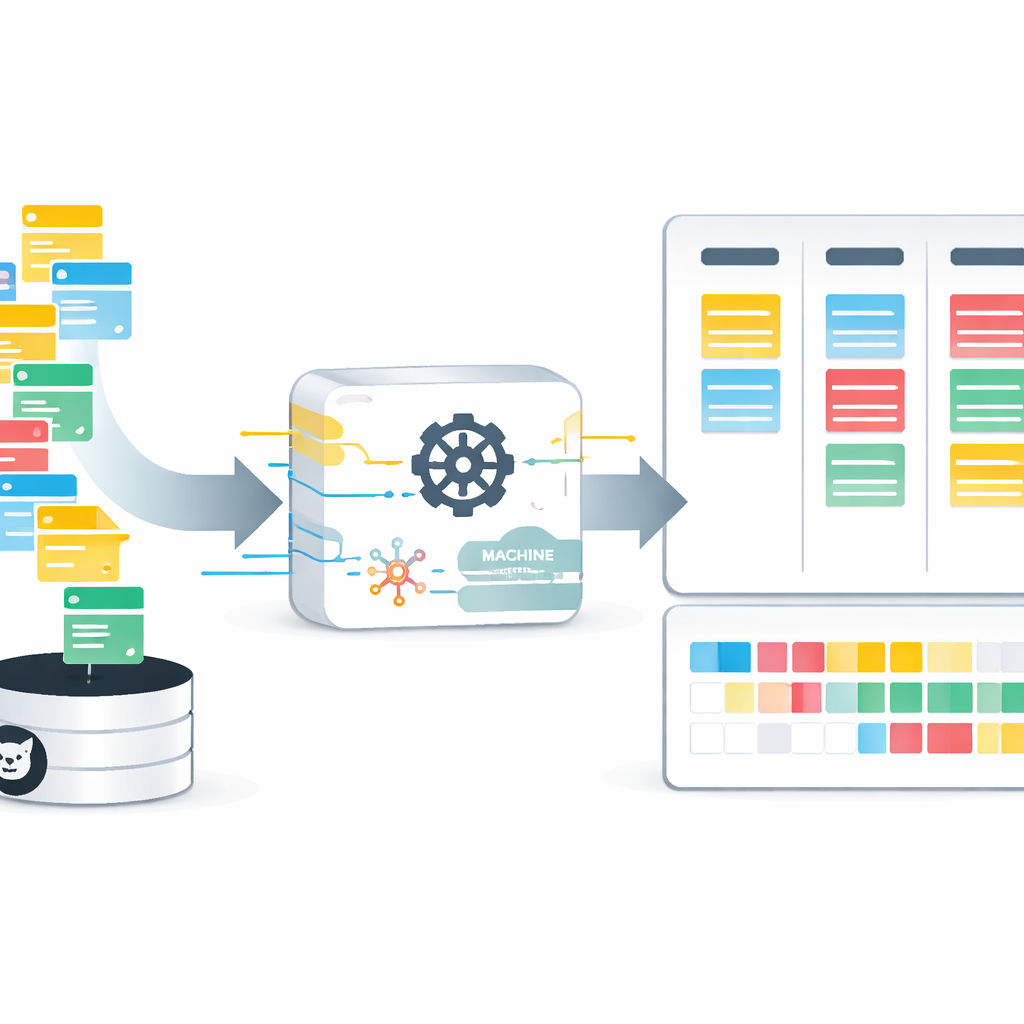
From rough guesses to data-driven forecasts
In many Agile teams, effort estimation still depends on group discussions, planning games, or the opinions of experienced developers. While familiar, these approaches are subjective: two teams might give very different estimates for the same job. Earlier research has mostly used private or paywalled company data, or focused on special units like story points that are defined differently from one organization to another. This makes it hard to compare results across projects and nearly impossible for outsiders to reproduce or extend the work.
Building a new open window into Agile work
To break this barrier, the authors introduce AgES, a new open dataset built entirely from public GitHub projects that use Agile practices. Instead of fuzzy story points, AgES records actual time in days between when an issue is opened and when it is closed. Each of more than 35,000 issues comes with rich context: who reported it, who worked on it, how many comments it attracted, and what labels and components (such as user interface, backend, or security) it involves. Using text processing, the team also derives higher-level information such as whether the issue is a bug, an improvement, or a new feature, and how experienced each contributor is with similar work.
Cleaning the data so machines can learn
Raw data from real projects are messy: some issues are still open, some fields are missing, and many details appear as free-form text. The researchers design a careful cleaning and transformation pipeline. They remove duplicate or incomplete entries, convert text labels and categories into numerical form, and compute new features such as contributor expertise. Because the time-to-resolution is highly skewed—most issues are solved quickly while a few take very long—they apply mathematical transformations and scaling to keep any one factor from dominating the learning process. The result is a streamlined, consistently formatted dataset that computers can use to spot patterns between issue characteristics and the days it takes to resolve them. 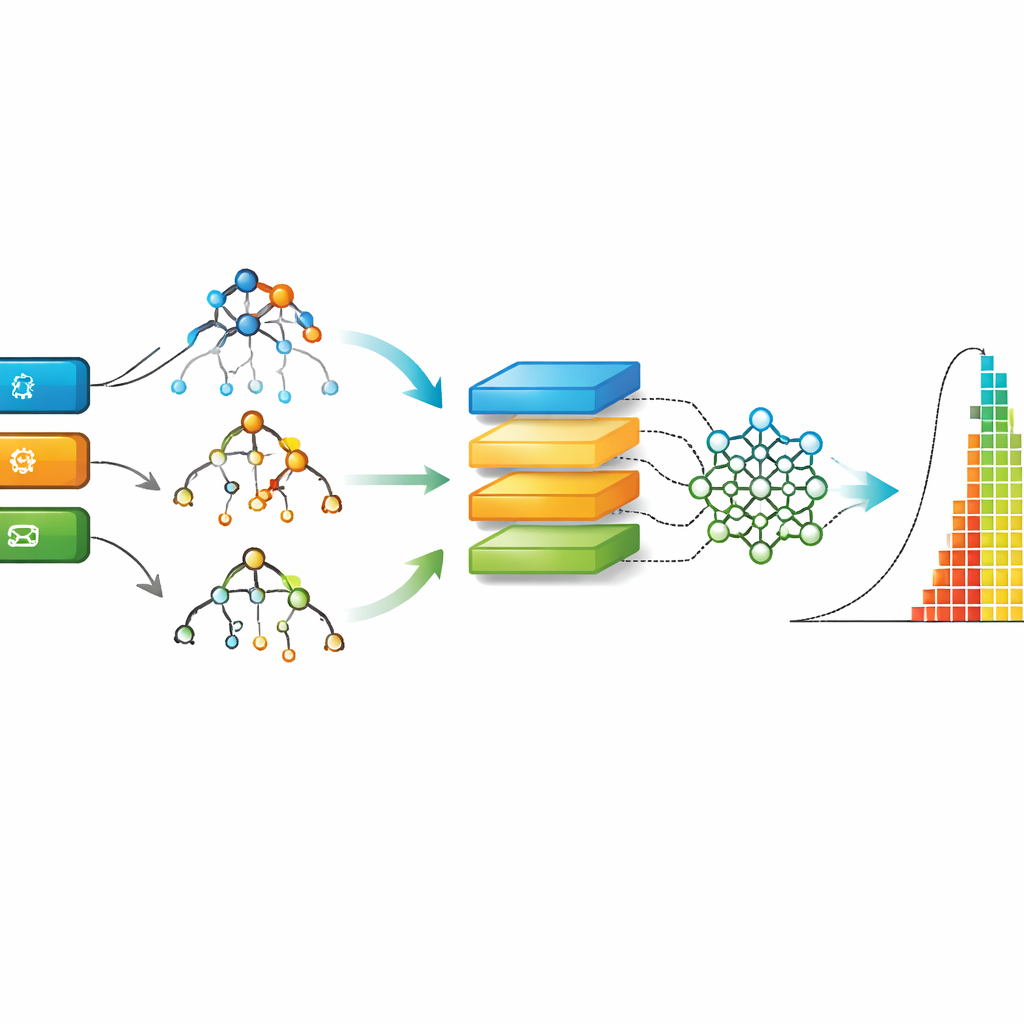
Putting multiple smart methods to the test
With the cleaned AgES data in hand, the authors compare nine different machine learning approaches, from classic decision trees and random forests to deep learning models such as recurrent and convolutional networks. Each model is trained on most of the data and then tested on unseen issues, with performance measured by how close its predictions come to the true resolution times. The study uses several standard error measures to capture both typical mistakes and rare but large misjudgments. It also benchmarks AgES against two well-known Agile datasets from earlier work, showing how the new dataset and models stack up.
What worked best and why it matters
Across all evaluation measures, a method called Extreme Gradient Boosting (XGBoost), which combines many small decision trees, consistently delivers the most accurate predictions on the AgES dataset. Tree-based methods like XGBoost and random forests handle real-world tabular data and missing values well, and they can capture nuanced, non-linear relationships—such as how a mix of issue type, component, and developer expertise influences turnaround time. When the same families of models are applied to older datasets, AgES coupled with XGBoost achieves lower errors, highlighting both the strength of the new data and the suitability of this technique for Agile effort estimation.
From research model to everyday tool
For non-specialists, the key message is straightforward: by learning from thousands of past issues, computers can predict how long new ones might take with useful accuracy, especially when they rely on rich, open data about real projects. This can be built into lightweight web tools or plugged into existing platforms so that, as soon as a ticket is created, the system offers a time-to-resolution forecast based on similar work from the past. While the authors note that results may differ in very large or closed industrial settings, their work shows a practical path toward more reliable, transparent planning in Agile software development—moving teams away from gut feeling and toward evidence-based scheduling.
Citation: Shankar, S.P., Chaudhari, S.S., Mishra, V. et al. Intelligent techniques for predictive analytics in Agile software development. Sci Rep 16, 11195 (2026). https://doi.org/10.1038/s41598-026-41102-4
Keywords: Agile software development, effort estimation, predictive analytics, machine learning, project planning