Clear Sky Science · ru
Интеллектуальные методы предиктивной аналитики в Agile-разработке программного обеспечения
Почему важно предсказывать сроки работ по программному обеспечению
Каждый, кто ждал исправления или новой функции, знаком с разочарованием от неизвестности — когда это действительно появится. За кулисами команды пытаются угадать, сколько займёт каждая задача, и эти догадки влияют на сроки, бюджеты и доверие пользователей. В этой статье рассматривается, как современные методы, основанные на данных, могут превратить догадки в обоснованные прогнозы, помогая Agile-командам планировать работу в днях вместо опоры на расплывчатые «story points». 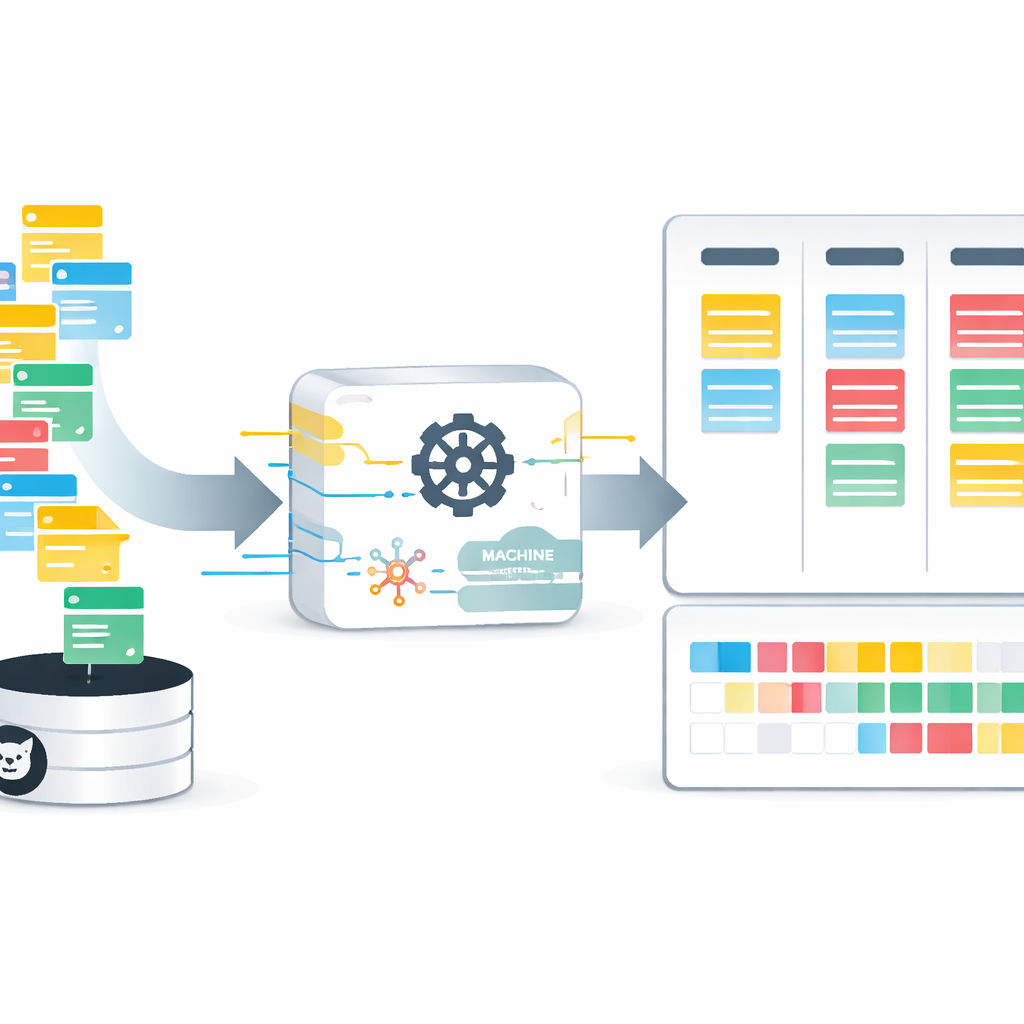
От приблизительных оценок к прогнозам на основе данных
Во многих Agile-командах оценка трудозатрат по-прежнему полагается на групповые обсуждения, планировочные игры или мнение опытных разработчиков. Хотя эти подходы знакомы, они субъективны: две команды могут дать очень разные оценки для одной и той же работы. Ранее исследования в основном использовали закрытые или платные корпоративные данные либо фокусировались на специальных единицах вроде story points, которые у разных организаций определяются по-разному. Это затрудняет сравнение результатов между проектами и почти делает невозможным воспроизведение или расширение работы внешними исследователями.
Новый открытый взгляд на Agile‑работу
Чтобы преодолеть эту преграду, авторы представляют AgES — новый открытый датасет, полностью собранный из публичных проектов на GitHub, использующих Agile‑практики. Вместо расплывчатых story points AgES фиксирует реальное время в днях между открытием issue и его закрытием. Каждое из более чем 35 000 issue сопровождается богатым контекстом: кто сообщил о проблеме, кто над ней работал, сколько было комментариев и какие метки и компоненты (например, интерфейс, серверная часть или безопасность) затронуты. С помощью обработки текста команда также выделяет информацию более высокого уровня, например, является ли issue багом, улучшением или новой функцией, а также насколько опытен каждый участник в схожих задачах.
Очистка данных, чтобы машины могли учиться
Исходные данные из реальных проектов шумны: некоторые issue остаются открытыми, некоторые поля отсутствуют, а многие детали представлены свободным текстом. Исследователи разработали аккуратный конвейер по очистке и преобразованию. Они удаляют дубли и неполные записи, переводят текстовые метки и категории в числовую форму и вычисляют новые признаки, такие как экспертность контрибьютора. Поскольку распределение времени до решения сильно скошено — большинство задач решается быстро, тогда как немногие занимают очень много времени — применяются математические преобразования и масштабирование, чтобы ни один фактор не доминировал в процессе обучения. В результате получается упорядоченный, единообразно отформатированный набор данных, который компьютеры могут использовать для выявления связей между характеристиками issue и числом дней до их решения. 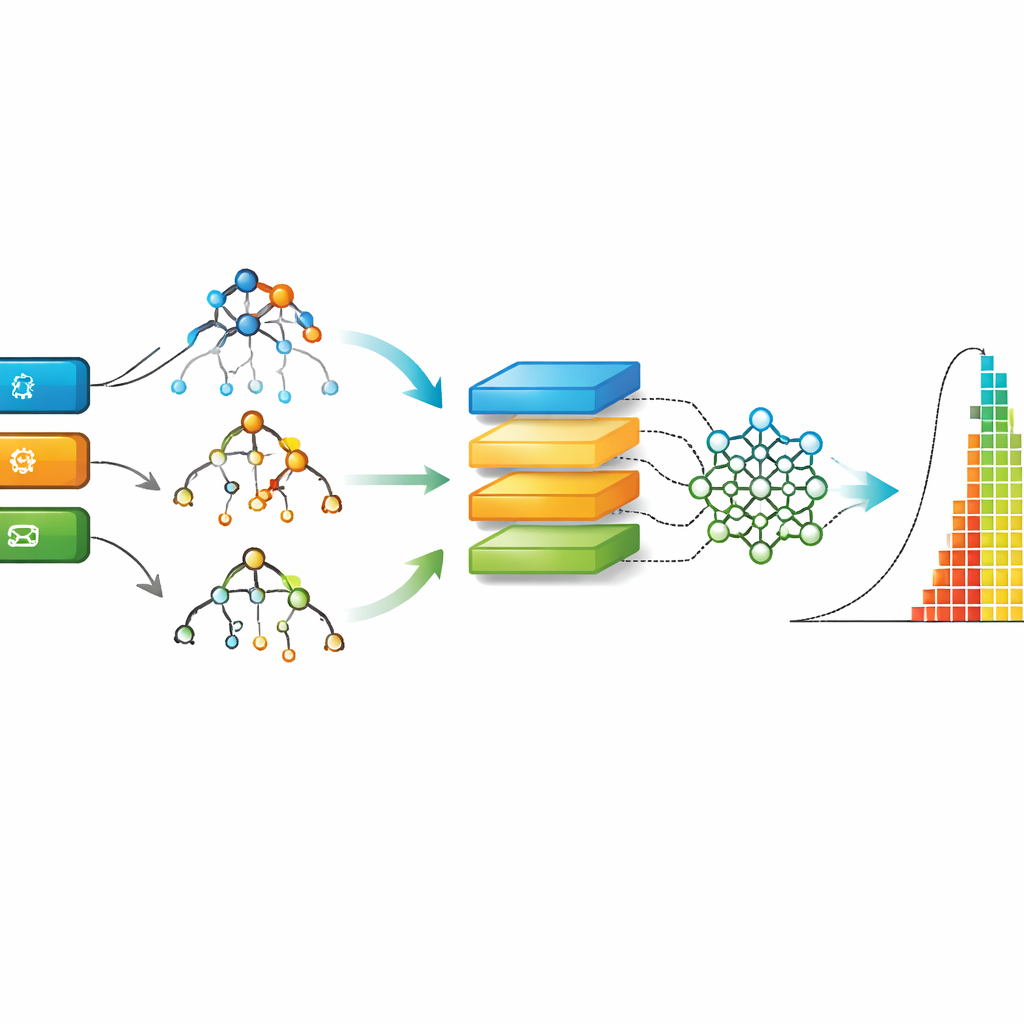
Сравнение нескольких интеллектуальных методов
Имея очищенные данные AgES, авторы сравнивают девять различных подходов машинного обучения — от классических деревьев решений и случайных лесов до глубоких моделей, таких как рекуррентные и сверточные сети. Каждая модель обучается на большей части данных, а затем тестируется на невидимых issue; производительность измеряется по тому, насколько близки прогнозы к реальным временам решения. В исследовании используются несколько стандартных метрик ошибки, которые фиксируют как типичные погрешности, так и редкие, но крупные просчёты. Также проводится бенчмарк AgES по сравнению с двумя хорошо известными Agile‑датасетами из предыдущих работ, чтобы показать, как новый набор данных и модели соотносятся с прежними результатами.
Что показало наилучшие результаты и почему это важно
По всем метрикам оценки метод Extreme Gradient Boosting (XGBoost), объединяющий множество небольших деревьев решений, стабильно даёт наиболее точные прогнозы на датасете AgES. Методы на основе деревьев, такие как XGBoost и случайные леса, хорошо справляются с реальными табличными данными и пропущенными значениями, а также способны улавливать тонкие нелинейные взаимосвязи — например, как сочетание типа issue, компонента и экспертности разработчика влияет на время выполнения. При применении тех же семейств моделей к старым датасетам сочетание AgES и XGBoost показывает меньшие ошибки, подчёркивая силу нового набора данных и пригодность этого подхода для оценки трудозатрат в Agile.
От исследовательской модели к повседневному инструменту
Для неспециалистов главный вывод прост: изучая тысячи прошлых issue, компьютеры могут с полезной точностью предсказывать, сколько займёт решение новых задач, особенно если они опираются на богатые открытые данные о реальных проектах. Это можно встроить в лёгкие веб‑инструменты или интегрировать в существующие платформы, так что сразу после создания тикета система предложит прогноз времени до его закрытия на основе похожих прошлых работ. Авторы отмечают, что результаты могут отличаться в очень крупных или закрытых промышленных условиях, однако их работа показывает практический путь к более надёжному и прозрачному планированию в Agile‑разработке — от ухода от интуиции к расписанию, основанному на доказательствах.
Цитирование: Shankar, S.P., Chaudhari, S.S., Mishra, V. et al. Intelligent techniques for predictive analytics in Agile software development. Sci Rep 16, 11195 (2026). https://doi.org/10.1038/s41598-026-41102-4
Ключевые слова: Agile-разработка программного обеспечения, оценка трудозатрат, предиктивная аналитика, машинное обучение, планирование проектов