Clear Sky Science · pt
Técnicas inteligentes para análise preditiva em desenvolvimento ágil de software
Por que prever o trabalho de software importa
Quem já esperou por uma correção ou por um recurso novo conhece a frustração de não saber quando isso realmente vai chegar. Nos bastidores, equipes lutam para estimar quanto tempo cada tarefa levará, o que afeta prazos, orçamentos e a confiança do cliente. Este artigo explora como métodos modernos orientados por dados podem transformar essas estimativas em previsões informadas, ajudando equipes ágeis a planejar o trabalho em dias, em vez de depender de vagas “story points”. 
De palpites aproximados a previsões baseadas em dados
Em muitas equipes ágeis, a estimativa de esforço ainda depende de discussões em grupo, jogos de planejamento ou das opiniões de desenvolvedores experientes. Embora familiares, essas abordagens são subjetivas: duas equipes podem dar estimativas muito diferentes para o mesmo trabalho. Pesquisas anteriores usaram em grande parte dados privados ou protegidos por paywall de empresas, ou se concentraram em unidades especiais como story points, que são definidas de maneira diferente entre organizações. Isso torna difícil comparar resultados entre projetos e quase impossível para quem está de fora reproduzir ou ampliar o trabalho.
Construindo uma nova janela aberta para o trabalho ágil
Para romper essa barreira, os autores apresentam o AgES, um novo conjunto de dados aberto construído inteiramente a partir de projetos públicos do GitHub que usam práticas ágeis. Em vez de story points nebulosos, o AgES registra o tempo real em dias entre a abertura e o fechamento de uma issue. Cada uma das mais de 35.000 issues vem com contexto rico: quem a reportou, quem trabalhou nela, quantos comentários recebeu e quais labels e componentes (como interface do usuário, backend ou segurança) estão envolvidos. Usando processamento de texto, a equipe também obtém informações de nível superior, como se a issue é um bug, uma melhoria ou um novo recurso, e quão experiente cada contribuinte é em trabalhos semelhantes.
Limpeza dos dados para que as máquinas possam aprender
Dados brutos de projetos reais são bagunçados: algumas issues ainda estão abertas, alguns campos faltam e muitos detalhes aparecem como texto livre. Os pesquisadores projetaram um pipeline cuidadoso de limpeza e transformação. Eles removem entradas duplicadas ou incompletas, convertem labels e categorias textuais em forma numérica e calculam novas features, como a expertise dos contribuidores. Como o tempo de resolução é altamente assimétrico—a maioria das issues é resolvida rapidamente enquanto algumas demoram muito—aplicam transformações matemáticas e escalonamento para evitar que um único fator domine o processo de aprendizado. O resultado é um conjunto de dados enxuto e formatado de maneira consistente que computadores podem usar para identificar padrões entre as características das issues e os dias necessários para resolvê-las. 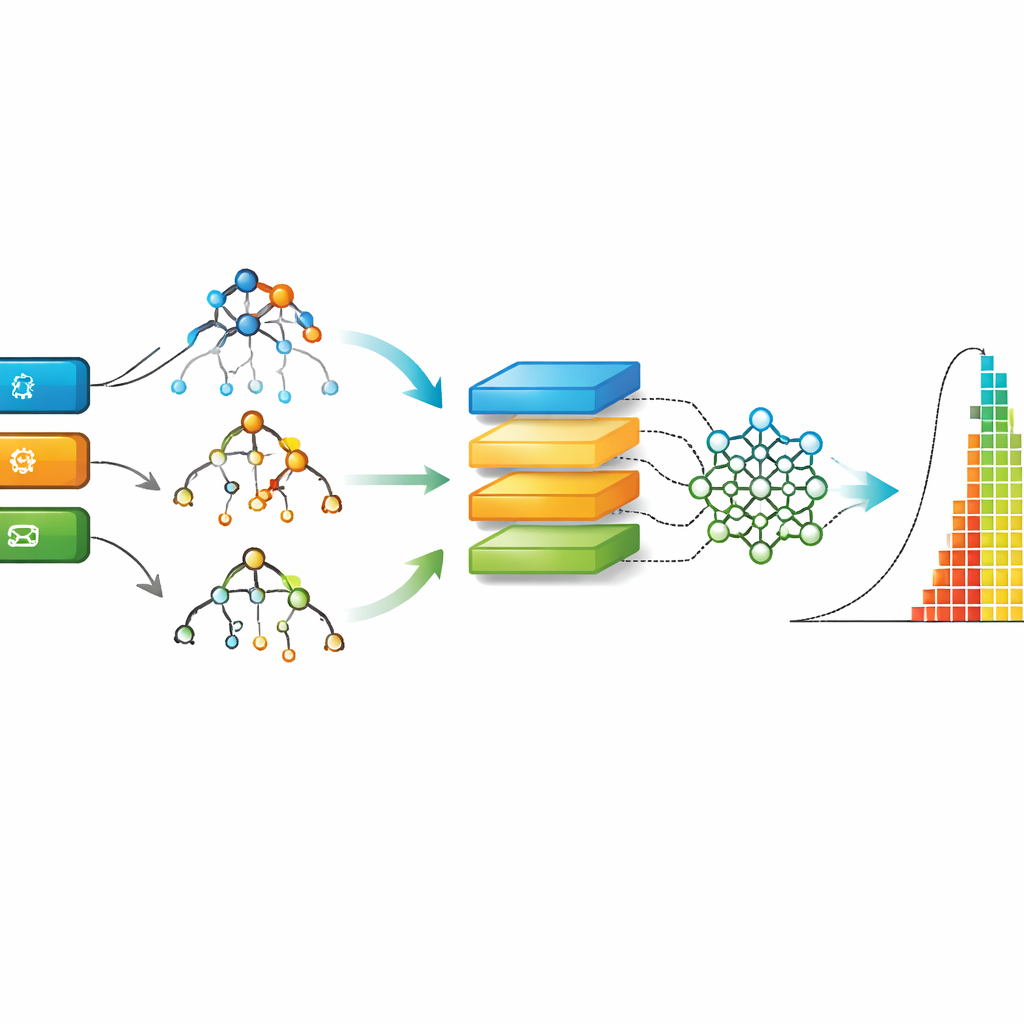
Testando múltiplos métodos inteligentes
Com os dados AgES limpos em mãos, os autores comparam nove abordagens diferentes de aprendizado de máquina, desde árvores de decisão clássicas e random forests até modelos de deep learning, como redes recorrentes e convolucionais. Cada modelo é treinado na maior parte dos dados e depois testado em issues não vistas, com o desempenho medido pela proximidade das previsões em relação aos tempos reais de resolução. O estudo usa várias métricas de erro padrão para capturar tanto erros típicos quanto falhas raras mas grandes. Também faz benchmark do AgES contra dois conjuntos de dados ágeis bem conhecidos de trabalhos anteriores, mostrando como o novo dataset e os modelos se comparam.
O que funcionou melhor e por que isso importa
Em todas as medidas de avaliação, um método chamado Extreme Gradient Boosting (XGBoost), que combina muitas pequenas árvores de decisão, entrega consistentemente as previsões mais precisas no conjunto AgES. Métodos baseados em árvores como XGBoost e random forests lidam bem com dados tabulares do mundo real e valores ausentes, além de capturar relações não lineares e sutis—como a forma como uma mistura de tipo de issue, componente e expertise do desenvolvedor influencia o tempo de resposta. Quando as mesmas famílias de modelos são aplicadas a conjuntos de dados mais antigos, o AgES em conjunto com XGBoost alcança erros menores, destacando tanto a qualidade dos novos dados quanto a adequação dessa técnica para estimativa de esforço em ágil.
Do modelo de pesquisa à ferramenta cotidiana
Para não especialistas, a mensagem principal é direta: ao aprender com milhares de issues passadas, os computadores podem prever quanto tempo novas issues podem levar com precisão útil, especialmente quando se baseiam em dados abertos e ricos sobre projetos reais. Isso pode ser incorporado em ferramentas web leves ou integrado a plataformas existentes para que, assim que um ticket seja criado, o sistema ofereça uma previsão do tempo de resolução com base em trabalhos semelhantes do passado. Embora os autores notem que os resultados possam diferir em ambientes industriais muito grandes ou fechados, o trabalho aponta um caminho prático para um planejamento mais confiável e transparente no desenvolvimento ágil de software—afastando equipes do feeling e aproximando-as do agendamento baseado em evidências.
Citação: Shankar, S.P., Chaudhari, S.S., Mishra, V. et al. Intelligent techniques for predictive analytics in Agile software development. Sci Rep 16, 11195 (2026). https://doi.org/10.1038/s41598-026-41102-4
Palavras-chave: Desenvolvimento ágil de software, estimativa de esforço, análise preditiva, aprendizado de máquina, planejamento de projeto