Clear Sky Science · es
Técnicas inteligentes para análisis predictivo en el desarrollo de software Ágil
Por qué importa predecir el trabajo de software
Cualquiera que haya esperado una corrección o una nueva funcionalidad conoce la frustración de no saber cuándo llegará realmente. Entre bastidores, los equipos luchan por adivinar cuánto tiempo llevará cada tarea, lo que afecta plazos, presupuestos y la confianza del cliente. Este artículo explora cómo los métodos modernos basados en datos pueden convertir esas conjeturas en previsiones informadas, ayudando a los equipos Ágil a planificar su trabajo en días en lugar de depender de vagos “story points”. 
De estimaciones aproximadas a previsiones basadas en datos
En muchos equipos Ágil, la estimación del esfuerzo sigue dependiendo de discusiones de grupo, juegos de planificación o de la opinión de desarrolladores experimentados. Aunque familiares, estos enfoques son subjetivos: dos equipos pueden dar estimaciones muy diferentes para el mismo trabajo. Investigaciones anteriores han utilizado principalmente datos privados o de pago de empresas, o se han centrado en unidades especiales como los story points, que se definen de forma distinta entre organizaciones. Esto dificulta comparar resultados entre proyectos y casi imposibilita que externos reproduzcan o amplíen los estudios.
Construyendo una nueva ventana abierta al trabajo Ágil
Para romper esta barrera, los autores presentan AgES, un nuevo conjunto de datos abierto construido íntegramente a partir de proyectos públicos en GitHub que usan prácticas Ágil. En lugar de los imprecisos story points, AgES registra el tiempo real en días entre la apertura y el cierre de un issue. Cada uno de más de 35 000 issues incluye un contexto rico: quién lo reportó, quién trabajó en él, cuántos comentarios atrajo y qué etiquetas y componentes (como interfaz de usuario, backend o seguridad) implica. Mediante procesamiento de texto, el equipo también extrae información de alto nivel, como si el issue es un bug, una mejora o una nueva funcionalidad, y cuán experimentado está cada colaborador en trabajo similar.
Limpiando los datos para que las máquinas aprendan
Los datos en bruto de proyectos reales son desordenados: algunos issues siguen abiertos, faltan campos y muchos detalles aparecen en texto libre. Los investigadores diseñan una canalización cuidadosa de limpieza y transformación. Eliminan entradas duplicadas o incompletas, convierten etiquetas y categorías de texto a forma numérica, y calculan nuevas características como la experiencia del colaborador. Dado que el tiempo hasta la resolución está muy sesgado—la mayoría de los issues se resuelven rápidamente mientras pocos tardan muchísimo—aplican transformaciones matemáticas y escalados para evitar que un solo factor domine el proceso de aprendizaje. El resultado es un conjunto de datos depurado y formateado de forma consistente que los ordenadores pueden usar para detectar patrones entre las características del issue y los días que tarda en resolverse. 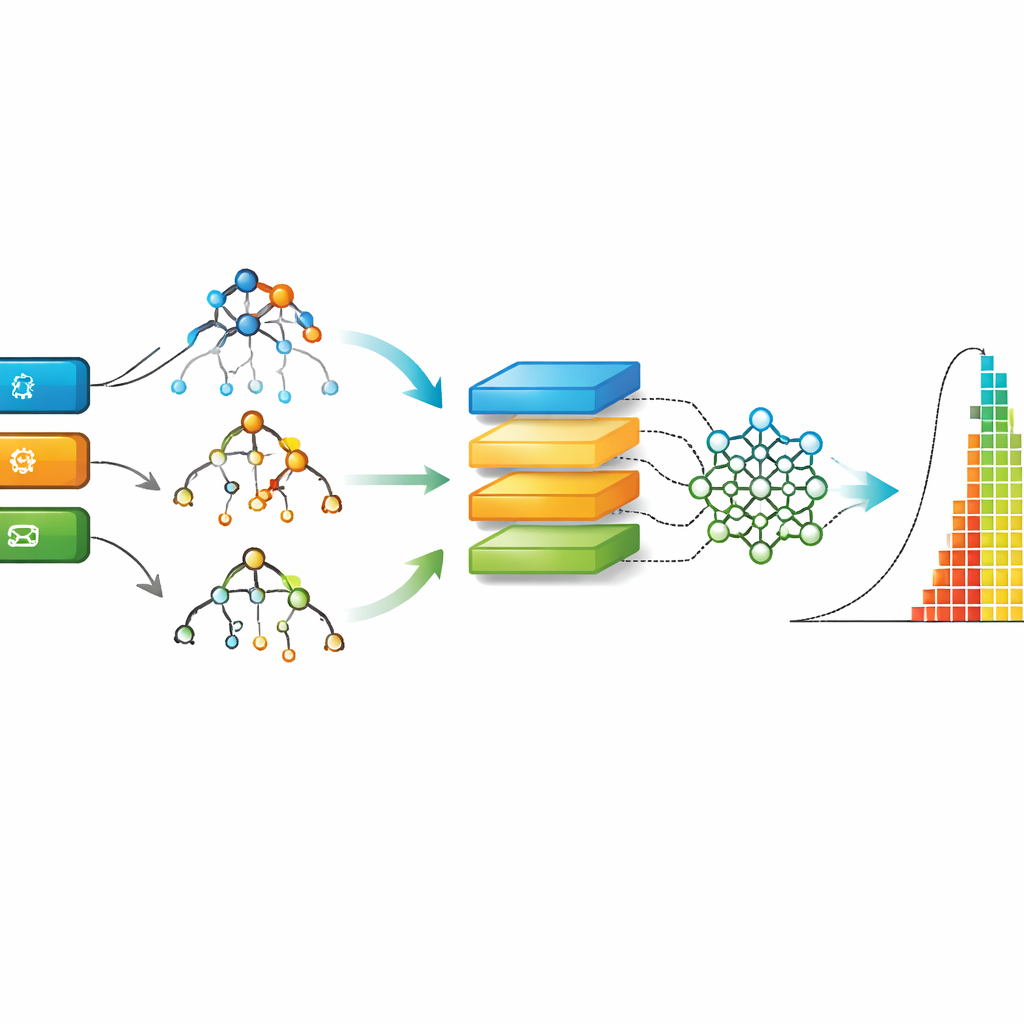
Poniendo a prueba múltiples métodos inteligentes
Con los datos AgES limpiados, los autores comparan nueve enfoques distintos de aprendizaje automático, desde árboles de decisión clásicos y bosques aleatorios hasta modelos de aprendizaje profundo como redes recurrentes y convolucionales. Cada modelo se entrena con la mayor parte de los datos y luego se prueba con issues no vistos, midiendo el rendimiento según lo cerca que están sus predicciones de los tiempos reales de resolución. El estudio emplea varias medidas de error estándar para capturar tanto errores típicos como equivocaciones raras pero grandes. También compara AgES con dos conjuntos de datos Ágil conocidos de trabajos anteriores, mostrando cómo se sitúan el nuevo conjunto y los modelos.
Qué funcionó mejor y por qué importa
En todas las medidas de evaluación, un método llamado Extreme Gradient Boosting (XGBoost), que combina muchos pequeños árboles de decisión, ofrece de forma consistente las predicciones más precisas en el conjunto AgES. Los métodos basados en árboles como XGBoost y los bosques aleatorios manejan bien datos tabulares del mundo real y valores faltantes, y pueden capturar relaciones no lineales y matizadas—por ejemplo, cómo una combinación de tipo de issue, componente y experiencia del desarrollador influye en el tiempo de resolución. Cuando las mismas familias de modelos se aplican a conjuntos de datos más antiguos, AgES junto con XGBoost logra errores menores, lo que subraya tanto la solidez del nuevo conjunto de datos como la idoneidad de esta técnica para la estimación de esfuerzo en Ágil.
Del modelo de investigación a la herramienta cotidiana
Para los no especialistas, el mensaje clave es simple: aprendiendo de miles de issues anteriores, los ordenadores pueden predecir cuánto podrían tardar los nuevos con una precisión útil, especialmente cuando se apoyan en datos abiertos y ricos sobre proyectos reales. Esto puede integrarse en herramientas web ligeras o conectarse a plataformas existentes de modo que, en cuanto se crea un ticket, el sistema ofrezca una previsión del tiempo hasta la resolución basada en trabajos similares del pasado. Aunque los autores señalan que los resultados pueden diferir en entornos industriales muy grandes o cerrados, su trabajo muestra un camino práctico hacia una planificación más fiable y transparente en el desarrollo de software Ágil—alejando a los equipos de la intuición y acercándolos a la programación basada en evidencia.
Cita: Shankar, S.P., Chaudhari, S.S., Mishra, V. et al. Intelligent techniques for predictive analytics in Agile software development. Sci Rep 16, 11195 (2026). https://doi.org/10.1038/s41598-026-41102-4
Palabras clave: Desarrollo de software Ágil, estimación de esfuerzo, análisis predictivo, aprendizaje automático, planificación de proyectos