Clear Sky Science · pl
Inteligentne techniki analityki predykcyjnej w zwinym tworzeniu oprogramowania
Dlaczego przewidywanie pracy nad oprogramowaniem ma znaczenie
Każdy, kto czekał na poprawkę lub nową funkcję, zna frustrację związaną z niepewnością, kiedy faktycznie się pojawi. Za kulisami zespoły próbują odgadnąć, ile czasu zajmie każde zadanie, co wpływa na terminy, budżety i zaufanie klientów. Artykuł bada, jak nowoczesne, oparte na danych metody mogą przekształcić te przypuszczenia w uzasadnione prognozy, pomagając zespołom Agile planować pracę w dniach zamiast polegać na niejasnych „story pointach”. 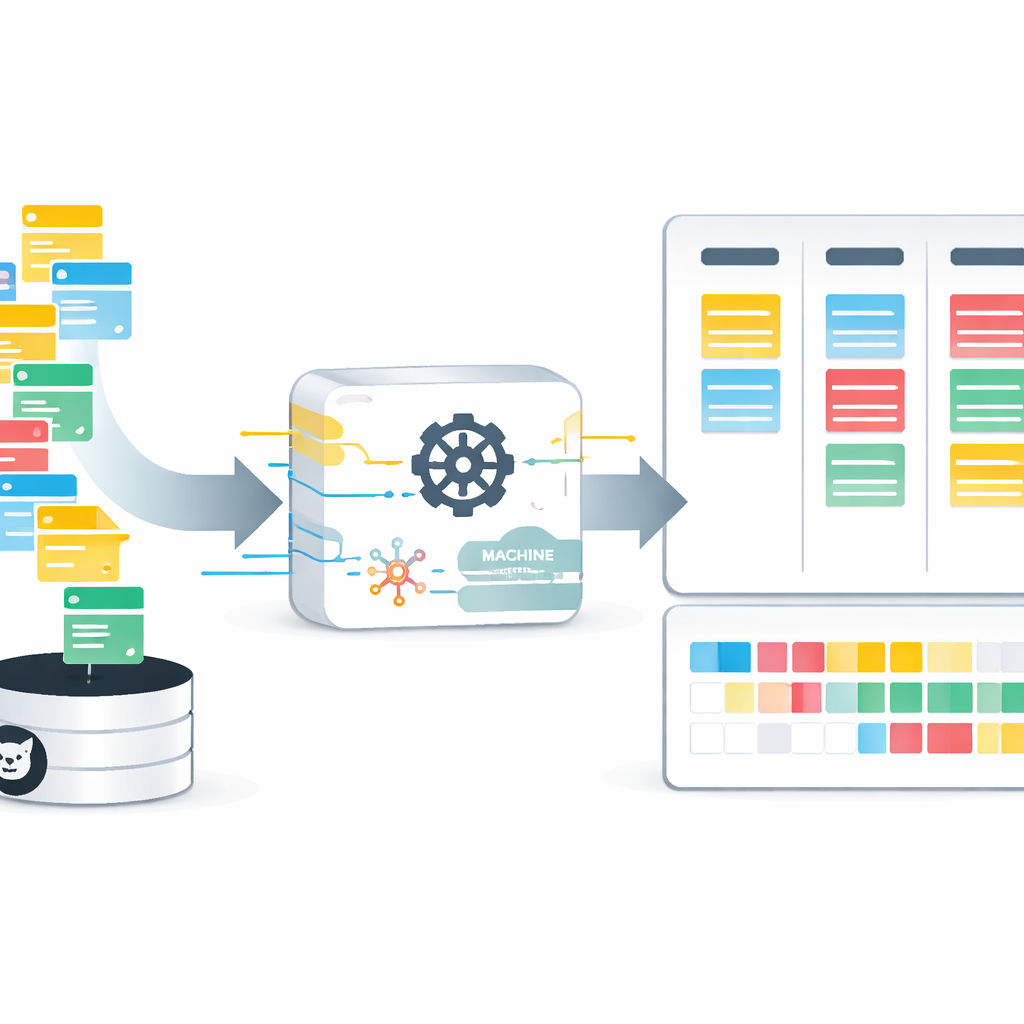
Od przybliżonych szacunków do prognoz opartych na danych
W wielu zespołach Agile estymacja nakładu pracy wciąż opiera się na dyskusjach grupowych, grach planistycznych lub opiniach doświadczonych programistów. Choć znane, podejścia te są subiektywne: dwa zespoły mogą podać bardzo różne szacunki dla tego samego zadania. Wcześniejsze badania w dużej mierze wykorzystywały prywatne lub płatne dane firmowe albo koncentrowały się na jednostkach takich jak story pointy, które są definiowane odmiennie w różnych organizacjach. Utrudnia to porównywanie wyników między projektami i niemal uniemożliwia zewnętrzne odtworzenie lub rozwinięcie prac.
Budowanie nowego, otwartego okna na pracę w Agile
Aby przełamać tę barierę, autorzy przedstawiają AgES — nowy, otwarty zestaw danych zbudowany w całości z publicznych projektów GitHub stosujących praktyki Agile. Zamiast nieostrych story pointów, AgES rejestruje rzeczywisty czas w dniach między otwarciem a zamknięciem zgłoszenia. Każde z ponad 35 000 zgłoszeń zawiera bogaty kontekst: kto je zgłosił, kto nad nimi pracował, ile komentarzy wygenerowało oraz jakie etykiety i komponenty (np. interfejs użytkownika, backend czy bezpieczeństwo) obejmuje. Za pomocą przetwarzania tekstu zespół wydobywa też informacje wyższej warstwy, takie jak to, czy zgłoszenie jest błędem, usprawnieniem czy nową funkcją oraz jak doświadczony jest każdy współautor w podobnych zadaniach.
Czyszczenie danych, aby maszyny mogły się uczyć
Surowe dane z realnych projektów są nieuporządkowane: niektóre zgłoszenia są nadal otwarte, niektóre pola brakują, a wiele szczegółów występuje jako tekst swobodny. Badacze zaprojektowali staranny pipeline do czyszczenia i transformacji. Usuwają duplikaty i niekompletne wpisy, konwertują etykiety i kategorie tekstowe na formę numeryczną oraz obliczają nowe cechy, takie jak ekspertyza współautorów. Ponieważ czas do rozwiązania jest silnie skośny — większość zgłoszeń rozwiązywana jest szybko, podczas gdy nieliczne zajmują bardzo dużo czasu — stosują transformacje matematyczne i skalowanie, aby żaden pojedynczy czynnik nie zdominował procesu uczenia. Efektem jest uproszczony, konsekwentnie sformatowany zestaw danych, który komputery mogą wykorzystać do wykrywania zależności między cechami zgłoszeń a liczbą dni potrzebnych na ich rozwiązanie. 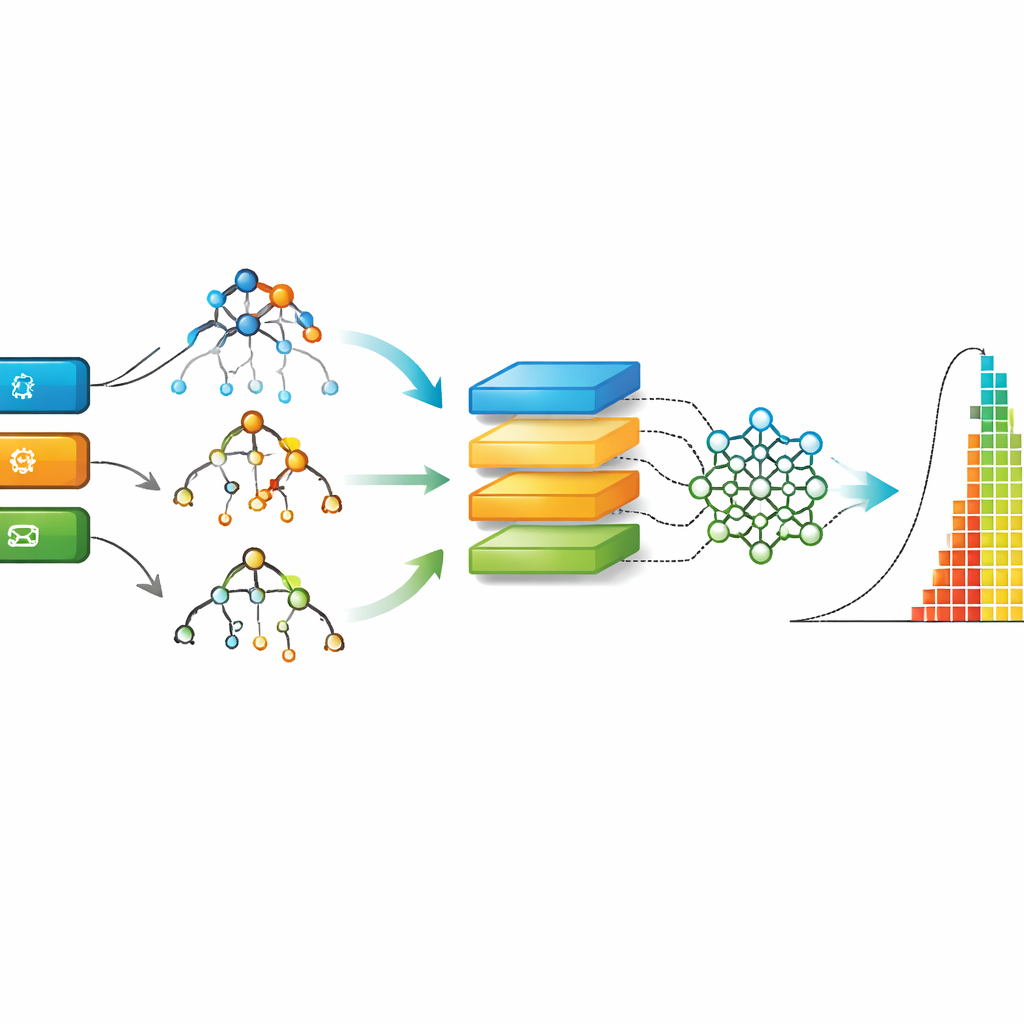
Testowanie wielu inteligentnych metod
Z oczyszczonymi danymi AgES autorzy porównują dziewięć różnych podejść z uczenia maszynowego, od klasycznych drzew decyzyjnych i lasów losowych po modele głębokiego uczenia, takie jak sieci rekurencyjne i konwolucyjne. Każdy model trenowany jest na większości danych, a następnie testowany na niewidzianych wcześniej zgłoszeniach; wydajność oceniana jest na podstawie tego, jak bliskie prawdziwym czasom rozwiązania są jego prognozy. W badaniu użyto kilku standardowych miar błędu, aby uchwycić zarówno typowe pomyłki, jak i rzadkie, ale duże nietrafienia. Porównano też AgES z dwoma znanymi, wcześniejszymi zbiorami danych Agile, pokazując, jak nowy zestaw i modele się prezentują.
Co sprawdziło się najlepiej i dlaczego to ma znaczenie
We wszystkich miarach ewaluacyjnych metoda zwana Extreme Gradient Boosting (XGBoost), łącząca wiele małych drzew decyzyjnych, konsekwentnie dawała najbardziej trafne prognozy na zestawie AgES. Metody oparte na drzewach, takie jak XGBoost i lasy losowe, dobrze radzą sobie z rzeczywistymi danymi tabelarycznymi i brakującymi wartościami oraz potrafią uchwycić złożone, nieliniowe zależności — na przykład jak kombinacja typu zgłoszenia, komponentu i ekspertyzy dewelopera wpływa na czas realizacji. Gdy te same rodziny modeli zastosowano do starszych zestawów, AgES w połączeniu z XGBoost osiągnął niższe błędy, co podkreśla zarówno wartość nowych danych, jak i przydatność tej techniki do estymacji nakładu pracy w Agile.
Od modelu badawczego do narzędzia codziennego użytku
Dla osób niebędących specjalistami kluczowy przekaz jest prosty: ucząc się na tysiącach przeszłych zgłoszeń, komputery potrafią z użyteczną dokładnością przewidzieć, ile mogą zająć nowe, szczególnie gdy opierają się na bogatych, otwartych danych o prawdziwych projektach. Można to wdrożyć jako lekkie narzędzia webowe lub zintegrować z istniejącymi platformami, tak by zaraz po utworzeniu zgłoszenia system proponował prognozę czasu do rozwiązania na podstawie podobnych zadań z przeszłości. Autorzy zaznaczają, że wyniki mogą się różnić w bardzo dużych lub zamkniętych środowiskach przemysłowych, ale ich praca pokazuje praktyczną ścieżkę do bardziej wiarygodnego, przejrzystego planowania w zwinym tworzeniu oprogramowania — przesuwając zespoły od intuicji w stronę planowania opartego na dowodach.
Cytowanie: Shankar, S.P., Chaudhari, S.S., Mishra, V. et al. Intelligent techniques for predictive analytics in Agile software development. Sci Rep 16, 11195 (2026). https://doi.org/10.1038/s41598-026-41102-4
Słowa kluczowe: Zwinne tworzenie oprogramowania, estymacja nakładu pracy, analityka predykcyjna, uczenie maszynowe, planowanie projektów