Clear Sky Science · tr
Çevik yazılım geliştirmede öngörücü analiz için akıllı teknikler
Yazılım işleri için tahmin yapmanın önemi
Bir yazılım düzeltmesi veya yeni bir özellik için bekleyen herkes, bunun ne zaman gerçekten teslim edileceğini bilmemekten doğan hayal kırıklığını bilir. Perde arkasında ekipler, her görevin ne kadar süreceğini tahmin etmeye çalışır; bu da teslim tarihlerini, bütçeleri ve müşteri güvenini etkiler. Bu makale, modern veri odaklı yöntemlerin bu tahminleri nasıl bilgilendirilmiş öngörülere dönüştürebileceğini araştırıyor; böylece Çevik yazılım ekipleri belirsiz “story point”lere dayanmak yerine işlerini gün bazında planlayabilir. 
Yaklaşık tahminlerden veri odaklı öngörülere
Birçok Çevik ekipte çaba tahmini hâlâ grup tartışmalarına, planlama oyunlarına veya deneyimli geliştiricilerin görüşlerine dayanır. Tanıdık olsa da bu yaklaşımlar özneldir: iki ekip aynı iş için çok farklı tahminler verebilir. Önceki araştırmalar çoğunlukla özel veya ücretli şirket verilerini kullandı veya kuruluşlar arasında farklı tanımlanan story point gibi özel birimlere odaklandı. Bu durum projeler arasında sonuçları karşılaştırmayı zorlaştırır ve dışarıdakilerin çalışmayı yeniden üretmesini veya genişletmesini neredeyse imkânsız kılar.
Çevik çalışmaya yeni, açık bir pencere açmak
Bu engeli aşmak için yazarlar, tamamen Çevik uygulamalar kullanan açık GitHub projelerinden oluşturulmuş yeni bir açık veri seti olan AgES’i tanıtıyor. Belirsiz story pointler yerine AgES, bir issue’nun açıldığı ile kapatıldığı arasındaki gerçek zamanı gün cinsinden kaydeder. 35.000’den fazla issue’nun her biri zengin bağlamla birlikte gelir: kim bildirdi, kim üzerinde çalıştı, kaç yorum aldı ve hangi etiketler ile bileşenleri (örneğin kullanıcı arayüzü, arka uç veya güvenlik) içeriyor. Metin işleme kullanılarak ekip ayrıca issue’nun hata mı, iyileştirme mi yoksa yeni bir özellik mi olduğu ve her katkıda bulunanın benzer işler konusundaki deneyimi gibi üst düzey bilgileri çıkarır.
Makinelerin öğrenebilmesi için veriyi temizlemek
Gerçek projelerden gelen ham veriler dağınıktır: bazı issue’lar hâlâ açık, bazı alanlar eksik ve birçok ayrıntı serbest biçimli metin olarak görünür. Araştırmacılar dikkatli bir temizlik ve dönüşüm hattı tasarlar. Çift veya eksik girişleri kaldırırlar, metin etiketleri ve kategorileri sayısal forma dönüştürürler ve katkıda bulunan uzmanlığı gibi yeni özellikler hesaplarlar. Çözüm süresi güçlü şekilde çarpık olduğundan—çoğu issue hızlı çözülürken birkaç tanesi çok uzun sürer—öğrenme sürecinde herhangi bir faktörün baskın olmasını önlemek için matematiksel dönüşümler ve ölçeklendirmeler uygularlar. Sonuç, issue özellikleri ile çözüm süresine (gün) ilişkin kalıpları bilgisayarların keşfedebileceği, düzenli ve tutarlı biçimlendirilmiş bir veri kümesidir. 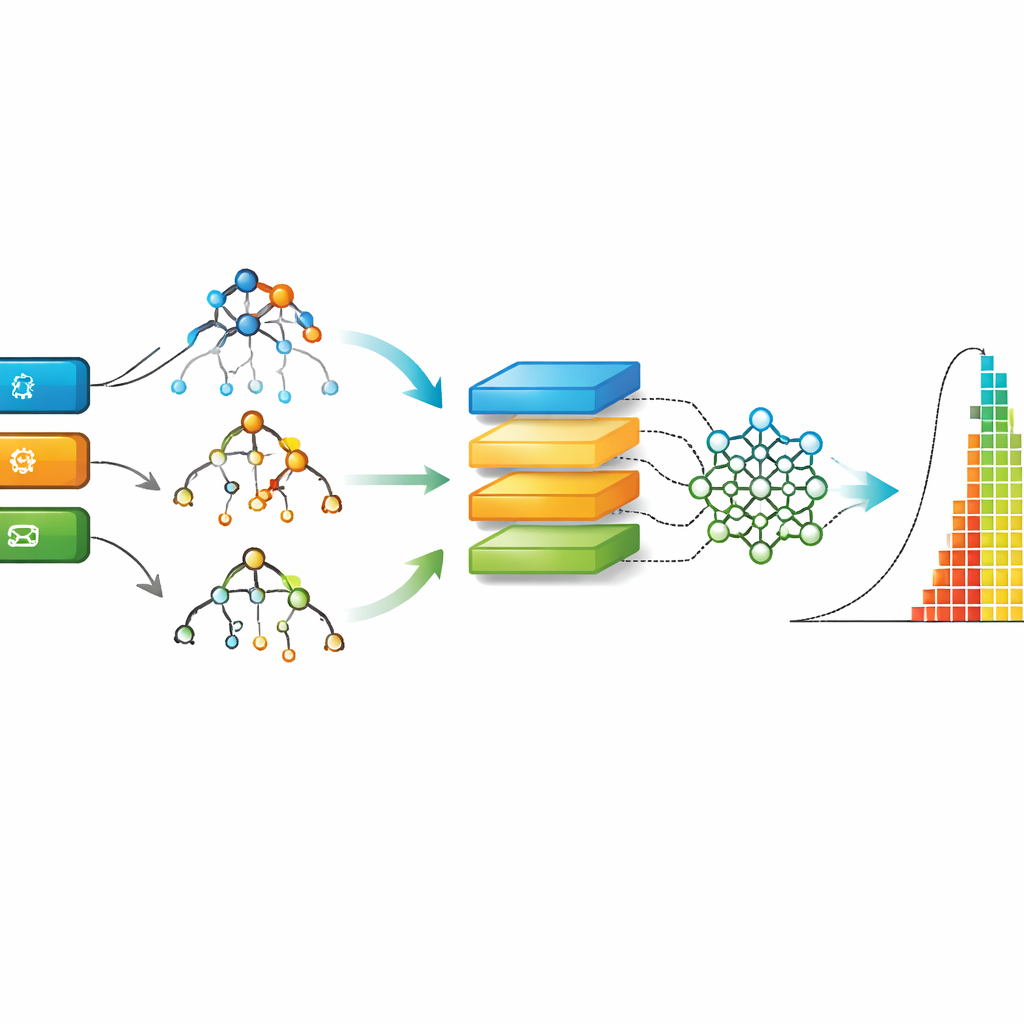
Birden çok akıllı yöntemi teste sokmak
Temizlenmiş AgES verisiyle yazarlar dokuz farklı makine öğrenimi yaklaşımını karşılaştırır; klasik karar ağaçları ve rastgele ormanlardan tekrarlayan ve evrişimli ağlar gibi derin öğrenme modellere kadar. Her model verinin çoğunda eğitilir ve ardından görülmemiş issue’lar üzerinde test edilir; performans gerçek çözüm sürelerine ne kadar yakın tahmin yaptığıyla ölçülür. Çalışma, tipik hataları ve nadir fakat büyük yanlış tahminleri yakalamak için birkaç standart hata ölçüsü kullanır. Ayrıca AgES’i önceki çalışmalardan iki iyi bilinen Çevik veri kümesiyle karşılaştırarak yeni veri ve modellerin nasıl bir performans sergilediğini gösterir.
En iyi çalışan yöntem ve bunun önemi
Tüm değerlendirme ölçütleri boyunca, birçok küçük karar ağacını birleştiren Extreme Gradient Boosting (XGBoost) adlı bir yöntem AgES veri kümesinde tutarlı şekilde en doğru tahminleri sunar. XGBoost ve rastgele ormanlar gibi ağaç tabanlı yöntemler gerçek dünya tablosal verileri ve eksik değerleri iyi işler ve issue türü, bileşen ve geliştirici uzmanlığı gibi faktörlerin bir araya gelmesinin çözüm süresini nasıl etkilediği gibi nüanslı, doğrusal olmayan ilişkileri yakalayabilir. Aynı model aileleri eski veri kümelerine uygulandığında, AgES ile birlikte XGBoost daha düşük hatalar elde ederek hem yeni verinin gücünü hem de bu tekniğin Çevik çaba tahmini için uygunluğunu vurgular.
Araştırma modelinden günlük araca
Uzman olmayanlar için temel mesaj açıktır: binlerce geçmiş issue’dan öğrenerek bilgisayarlar, özellikle gerçek projelere ait zengin, açık verilere dayandığında, yeni issue’ların ne kadar sürebileceğini faydalı bir doğrulukla tahmin edebilir. Bu, hafif web araçlarına entegre edilebilir veya mevcut platformlara takılabilir; böylece bir bilet oluşturulur oluşturulmaz sistem geçmişteki benzer işlere dayalı bir çözüm süresi tahmini sunar. Yazarlar sonuçların çok büyük veya kapalı endüstriyel ortamlarda farklı olabileceğini not etse de, çalışmaları Çevik yazılım geliştirmede sezgilere dayanmak yerine kanıta dayalı planlamaya doğru daha güvenilir, şeffaf bir yol gösterdiğini ortaya koyuyor.
Atıf: Shankar, S.P., Chaudhari, S.S., Mishra, V. et al. Intelligent techniques for predictive analytics in Agile software development. Sci Rep 16, 11195 (2026). https://doi.org/10.1038/s41598-026-41102-4
Anahtar kelimeler: Çevik yazılım geliştirme, çaba tahmini, öngörücü analiz, makine öğrenimi, proje planlaması