Clear Sky Science · zh
在无需外部能量供应的自我复制体中,非酶促的错误纠正
为何在无酶条件下复制生命密码很重要
在细胞进化出复杂的分子机械之前,地球上的任何早期遗传物质都必须仅依靠简单化学进行自我复制。但在没有过多错误的情况下复制像 DNA 和 RNA 那样由“字母”组成的长链极其困难。本文探讨了相对简单的分子如何在没有酶、也无需诸如 ATP 等额外燃料供应的情况下实现准确复制,为生命最初的遗传系统出现并维持提供了具体途径。
关于错误与生命起源的难题
现代细胞使用专门的蛋白质校对 DNA 并修复错误,这一过程消耗化学能量。然而这些酶过于复杂,不可能存在于早期地球上。没有它们,原始的自我复制链会快速积累错误,以至于有用信息无法从一代传到下一代。现有理论要么假设分子群体之间互相帮助,要么依赖精细调控的环境或额外的能量来源。作者提出另一个问题:单一的自我复制链能否仅利用驱动其生长的能量纠正自身复制错误?
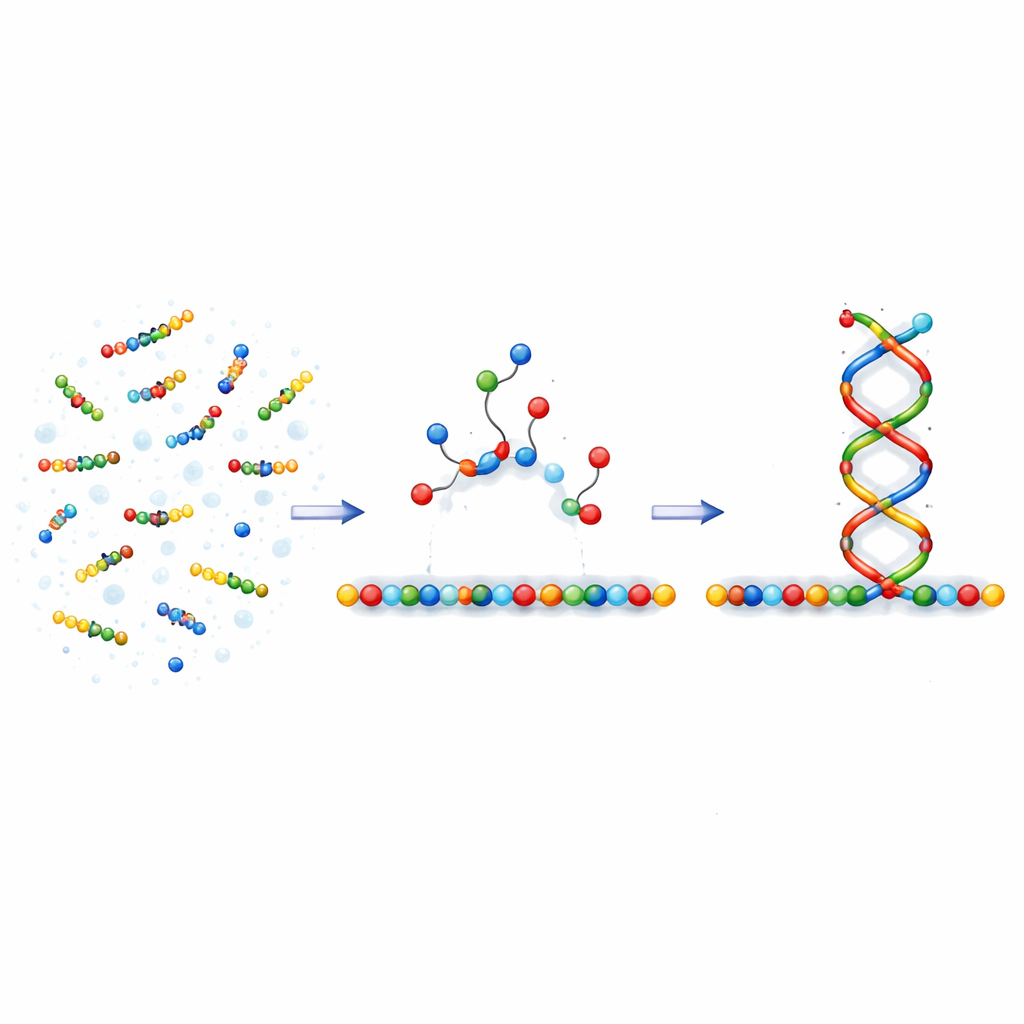
推动生长的单向机制
作者基于一种被称为非对称协同的动力学特征展开想象。设想一条模板链,新构建基块通过弱键短暂附着在上面。当某位置结合了正确的基块时,它会使得同一侧(例如向右)另一个基块更容易结合,同时使已存在的键更不容易断开。在相反一侧则使条件稍微更困难,从而沿模板在单一方向上推动生长。在他们的模型里,正确配对具有这种定向影响,而错误配对则没有。这一简单规则使得正确匹配的片段能够沿着一个方向快速生长,而错配会在其位置使生长停滞并使附近的键更不稳定。
将时间差转化为更少的错误
单靠这种定向停滞只会产生短暂差异:正确片段平稳前进;含错的片段则暂停并倾向于解开。关键步骤是,生长链上相邻单元也可以形成牢固、几乎不可逆的化学键。形成这些键在能量上是高度放热的,但其速度可能快也可能慢,取决于化学性质。作者表明,当该成键步骤足够快——与错配引起的短暂延迟处于相同时间尺度——它会优先“锁定”恰好正确的片段,在错误单元有时间被稳定之前将正确序列固定下来。如果成键太慢,到形成共价键时一切已重新达到平衡,系统就无法区分对错。
模拟一种原始的复制机
为探讨这一想法,研究团队把每个短模板视为一串位置,这些位置可以是未配对、正确配对或错误配对。然后他们使用马尔可夫链模型——一种描述随机逐步过程的标准数学工具——来跟踪碱基对形成与断裂的所有可能路径。通过改变定向偏差、配对与解配对速率以及共价成键速度,他们计算了最终复制链中错误的发生频率和复制所需时间。他们发现,强烈的单向协同和足够快速的成键共同作用,可以将错误率从纯热力学基准的大约百分之一降低到约万分之一,这与真实 DNA 聚合酶在其“被动”碱基选择阶段(在额外校对开始之前)所观察到的水平相当。
类似真实生物学的模式
值得注意的是,这个精简模型再现了现代 DNA 复制中观察到的若干特征。当出现错配时,模拟中的链增长明显减慢——这是一种在实验中也见到的“停滞”形式。错配会增加链端剥离的倾向,呼应真实 DNA 中观察到的“毛刺”现象。在错配之后加入一个正确的基块既能加快生长又能将错误锁定在原位,这与测得的“下一个核苷酸效应”相符,即后续正确核苷酸可以稳定前面的错误。模型还显示出速度与准确性之间的权衡:使碱基配对驱动力过弱或过强都会降低保真度,而存在一个中间的最优区间,在那里复制既足够准确又不会太慢。
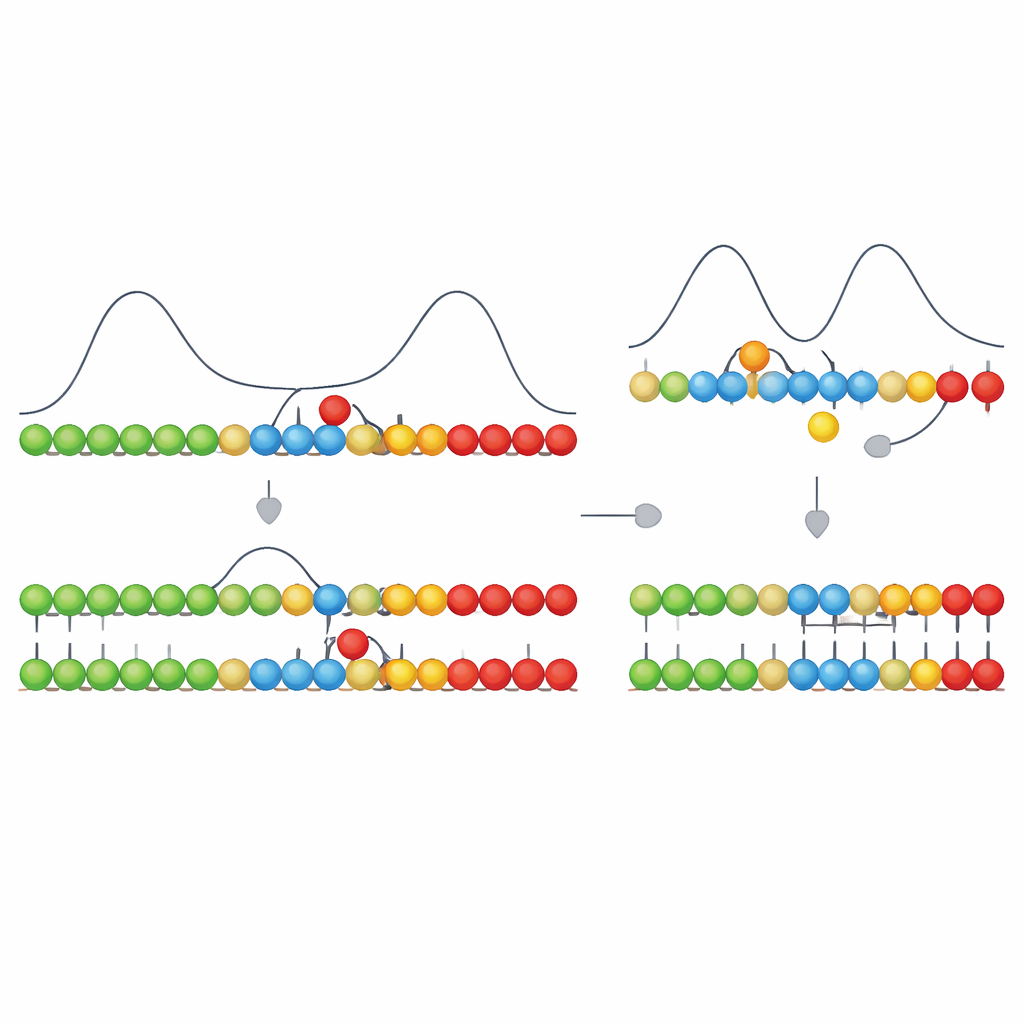
简单化学如何建立持久秩序
对普通读者而言,主要信息是:准确复制遗传信息初期可能并不需要复杂的分子机器。作者表明,如果正确配对有助于沿一个方向推进生长,且单元间的强骨架键形成得足够快,那么系统可以利用驱动生长的同一能量来剔除许多错误。由此可见,现代细胞中的酶主要是在精炼和加速一种基本的物理原理,而不是从无到有地发明它。这为早期无酶的遗传聚合物达到足够高的复制准确性以支持进化提供了一个可信路径,并更广泛地展示了在一个有能量输入但无酶的世界中,如何通过简单、带偏好的动力学产生持久的分子有序。
引用: Ghosh, K., Sahu, P., Barik, S. et al. Non-enzymatic error correction in self-replicators without extraneous energy supply. Sci Rep 16, 10165 (2026). https://doi.org/10.1038/s41598-026-40325-9
关键词: 生命起源, DNA 复制保真性, 非酶促复制, 错误纠正, 原始化学