Clear Sky Science · de
Nicht-enzymatische Fehlerkorrektur bei sich selbst replizierenden Systemen ohne externen Energiezufuhr
Warum das Kopieren des Codes des Lebens ohne Enzyme wichtig ist
Bevor Zellen ihre ausgefeilten molekularen Maschinen entwickelt hatten, musste jegliches frühe genetische Material auf der Erde sich nur mithilfe einfacher Chemie kopieren. Lange Ketten von „Buchstaben“ — wie in DNA und RNA — zu kopieren, ohne zu viele Fehler zu machen, ist jedoch außerordentlich schwierig. Dieses Papier untersucht, wie relativ einfache Moleküle sich akkurat selbst hätten kopieren können, ohne Enzyme und ohne eine zusätzliche Energiequelle wie ATP, und liefert damit einen konkreten Weg, wie die ersten genetischen Systeme des Lebens entstehen und bestehen konnten.
Ein Rätsel über Fehler und den Ursprung des Lebens
Moderne Zellen verwenden spezialisierte Proteine, um DNA zu prüfen und Fehler zu beheben, wobei chemische Energie verbrannt wird. Diese Enzyme sind jedoch viel zu komplex, um auf der frühen Erde existiert zu haben. Ohne sie würden primitive selbstkopierende Stränge Fehler so schnell akkumulieren, dass nützliche Information von einer Generation zur nächsten nicht erhalten werden könnte. Bestehende Theorien nehmen entweder Gemeinschaften von sich gegenseitig helfenden Molekülen an oder stützen sich auf fein abgestimmte Umgebungen bzw. zusätzliche Energiequellen. Die Autoren fragen stattdessen: Könnte eine einzelne selbstreplizierende Kette ihre eigenen Kopierfehler mit nur der Energie korrigieren, die ohnehin ihr Wachstum antreibt?
Ein einseitiger Schub, der das Wachstum lenkt
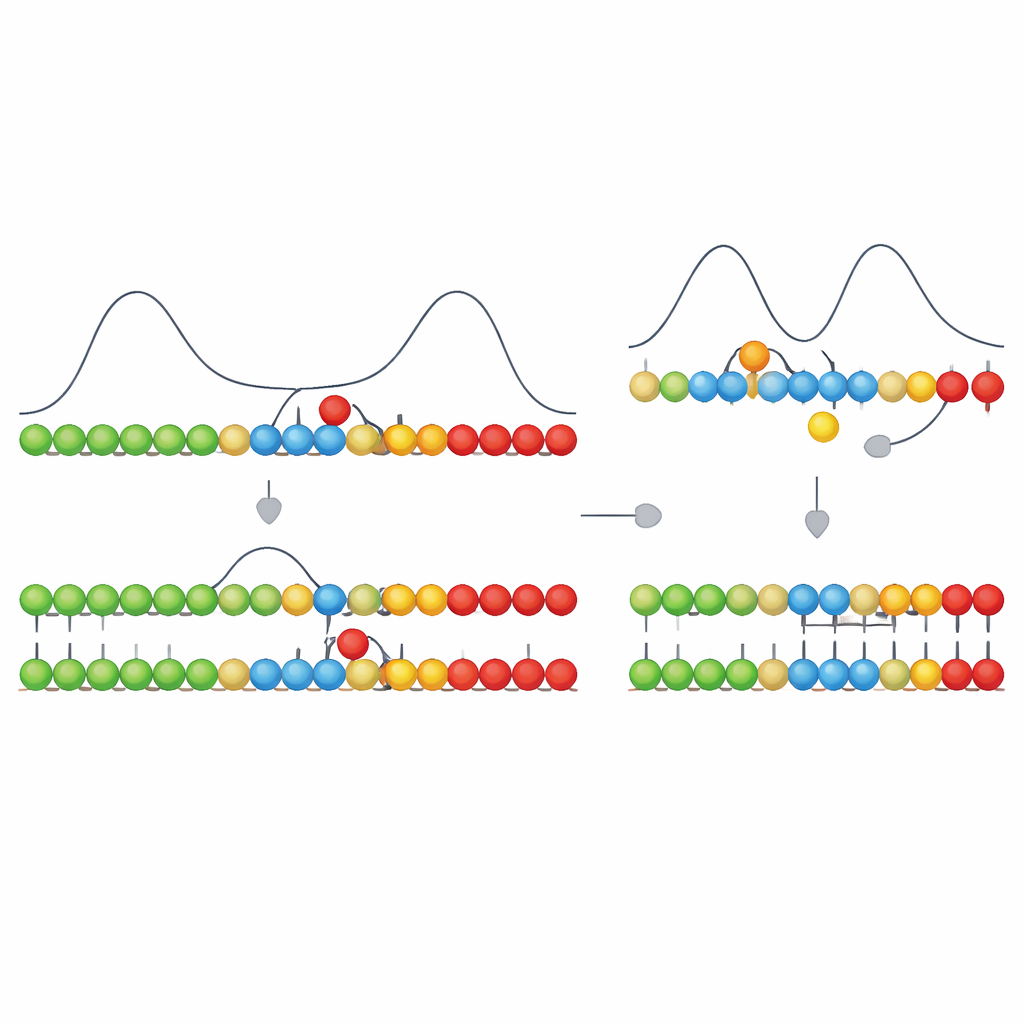
Die Autoren bauen auf einem kinetischen Merkmal auf, das sie asymmetrische Kooperativität nennen. Stellen Sie sich eine Matrize (Template)-Strang vor, an den neue Bausteine vorübergehend durch schwache Bindungen haften. Wenn an einer Position der richtige Baustein bindet, erleichtert er das Binden eines weiteren Bausteins auf einer bestimmten Seite (etwa rechts) und macht es gleichzeitig schwerer, dass die bestehende Bindung sich löst. Auf der gegenüberliegenden Seite wirkt er leicht hemmend, wodurch das Wachstum entlang der Matrize effektiv in eine Richtung geschoben wird. In ihrem Modell besitzen korrekte Paarungen diesen richtungsweisenden Einfluss, falsche nicht. Diese einfache Regel lässt richtig gepaarte Abschnitte schnell in eine Richtung wachsen, während Fehlpaarungen das Wachstum an ihrer Stelle zum Stocken bringen und benachbarte Bindungen destabilisieren.
Timing-Unterschiede in weniger Fehler verwandeln
Für sich genommen würde dieses gerichtete Stocken nur vorübergehende Unterschiede erzeugen: korrekte Segmente schreiten glatt voran; Segmente mit einem falschen Baustein pausieren und neigen dazu sich aufzulösen. Der entscheidende Schritt ist, dass benachbarte Einheiten auf dem wachsenden Strang auch starke, nahezu irreversible chemische Verknüpfungen miteinander eingehen können. Die Bildung dieser Verknüpfungen ist energetisch stark begünstigt, kann aber je nach Chemie schnell oder langsam erfolgen. Die Autoren zeigen, dass wenn dieser Verknüpfungsschritt schnell genug ist — auf derselben Zeitskala wie die kurze Verzögerung, die eine Fehlpaarung verursacht —, er bevorzugt jene Abschnitte „verriegelt“, die zufällig korrekt waren, bevor ein falsches Baustein Zeit hat, stabilisiert zu werden. Ist die Verknüpfung zu langsam, hat sich bis zum Verknüpfungszeitpunkt alles wieder ausgeglichen, und das System kann nicht mehr zwischen richtig und falsch unterscheiden.
Simulation einer primitiven Kopiermaschine
Um diese Idee zu untersuchen, behandelt das Team jede kurze Vorlage als eine Kette von Positionen, die ungepaart, korrekt gepaart oder falsch gepaart sein können. Sie verwenden dann ein Markow-Ketten-Modell — ein übliches mathematisches Werkzeug für zufällige Schritt-für-Schritt-Prozesse —, um alle möglichen Pfade zu verfolgen, während Basenpaare sich bilden und wieder brechen. Durch Variation der gerichteten Verzerrung, der Raten von Paarung und Dissoziation sowie der Geschwindigkeit der kovalenten Verknüpfung berechnen sie sowohl wie häufig ein fertiger Kopierstrang einen Fehler enthält als auch wie lange das Kopieren dauert. Sie finden, dass starke einseitige Kooperativität und ausreichend rasche Verknüpfungsbildung zusammen die Fehlerrate von einem rein thermodynamischen Ausgangswert von etwa einem Fehler pro Hundert auf rund einen pro Zehntausend senken können — vergleichbar mit dem, was man bei echten DNA-Polymerasen während ihrer „passiven“ Basenwahl-Phase beobachtet, bevor zusätzliche Korrekturmechanismen eingreifen.
Muster, die der echten Biologie ähneln
Bemerkenswerterweise reproduziert dieses reduzierte Modell mehrere Merkmale, die bei der modernen DNA-Replikation beobachtet werden. Wenn eine Fehlpaarung auftritt, verlangsamt sich das simulierte Strangwachstum stark — eine Form des „Stallings“, die auch experimentell gesehen wird. Fehlpaarungen erhöhen die Neigung des Strangendes, sich abzuziehen, und spiegeln so das beobachtete „Fraying“ in echter DNA wider. Das Einfügen eines korrekten Bausteins unmittelbar nach einer Fehlpaarung kann sowohl das Wachstum beschleunigen als auch den Fehler einkapseln, was den gemessenen „next-nucleotide effects“ entspricht, bei denen ein nachfolgendes korrektes Nukleotid einen vorherigen Fehler stabilisieren kann. Das Modell zeigt zudem einen Kompromiss zwischen Geschwindigkeit und Genauigkeit: Zu schwaches oder zu starkes Antreiben der Basenpaarung verschlechtert die Treue, mit einem optimalen Zwischenbereich, in dem Kopieren genau genug, aber nicht zu langsam ist.
Wie einfache Chemie dauerhafte Ordnung schaffen kann
Für einen fachlich nicht spezialisierten Leser ist die Hauptaussage, dass das genaue Kopieren genetischer Information nicht von Anfang an komplexe molekulare Maschinen erfordern muss. Die Autoren zeigen, dass, wenn korrekte Paarungen das Wachstum in eine Richtung fördern und die starken Rückgratbindungen zwischen Einheiten schnell genug gebildet werden, das System dieselbe Energie, die das Wachstum antreibt, nutzen kann, um viele Fehler auszumerzen. Aus dieser Perspektive verfeinern und beschleunigen Enzyme in modernen Zellen hauptsächlich ein grundlegendes physikalisches Prinzip, statt es neu zu erfinden. Dies bietet einen plausiblen Weg, auf dem frühe, enzymfreie genetische Polymere eine ausreichend hohe Kopiergenauigkeit erreicht haben könnten, um Evolution zu ermöglichen, und veranschaulicht allgemeiner, wie dauerhafte molekulare Ordnung aus einfachen, gerichteten Kinetiken in einer energiegetriebenen, aber enzymfreien Welt entstehen kann.
Zitation: Ghosh, K., Sahu, P., Barik, S. et al. Non-enzymatic error correction in self-replicators without extraneous energy supply. Sci Rep 16, 10165 (2026). https://doi.org/10.1038/s41598-026-40325-9
Schlüsselwörter: Ursprung des Lebens, DNA-Replikationsgenauigkeit, nicht-enzymatische Replikation, Fehlerkorrektur, präbiotische Chemie