Clear Sky Science · fr
Correction d’erreurs non enzymatique chez des autoréplicateurs sans apport d’énergie extérieur
Pourquoi il est important de copier le code de la vie sans enzymes
Avant que les cellules n’aient développé leurs machines moléculaires sophistiquées, tout matériel génétique primitif sur Terre a dû se copier en ne comptant que sur une chimie simple. Mais copier de longues chaînes de « lettres » — comme celles de l’ADN et de l’ARN — sans accumuler trop d’erreurs est extrêmement difficile. Cet article examine comment des molécules relativement simples auraient pu se répliquer avec précision, sans enzymes et sans apport d’énergie supplémentaire tel que l’ATP, offrant une voie concrète pour l’émergence et la persistance des premiers systèmes génétiques de la vie.
Une énigme sur les erreurs et l’origine de la vie
Les cellules modernes utilisent des protéines spécialisées pour relire l’ADN et corriger les erreurs, en consommant du combustible chimique pour le faire. Ces enzymes sont toutefois beaucoup trop complexes pour avoir existé sur la Terre primitive. Sans elles, des brins autoréplicatifs primitifs auraient accumulé des erreurs si vite que l’information utile n’aurait pas pu se transmettre d’une génération à l’autre. Les théories existantes supposent soit des communautés de molécules s’entraidant, soit des environnements finement ajustés ou des sources d’énergie supplémentaires. Les auteurs se demandent plutôt : une seule chaîne autoréplicative pourrait-elle corriger ses propres erreurs de copie en n’utilisant que l’énergie qui alimente déjà sa croissance ?
Une poussée unilatérale qui guide la croissance
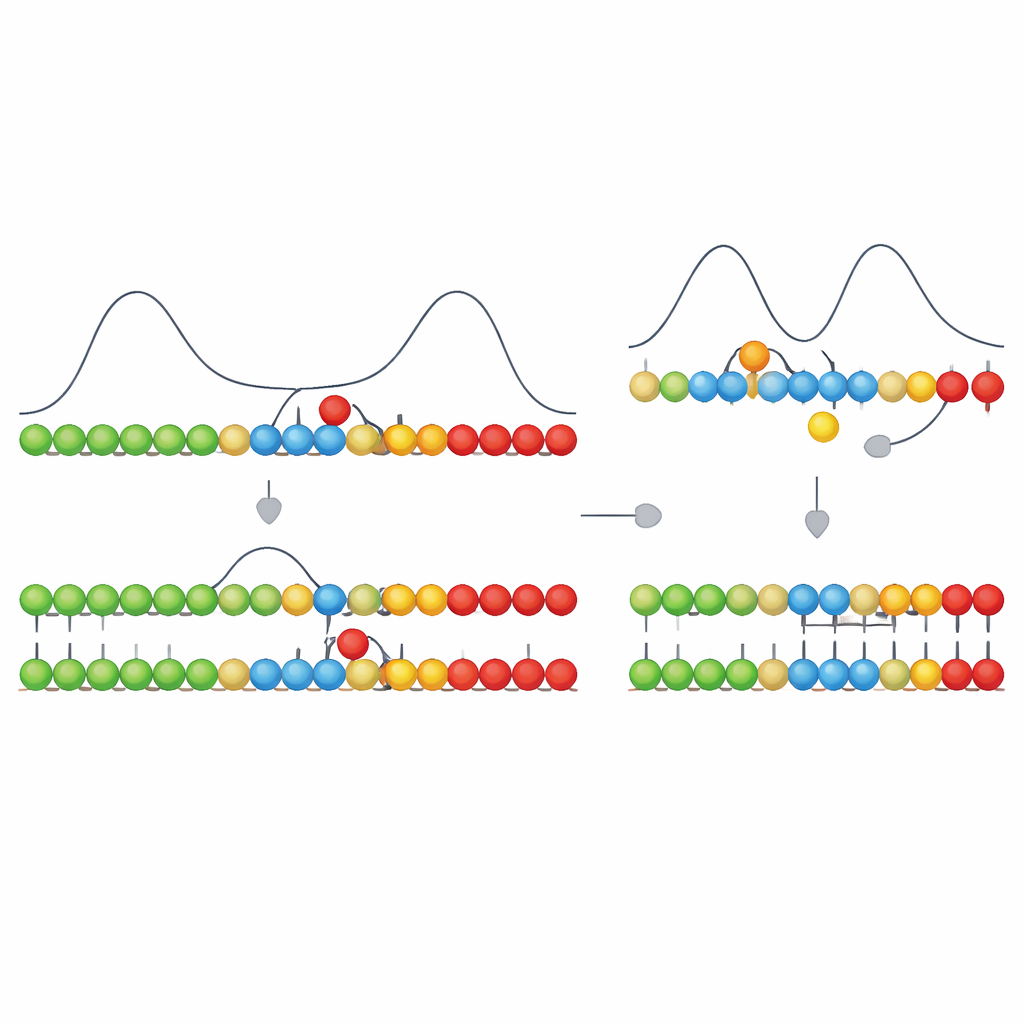
Les auteurs s’appuient sur une caractéristique cinétique qu’ils appellent coopérativité asymétrique. Imaginez un brin matrice où de nouveaux blocs de construction adhèrent brièvement par des liaisons faibles. Quand le bon type de bloc se lie à une position, il facilite la liaison d’un autre bloc d’un côté particulier (par exemple, à droite) et rend plus difficile la rupture de la liaison existante. Du côté opposé, il complique légèrement les choses, poussant effectivement la croissance dans une seule direction le long du matrice. Dans leur modèle, les appariements corrects ont cette influence directionnelle, tandis que les appariements incorrects ne l’ont pas. Cette règle simple fait que les segments correctement appariés croissent rapidement dans une direction, tandis que les mésappariements bloquent la croissance à leur emplacement et déstabilisent les liaisons voisines.
Transformer des différences de timing en moins d’erreurs
Pris isolément, cet arrêt directionnel ne créerait que des différences temporaires : les segments corrects avancent sans heurt ; les segments contenant un mauvais bloc marquent une pause et ont tendance à se dérouler. L’étape clé est que les unités voisines sur le brin en croissance peuvent aussi former des liaisons chimiques fortes et pratiquement irréversibles entre elles. La formation de ces liaisons est fortement favorable en énergie, mais peut être rapide ou lente selon la chimie. Les auteurs montrent que lorsque cette étape de formation de liaison est suffisamment rapide — sur le même ordre de temps que le bref retard causé par un mésappariement — elle « verrouille » préférentiellement les segments qui étaient corrects, avant qu’une unité erronée n’ait le temps de se stabiliser. Si la formation de la liaison est trop lente, tout s’est rééquilibré au moment où la liaison se forme, et le système ne peut plus distinguer le vrai du faux.
Simuler une machine primitive de copie
Pour explorer cette idée, l’équipe considère chaque court matrice comme une chaîne de positions pouvant être non appariées, appariées correctement ou appariées incorrectement. Ils utilisent ensuite un modèle de chaîne de Markov — un outil mathématique standard pour les processus aléatoires pas à pas — pour suivre tous les parcours possibles lors de la formation et de la rupture des paires de bases. En faisant varier le biais directionnel, les vitesses d’appariement et de désappariement, et la rapidité du lien covalent, ils calculent à la fois la fréquence des erreurs dans le brin final copié et la durée de la copie. Ils trouvent qu’une forte coopérativité unidirectionnelle et une formation de liaison suffisamment rapide ensemble peuvent réduire le taux d’erreur d’une base thermique d’environ une erreur sur cent à près d’une sur dix mille, comparable à ce que montrent de véritables ADN polymérases pendant leur stade « passif » de choix de base, avant l’intervention d’un relecture supplémentaire.
Des motifs qui ressemblent à la biologie réelle
De manière remarquable, ce modèle épuré reproduit plusieurs caractéristiques observées dans la réplication de l’ADN moderne. Lorsqu’un mésappariement apparaît, la croissance simulée du brin ralentit nettement — une forme de « blocage » également observée en expérience. Les mésappariements augmentent la tendance de l’extrémité du brin à se détacher, faisant écho au « fraying » observé dans l’ADN réel. Ajouter un bloc correct juste après un mésappariement peut à la fois accélérer la croissance et piéger l’erreur en place, correspondant aux « effets du nucléotide suivant » mesurés où un nucléotide correct ultérieur peut stabiliser une erreur précédente. Le modèle montre aussi un compromis entre vitesse et précision : pousser l’appariement trop faiblement ou trop fortement détériore la fidélité, avec un régime intermédiaire optimal où la copie est suffisamment précise sans être trop lente.
Comment une chimie simple peut créer un ordre durable
Pour un lecteur non spécialiste, le message principal est que la copie fidèle de l’information génétique peut ne pas exiger dès le départ des machines moléculaires complexes. Les auteurs montrent que si les appariements corrects favorisent une croissance directionnelle, et si les liaisons fortes de l’épine dorsale entre unités se forment assez vite, alors le système peut utiliser la même énergie qui alimente la croissance pour éliminer de nombreuses erreurs. Dans cette perspective, les enzymes des cellules modernes affinent et accélèrent surtout un principe physique de base plutôt que de l’inventer ex nihilo. Cela offre une voie plausible par laquelle des polymères génétiques précoces, sans enzymes, auraient pu atteindre une précision de copie suffisante pour soutenir l’évolution, et illustre plus généralement comment un ordre moléculaire durable peut émerger de cinétiques biaisées simples dans un monde mû par l’énergie mais sans enzymes.
Citation: Ghosh, K., Sahu, P., Barik, S. et al. Non-enzymatic error correction in self-replicators without extraneous energy supply. Sci Rep 16, 10165 (2026). https://doi.org/10.1038/s41598-026-40325-9
Mots-clés: origine de la vie, fidélité de la réplication de l’ADN, réplication non enzymatique, correction d’erreurs, chimie prébiotique