Clear Sky Science · es
Corrección de errores no enzimática en autorreplicadores sin suministro energético externo
Por qué importa copiar el código de la vida sin enzimas
Antes de que las células desarrollaran sus sofisticadas máquinas moleculares, cualquier material genético primitivo en la Tierra tuvo que copiarse usando solo química simple. Pero copiar largas cadenas de "letras", como las del ADN y el ARN, sin cometer demasiados errores es extremadamente difícil. Este artículo explora cómo moléculas relativamente sencillas podrían haberse copiado con exactitud, sin enzimas y sin un suministro adicional de combustible como el ATP, ofreciendo una vía concreta para que los primeros sistemas genéticos de la vida surgieran y se mantuvieran.
Un rompecabezas sobre errores y el origen de la vida
Las células modernas usan proteínas especializadas para corregir el ADN y reparar errores, consumiendo combustible químico para ello. Esas enzimas, sin embargo, son demasiado complejas para haber existido en la Tierra primitiva. Sin ellas, las hebras autorreplicantes primitivas acumularían errores tan rápido que la información útil no podría conservarse de una generación a la siguiente. Las teorías existentes o bien suponen comunidades de moléculas que se ayudan mutuamente, o dependen de entornos finamente ajustados o fuentes de energía externas. Los autores plantean en cambio: ¿podría una única cadena autorreplicante corregir sus propios errores de copia usando solo la energía que ya impulsa su crecimiento?
Un empujón unilateral que guía el crecimiento
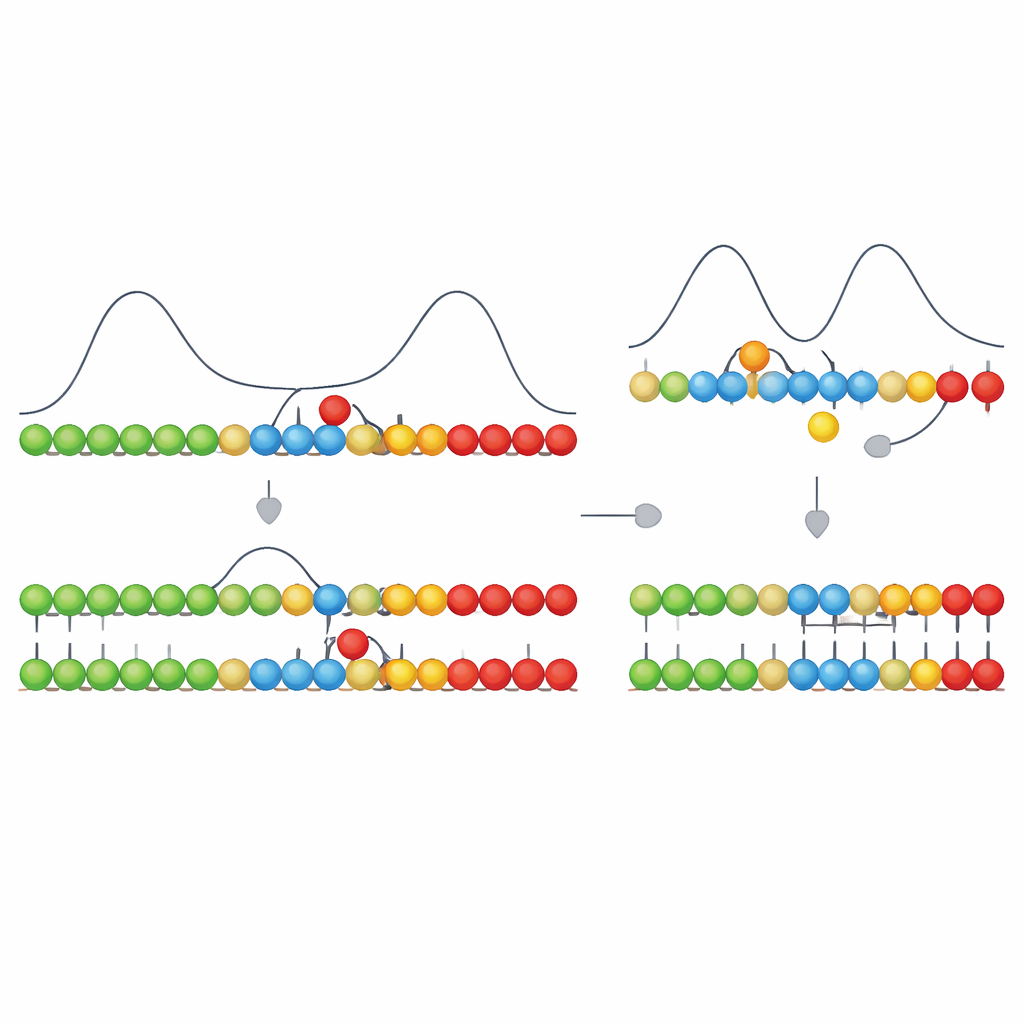
Los autores se basan en una característica cinética que denominan cooperatividad asimétrica. Imagínese una hebra plantilla con nuevos bloques constructores que se adhieren brevemente por enlaces débiles. Cuando el bloque correcto se une en una posición, facilita que otro bloque se una en un lado concreto (por ejemplo, a la derecha) y dificulta que el enlace existente se desarme. En el lado opuesto, lo vuelve algo más difícil, empujando efectivamente el crecimiento en una sola dirección a lo largo de la plantilla. En su modelo, los emparejamientos correctos tienen esta influencia direccional, mientras que los incorrectos no. Esta regla simple hace que los tramos correctamente apareados crezcan rápidamente en una dirección, mientras que los desajustes detienen el crecimiento en su ubicación y desestabilizan enlaces cercanos.
Convertir diferencias de tiempo en menos errores
Por sí sola, esta detención direccional solo crearía diferencias temporales: los segmentos correctos avanzan con fluidez; los segmentos con un bloque erróneo se detienen y tienden a desenrollarse. El paso clave es que las unidades vecinas en la hebra en crecimiento también pueden formar enlaces químicos fuertes y casi irreversibles entre sí. Formar estos enlaces implica una gran caída energética, pero puede ser rápido o lento según la química. Los autores muestran que cuando este paso de formación de enlaces es lo bastante rápido —en la misma escala temporal que el breve retraso causado por un desajuste— favorecerá ‘congelar’ los tramos que por casualidad eran correctos, antes de que una unidad errónea tenga tiempo de estabilizarse. Si la formación de enlaces es demasiado lenta, todo vuelve a reequilibrarse para cuando se forma el enlace y el sistema ya no puede distinguir lo correcto de lo incorrecto.
Simulando una máquina de copiado primitiva
Para explorar la idea, el equipo trata cada plantilla corta como una cadena de posiciones que pueden estar sin emparejar, emparejadas correctamente o emparejadas incorrectamente. Luego utilizan un modelo de cadena de Markov —una herramienta matemática estándar para procesos aleatorios paso a paso— para seguir todos los caminos posibles mientras pares de bases se forman y se rompen. Variando el sesgo direccional, las velocidades de emparejamiento y desparejamiento, y la rapidez del enlace covalente, calculan tanto la frecuencia con la que una hebra copiada final contiene un error como el tiempo que tarda la copia. Encuentran que una cooperatividad unidireccional fuerte y una formación de enlaces suficientemente rápida pueden reducir la tasa de errores desde una línea base termodinámica de aproximadamente un error por cien a alrededor de uno por diez mil, comparable a lo observado en las polimerasas de ADN reales durante su etapa de selección pasiva de bases, antes de que actúen mecanismos adicionales de corrección.
Patrones que recuerdan a la biología real
De manera notable, este modelo simplificado reproduce varias características observadas en la copia moderna del ADN. Cuando aparece un desajuste, el crecimiento simulado de la hebra se ralentiza marcadamente —una forma de “stalling” también observada en experimentos. Los desajustes aumentan la tendencia del extremo de la hebra a despegarse, evocando el “fraying” detectado en ADN real. Añadir un bloque correcto justo después de un desajuste puede tanto acelerar el crecimiento como atrapar el error en su lugar, coincidiendo con los efectos medidos del “nucleótido siguiente” donde un nucleótido correcto posterior puede estabilizar un error previo. El modelo también muestra una compensación entre velocidad y exactitud: impulsar el emparejamiento de bases demasiado débil o demasiado fuerte empeora la fidelidad, con un régimen intermedio óptimo donde la copia es lo bastante precisa y no demasiado lenta.
Cómo la química simple puede construir orden duradero
Para el lector no especialista, el mensaje principal es que copiar información genética con precisión puede no requerir desde el principio máquinas moleculares complejas. Los autores muestran que si las coincidencias correctas ayudan a que el crecimiento avance en una dirección, y si los fuertes enlaces de la columna vertebral entre unidades se forman con suficiente rapidez, entonces el sistema puede usar la misma energía que impulsa el crecimiento para eliminar muchos errores. En esta visión, las enzimas de las células modernas refinan y aceleran un principio físico básico más que inventarlo de cero. Esto ofrece una vía plausibLe por la cual polímeros genéticos primitivos, sin enzimas, podrían haber alcanzado una precisión de copia suficiente para permitir la evolución, e ilustra más ampliamente cómo puede surgir un orden molecular duradero a partir de cinéticas sesgadas simples en un mundo impulsado por la energía pero sin enzimas.
Cita: Ghosh, K., Sahu, P., Barik, S. et al. Non-enzymatic error correction in self-replicators without extraneous energy supply. Sci Rep 16, 10165 (2026). https://doi.org/10.1038/s41598-026-40325-9
Palabras clave: origen de la vida, fidelidad de la replicación del ADN, replicación no enzimática, corrección de errores, química prebiótica