Clear Sky Science · en
Non-enzymatic error correction in self-replicators without extraneous energy supply
Why copying life’s code without enzymes matters
Before cells evolved their sophisticated molecular machines, any early genetic material on Earth had to copy itself using only simple chemistry. But copying long chains of "letters"—like those in DNA and RNA—without making too many mistakes is extremely hard. This paper explores how relatively simple molecules could have copied themselves accurately, without enzymes and without an extra fuel supply such as ATP, offering a concrete route for life’s first genetic systems to emerge and persist.
A puzzle about mistakes and the origin of life
Modern cells use specialized proteins to proofread DNA and fix errors, burning chemical fuel to do so. Those enzymes, however, are far too complex to have existed on the early Earth. Without them, primitive self-copying strands would have accumulated errors so quickly that useful information could not be maintained from one generation to the next. Existing theories either assume communities of mutually helping molecules, or rely on finely tuned environments or extra energy sources. The authors instead ask: could a single self-replicating chain correct its own copying mistakes using only the energy that already drives its growth?
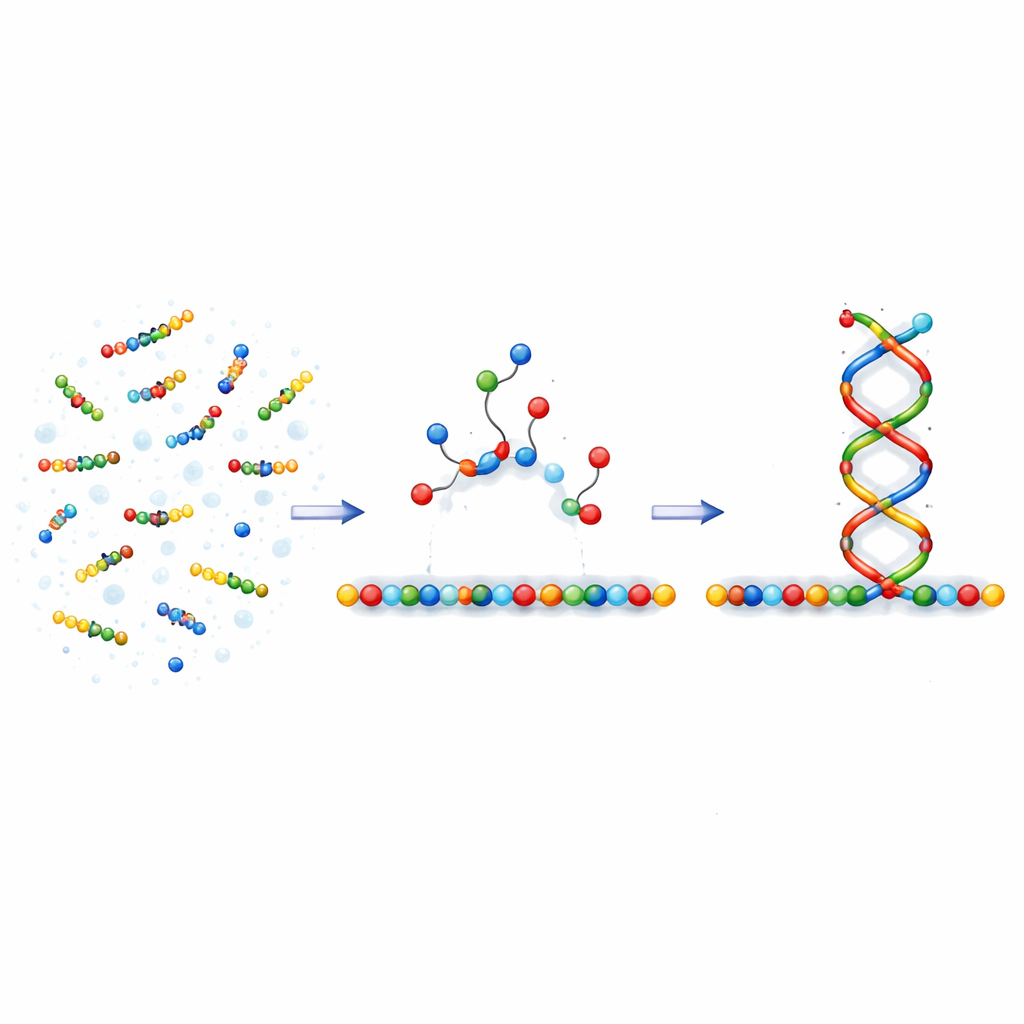
A one-sided push that guides growth
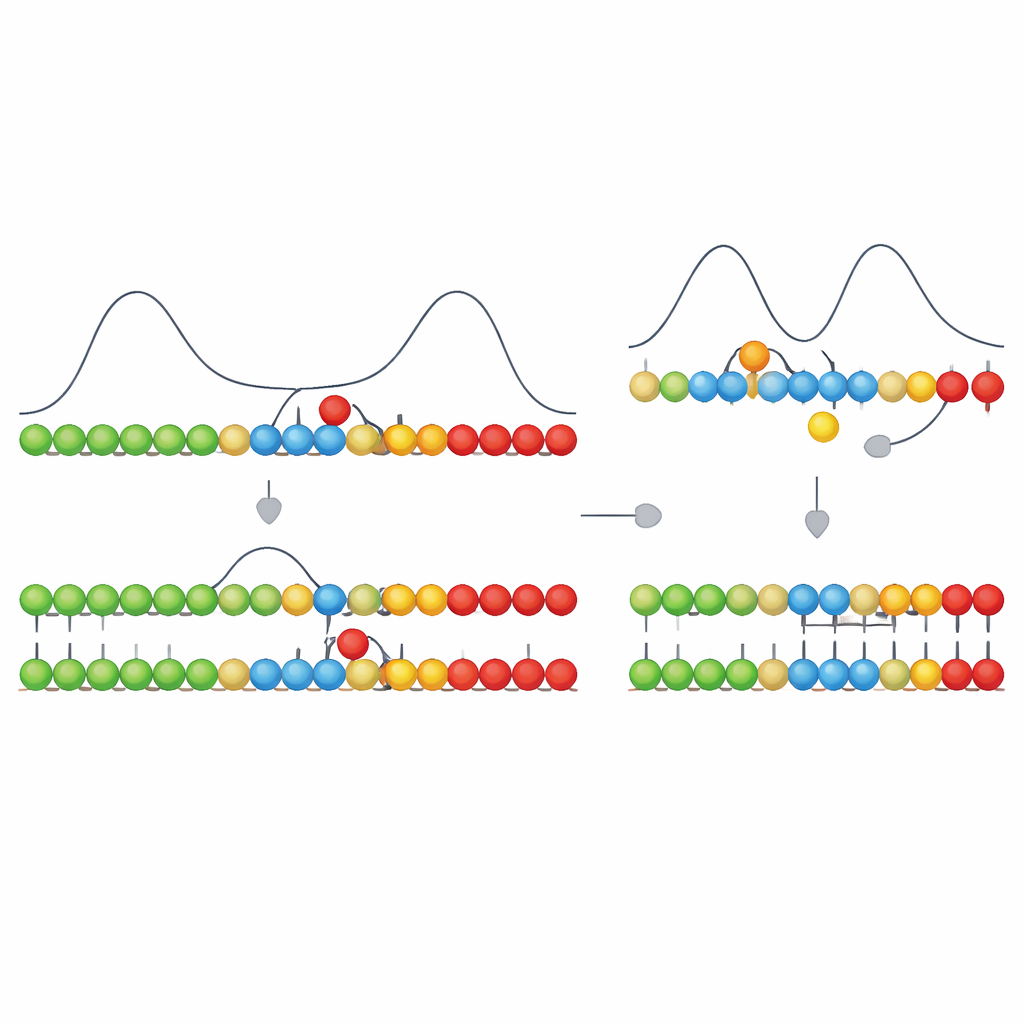
The authors build on a kinetic feature they call asymmetric cooperativity. Imagine a template strand with new building blocks briefly sticking to it by weak bonds. When the right kind of block binds in one position, it makes it easier for another block to bind on one particular side (say, to the right) and harder for that existing bond to fall apart. On the opposite side, it makes things slightly harder, effectively pushing growth in a single direction along the template. In their model, correct pairings have this directional influence, while incorrect ones do not. This simple rule makes properly matched stretches grow quickly in one direction, while mismatches stall growth at their location and destabilize nearby bonds.
Turning timing differences into fewer errors
On its own, this directional stalling would only create temporary differences: correct segments advance smoothly; segments with a wrong building block pause and tend to unwind. The key step is that neighboring units on the growing strand can also form strong, nearly irreversible chemical links with each other. Forming these links is highly downhill in energy, but can be fast or slow depending on the chemistry. The authors show that when this link-forming step is fast enough—on the same timescale as the brief delay caused by a mismatch—it will preferentially "lock in" stretches that happened to be correct, before a wrong unit has time to become stabilized. If link formation is too slow, everything has re-equilibrated by the time a link forms, and the system can no longer tell right from wrong.
Simulating a primitive copying machine
To explore this idea, the team treats each short template as a chain of positions that can be unpaired, correctly paired, or incorrectly paired. They then use a Markov chain model—a standard mathematical tool for random step-by-step processes—to follow all possible paths as base pairs form and break. By varying the directional bias, the rates of pairing and unpairing, and the speed of covalent linking, they calculate both how often a final copied strand contains an error and how long copying takes. They find that strong one-way cooperativity and sufficiently rapid link formation together can push the error rate down from a purely thermodynamic baseline of about one error in a hundred to around one in ten thousand, comparable to what is seen in real DNA polymerases during their "passive" base choice stage, before extra proofreading kicks in.
Patterns that resemble real biology
Remarkably, this stripped-down model reproduces several features observed in modern DNA copying. When a mismatch appears, simulated strand growth slows sharply—a form of "stalling" also seen in experiments. Mismatches lead to an increased tendency for the end of the strand to peel away, echoing observed "fraying" in real DNA. Adding a correct building block right after a mismatch can both speed up growth and trap the error in place, matching measured "next-nucleotide effects" where a subsequent correct nucleotide can stabilize a previous mistake. The model also shows a trade-off between speed and accuracy: driving base pairing too weakly or too strongly both worsen fidelity, with an optimal intermediate regime where copying is accurate enough yet not too slow.
How simple chemistry can build lasting order
To a lay reader, the main message is that copying genetic information accurately may not require complex molecular machines from the outset. The authors show that if correct matches help growth proceed in one direction, and if the strong backbone bonds between units form quickly enough, then the system can use the same energy that drives growth to weed out many mistakes. In this view, enzymes in modern cells mainly refine and accelerate a basic physical principle rather than inventing it from scratch. This offers a plausible pathway by which early, enzyme-free genetic polymers could have achieved high enough copying accuracy to support evolution, and illustrates more broadly how durable molecular order can arise from simple, biased kinetics in an energy-driven but enzyme-free world.
Citation: Ghosh, K., Sahu, P., Barik, S. et al. Non-enzymatic error correction in self-replicators without extraneous energy supply. Sci Rep 16, 10165 (2026). https://doi.org/10.1038/s41598-026-40325-9
Keywords: origin of life, DNA replication fidelity, non-enzymatic replication, error correction, prebiotic chemistry