Clear Sky Science · pl
Nieenzymatyczna korekcja błędów w samo-replikatorach bez zewnętrznego dopływu energii
Dlaczego istotne jest kopiowanie kodu życia bez enzymów
Zanim komórki wyewoluowały swoje wyspecjalizowane molekularne maszyny, każde wczesne materiał genetyczny na Ziemi musiał kopiować się używając jedynie prostej chemii. Jednak kopiowanie długich łańcuchów „liter” — takich jak w DNA i RNA — bez popełniania zbyt wielu błędów jest ekstremalnie trudne. Artykuł ten bada, jak stosunkowo proste cząsteczki mogły kopiować same siebie dokładnie, bez enzymów i bez dodatkowego źródła paliwa takiego jak ATP, proponując konkretną drogę, dzięki której pierwsze systemy genetyczne życia mogły się pojawić i utrzymać.
Zagadka błędów i pochodzenia życia
Współczesne komórki używają wyspecjalizowanych białek do korekty DNA i naprawy błędów, zużywając w tym celu paliwo chemiczne. Te enzymy są jednak zbyt złożone, by mogły istnieć na wczesnej Ziemi. Bez nich prymitywne samokopiujące się łańcuchy szybko gromadziłyby błędy, przez co użyteczna informacja nie mogłaby być zachowana z pokolenia na pokolenie. Istniejące teorie albo zakładają wspólnoty wzajemnie sobie pomagających cząsteczek, albo opierają się na precyzyjnie dobranych warunkach środowiskowych czy dodatkowych źródłach energii. Autorzy pytają zamiast tego: czy pojedynczy samo-replikujący się łańcuch mógłby skorygować własne błędy kopiowania, używając jedynie energii, która już napędza jego wzrost?
Jednostronne pchanie, które kieruje wzrostem
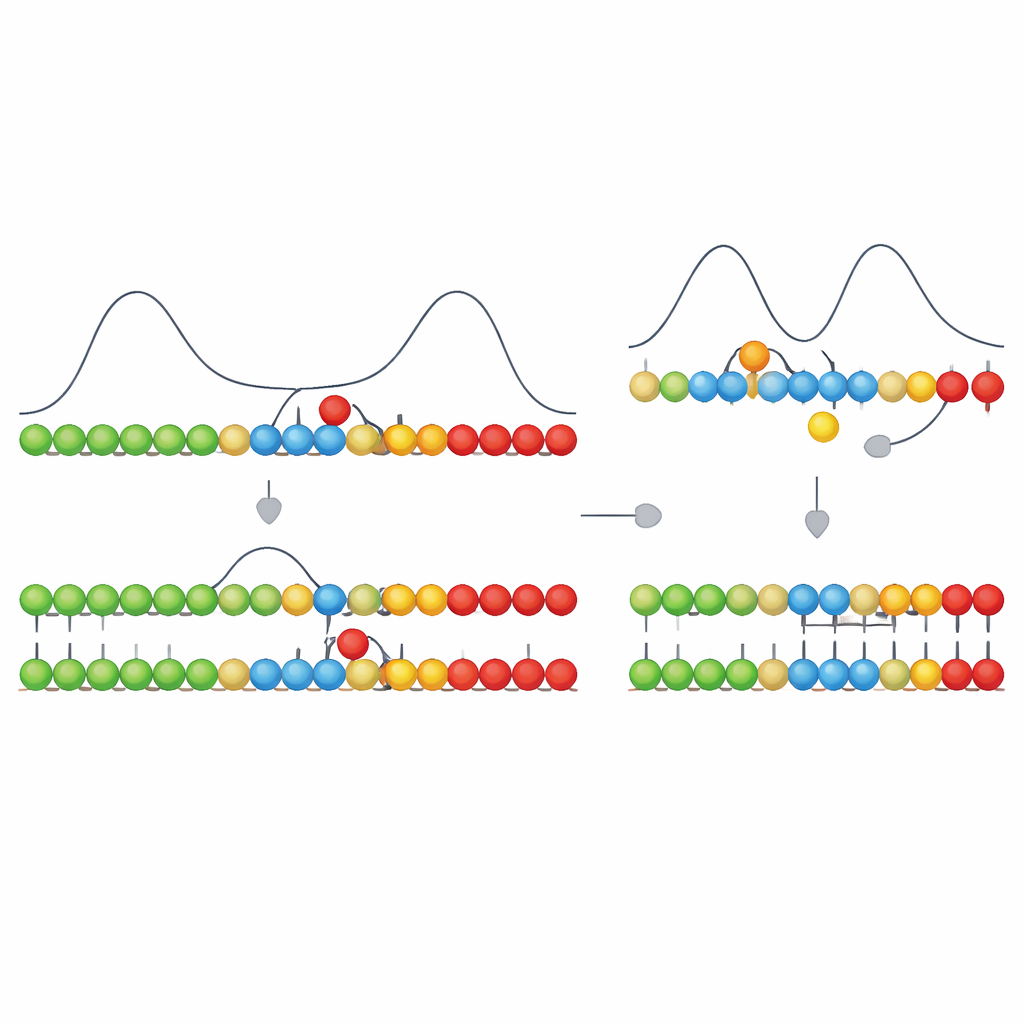
Autorzy opierają się na kinetycznej cesze, którą nazywają asymetryczną kooperatywnością. Wyobraźmy sobie matrycowy łańcuch, do którego nowe cegiełki przyczepiają się chwilowo słabymi wiązaniami. Gdy we właściwej pozycji przyłączy się właściwa cegiełka, ułatwia to przyłączenie kolejnej cegiełki po jednej konkretnej stronie (np. po prawej) i utrudnia zerwanie istniejącego wiązania. Po przeciwnej stronie wpływ jest odwrotny, co efektywnie popycha wzrost w jednym kierunku wzdłuż matrycy. W ich modelu poprawne parowania mają taki kierunkowy wpływ, podczas gdy niepoprawne nie. Ta prosta zasada sprawia, że poprawnie sparowane odcinki rosną szybko w jednym kierunku, podczas gdy niezgodności zatrzymują wzrost w swoim miejscu i destabilizują pobliskie wiązania.
Przekształcanie różnic w czasie w mniejszą liczbę błędów
Sama w sobie ta kierunkowa pauza stworzyłaby tylko przejściowe różnice: poprawne segmenty posuwają się płynnie naprzód; segmenty z błędną cegiełką zatrzymują się i mają skłonność do rozplecenia. Kluczowy krok polega na tym, że sąsiednie jednostki na rosnącym łańcuchu mogą także utworzyć silne, niemal nieodwracalne wiązania chemiczne między sobą. Tworzenie tych wiązań jest silnie „spadkowe” energetycznie, lecz może przebiegać szybko lub wolno w zależności od chemii. Autorzy wykazują, że gdy etap tworzenia tych wiązań jest wystarczająco szybki — w tym samym zakresie czasowym co krótka zwłoka spowodowana niezgodnością — preferencyjnie „zablokuje” odcinki, które akurat były prawidłowe, zanim błędna jednostka zdąży się ustabilizować. Jeśli tworzenie wiązań jest zbyt wolne, wszystko zdąży ponownie wyrównać się zanim wiązanie powstanie i system nie będzie już potrafił rozróżnić prawidłowego od błędnego.
Symulacja prymitywnej maszyny kopiującej
Aby zbadać ten pomysł, zespół traktuje każdą krótką matrycę jako łańcuch pozycji, które mogą być niesparowane, poprawnie sparowane lub błędnie sparowane. Następnie używają modelu łańcucha Markowa — standardowego narzędzia matematycznego do losowych, krokowych procesów — aby śledzić wszystkie możliwe ścieżki, gdy pary zasad się tworzą i zrywają. Zmieniaj¹c kierunkowy bias, szybkości parowania i rozparowania oraz szybkość tworzenia kowalencyjnego łańcucha, obliczają zarówno jak często finalny skopiowany łańcuch zawiera błąd, jak i ile trwa kopiowanie. Stwierdzają, że silna jednostronna kooperatywność i wystarczająco szybkie tworzenie wiązań razem mogą zmniejszyć wskaźnik błędów z czysto termodynamicznego poziomu ok. jednego błędu na sto do rzędu jednego na dziesięć tysięcy — porównywalnego z tym, co obserwuje się w rzeczywistych polimerazach DNA podczas ich „pasywnego” etapu wyboru zasad, zanim włączone zostaną dodatkowe mechanizmy korekty.
Wzorce przypominające prawdziwą biologię
Co zaskakujące, ten uproszczony model odtwarza kilka cech obserwowanych przy nowoczesnym kopiowaniu DNA. Gdy pojawia się niezgodność, symulowany wzrost łańcucha wyraźnie zwalnia — forma „zatrzymywania”, także obserwowana w eksperymentach. Niezgodności zwiększają skłonność końca łańcucha do odwijania się, co przypomina obserwowane „strzępienie” (fraying) prawdziwego DNA. Dodanie poprawnej cegiełki tuż po niezgodności może zarówno przyspieszyć wzrost, jak i uwięzić błąd na miejscu, odpowiadając mierzonym „efektom następnego nukleotydu”, gdzie kolejny poprawny nukleotyd stabilizuje wcześniejszy błąd. Model pokazuje też kompromis między szybkością a dokładnością: zbyt słabe lub zbyt silne napędzanie parowania zasad pogarsza wierność, przy czym istnieje optymalny reżim pośredni, w którym kopiowanie jest wystarczająco dokładne, a jednocześnie niezbyt wolne.
Jak prosta chemia może budować trwały porządek
Dla czytelnika niebędącego specjalistą główne przesłanie jest takie, że dokładne kopiowanie informacji genetycznej może nie wymagać od początku skomplikowanych maszyn molekularnych. Autorzy pokazują, że jeśli poprawne dopasowania ułatwiają wzrost w jednym kierunku, a silne wiązania między jednostkami tworzą się wystarczająco szybko, system może wykorzystać tę samą energię, która napędza wzrost, by odsiać wiele błędów. Z tej perspektywy enzymy we współczesnych komórkach głównie udoskonalają i przyspieszają podstawową zasadę fizyczną, zamiast wynajdywać ją od zera. To przedstawia wiarygodną ścieżkę, dzięki której wczesne, wolne od enzymów polimery genetyczne mogły osiągnąć na tyle wysoką dokładność kopiowania, by wspierać ewolucję, i pokazuje szerzej, jak trwały porządek molekularny może powstać z prostych, uprzedzonych kinetyk w świecie napędzanym energią, ale pozbawionym enzymów.
Cytowanie: Ghosh, K., Sahu, P., Barik, S. et al. Non-enzymatic error correction in self-replicators without extraneous energy supply. Sci Rep 16, 10165 (2026). https://doi.org/10.1038/s41598-026-40325-9
Słowa kluczowe: pochodzenie życia, dokładność replikacji DNA, nieenzymatyczna replikacja, korekcja błędów, chemia prebiotyczna