Clear Sky Science · tr
Öbek ve cümle uzunluklarının olasılıksal dağılımları çeviri yönlerini ayırt edebilir mi?
Çeviride Cümle Uzunluğunun Neden Önemli Olduğu
Bir çeviri öyküyü okuduğumuzda, metnin küçük yapı taşları—her bir cümlenin ya da ödümün uzunluğu, belirli uzunlukların ne sıklıkla ortaya çıktığı—üzerinde nadiren dururuz. Oysa bu örüntüler kim çeviriyi yaptı ve çeviri hangi yöne yapıldı—ana dile mi yoksa ikinci dile mi—konusunda örtük ipuçları verebilir. Bu makale, cümle ve ödüm uzunluklarının istatistiksel parmak izlerinin, basit ortalamalardan daha güvenilir biçimde çeviri yönlerini ayırt edip edemeyeceğini araştırıyor ve çevrilmiş dilin sıradan yazından nasıl farklılaştığına dair yeni bir bakış sunuyor.
Basit Ortalamaların Ötesine Bakmak
On yıllardır araştırmacılar cümle uzunluğunu yazı stili, yazar kimliği ve hatta tür hakkında kaba bir gösterge olarak kullandı. Erken çalışmalar cümle başına ortalama sözcük sayısı gibi temel ölçütlere odaklandı, ancak bunlar tartışmalı bir metnin yazarını belirlemek gibi soruları çözmede genellikle yeterince incelikli değildi. Daha yakın tarihli çalışmalar, kısa, orta ve uzun cümlelerin ne sıklıkla ortaya çıktığını gösteren tam dağılımlara yönelerek daha ince örüntüleri ortaya çıkardı. Bu çalışma da dağılımsal yaklaşımı çeviribilim alanına taşıyor ve çeviri yönü—kişinin ana diline (L1) çeviri ile ikinci dile (L2) çeviri arasındaki uzun tartışmayı—açığa çıkarıp çıkaramayacağını soruyor.
Dikkatle Eşlenen Bir Öykü Seti
Bu fikri test etmek için yazarlar, etkili Çinli yazar Lu Xun’un on kısa öyküsü üzerine sıkı kontrol edilmiş bir derleme oluşturdu. Her öykünün birden fazla İngilizce çevirisi vardı ve bunlar dört yetkin çevirmen tarafından yapılmıştı. İkisi Çince’den İngilizce’ye çevirirken ana dili İngilizce olan çevirmenlerdi (ana dile, L1 çeviri); diğer ikisi ise ana dili Çince olup İngilizce’ye çeviri yapanlar olarak (ikinci dile, L2 çeviri) yer aldı. Araştırmacılar özel bilgisayar betikleriyle İngilizce metinleri cümlelere ve ödümler adı verilen daha kısa birimlere ayırıp her birinin kaç sözcük içerdiğini saydı. Basit ortalamaları hesapladılar ama daha önemlisi, nicel dilbilimden yerleşik olasılıksal dağılımları kullanarak uzunlukların tüm yayılımını modellediler.
Cümle Örüntüleri Ne Anlatıyor
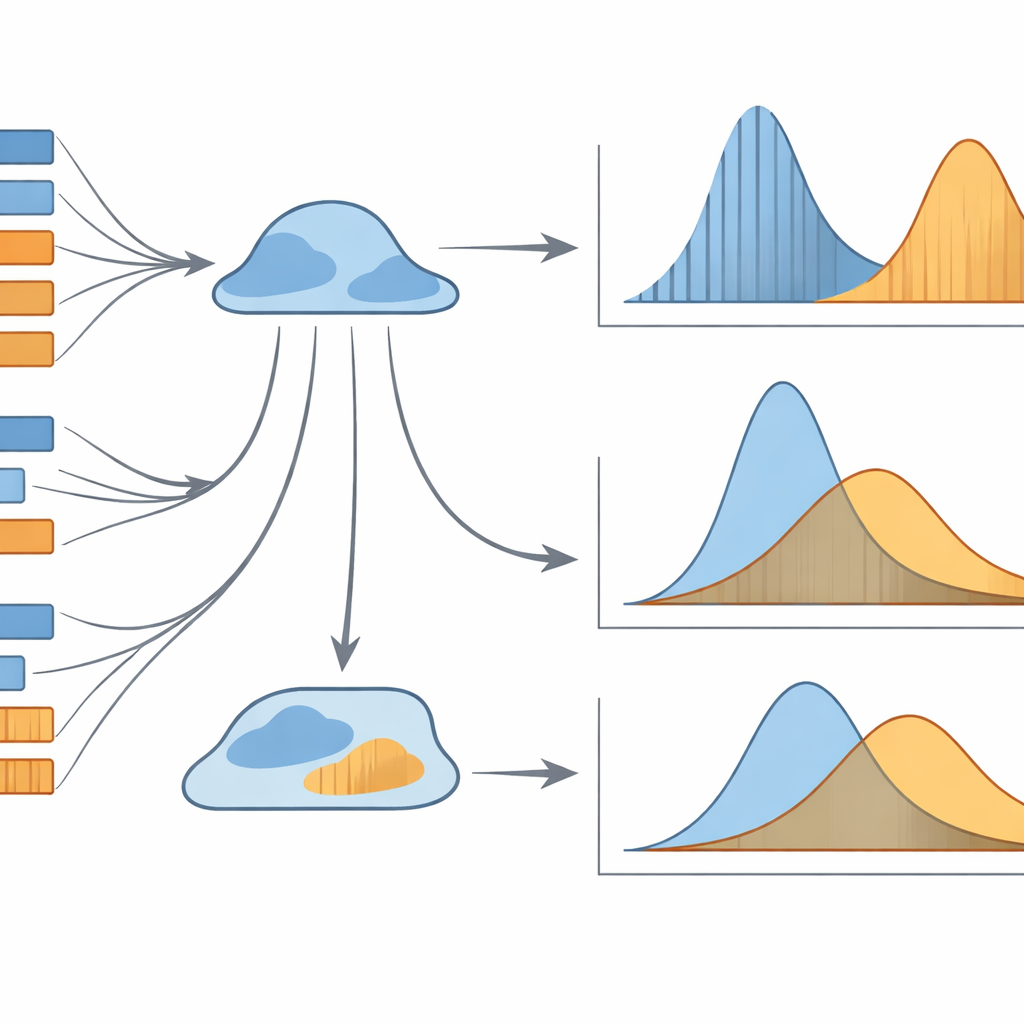
İlk şaşırtıcı bulgu, ortalama cümle uzunluğunun L1 ve L2 çevirilerde neredeyse aynı olması ve istatistiksel testlerin anlamlı bir fark göstermemesi. Yüzeyde, her iki çevirmen grubu da benzer genel uzunlukta cümleler üretiyor. Ancak yazarlar cümle uzunluklarının nasıl dağıldığını incelediklerinde gizli karşıtlıklar ortaya çıkıyor. Cümleleri bantlara (örneğin 1–5 sözcük, 6–10 sözcük vb.) ayırıp Genişletilmiş Pozitif Negatif Binom modeli gibi sofistike bir dağılımı uydurduklarında, modelin iki parametresi L1 ve L2 çeviriler arasında tutarlı biçimde farklılık gösteriyor. Basitçe söylemek gerekirse, her iki yön de orta uzunluktaki cümleleri tercih ediyor ama “tepe”nin tam şekli ve çok kısa ya da çok uzun cümlelere doğru frekansların nasıl azaldığı, çevirinin hangi yöne yapıldığına dair güçlü ipuçları barındırıyor.
Ödüm Örüntülerinin Katkısı
Cümlelerin içindeki daha küçük birimler olan ödümler daha ince bir tablo sunuyor. Burada ortalama uzunluk farklılık gösteriyor: ikinci dile yapılan çevirilerde ödümler biraz daha uzun ve daha değişken olma eğiliminde. Yine de bu ortalamalar her çevirmenin kişisel tarzından güçlü biçimde etkileniyor ve yön sınıflandırması açısından sınırlı kullanım sağlıyor. Yazarlar ödüm uzunluklarının sıra–frekans örüntüsünü (en yaygın uzunluğun ne kadar sık olduğu, sonra ikinci en yaygın olanın frekansı vb.) incelediklerinde ve Hyperpoisson adlı bir dağılımı uydurduklarında, model parametreleri çeviri yönüne karşı son derece duyarlı çıkıyor ve aynı zamanda bireysel stil izlerini yakalıyor. Buna karşılık ödüm uzunluğunu başka bir açıdan—Shenton–Skees–geometric modeliyle uydurulmuş uzunluk–frekans örüntüsünü—incelediklerinde, parametreler yönleri iyi ayırt edemiyor; yine de çevirmenler arasındaki stilistik farklılıkları yansıtıyorlar.
Bu Gizli Örüntüler Neden Önemli
Genel olarak çalışma, cümle ya da ödüm uzunluğunun basit ortalamalarının çeviriyi anlamada kaba araçlar olduğunu gösteriyor. En bilgi verici sinyal, uzunluk örüntülerinin tam olasılıksal şekli oluyor. Özellikle iki birleşim öne çıkıyor: cümle uzunluklarının uzunluk–frekans dağılımı ve ödüm uzunluklarının sıra–frekans dağılımı. Bu modeller birlikte bir çevirinin ana dile mi yoksa ikinci dile mi yapıldığını güvenilir biçimde söyleyebiliyor; metinler yüzeyde benzer görünse bile. Uzman olmayanlar için çıkarım, çevirilerin nasıl üretildiğine dair ince istatistiksel izler taşıdığı—insanların doğrudan hissetmese bile bilgisayarların okuyabileceği izler—oluyor. Bu teknikler sonunda çeviri kalitesinin değerlendirilmesine, çevirmen stillerinin profillenmesine veya insanla makine çevirisinin ayrılmasına yardımcı olabilir ve dilin diller arasında hareket ettiğinde nasıl davrandığına dair anlayışımızı derinleştirebilir.
Atıf: Zhan, J., Fu, Y. & Jiang, Y. Can probabilistic distributions of sentence and clause lengths differentiate between translation directions?. Humanit Soc Sci Commun 13, 412 (2026). https://doi.org/10.1057/s41599-026-06737-8
Anahtar kelimeler: çeviri yönü, cümle uzunluğu dağılımı, ödüm uzunluğu, nicel dilbilim, Lu Xun çevirileri