Clear Sky Science · he
האם התפלגויות הסתברותיות של אורכי משפטים וסעיפים יכולות להבחין בכיווני תרגום?
מדוע אורך המשפטים בתרגום חשוב
כשאנחנו קוראים סיפור מתורגם, לרוב אנחנו לא עוצרים לחשוב על יחידות הבנייה הזעירות של הטקסט: כמה ארוך כל משפט או סעיף, או כמה לעיתים מופיעים אורכים מסוימים. עם זאת, דפוסים אלה יכולים בעדינות לחשוף מי מבצע את התרגום ובאיזה כיוון הוא נע — אל שפת האם של המתרגם או אל שפה שנייה. מאמר זה בוחן האם טביעות אצבע סטטיסטיות של אורכי משפטים וסעיפים יכולות להבחין בין כיווני תרגום בדיוק רב יותר מאשר ממוצעים פשוטים, ומציע עדשה חדשה להבנת ההבדלים בין שפה מתורגמת לכתיבה רגילה.
מעבר לממוצעים פשוטים
עשרות שנים חוקרים השתמשו באורך המשפט כאינדיקטור גס לסגנון הכתיבה, לזהות המחבר ואפילו למגדר. מחקרים מוקדמים התמקדו במדדים בסיסיים כגון מספר המילים הממוצע למשפט, אך אלה לעתים קרובות היו גסים מדי כדי להכריע בשאלות כמו מי כתב טקסט שנוי במחלוקת. עבודה מודרנית יותר פנתה להתפלגויות מלאות — כמה לעיתים מופיעים משפטים קצרים, בינוניים וארוכים — כדי לחשוף דפוסים עדינים יותר. המחקר הנוכחי מתבסס על גישה התפלגותית זו בתחום חקר התרגום, ובוחן האם היא יכולה להאיר סוגיה שנויה במחלוקת: תרגום לשפת האם (L1) לעומת תרגום לשפה שנייה (L2).
סט סיפוריו תואם בקפידה
כדי לבחון את הרעיון בנינו קורפוס מבוקר היטב המבוסס על עשר סיפורים קצרים של הסופר הסיני המשפיע לו שון. לכל סיפור קיימות מספר תרגומים לאנגלית שבוצעו על ידי ארבעה מתרגמים מיומנים מאוד. שניים הם דוברי אנגלית ילידיים המתרגמים מהסינית (תרגום ל-L1 — לשפת האם שלהם), ושניים הם דוברי סינית ילידים המתרגמים לאנגלית (תרגום ל-L2 — לשפה שנייה). בעזרת סקריפטים ממוחשבים מותאמים חלקו החוקרים את הטקסטים האנגליים למשפטים וליחידות קטנות יותר הנקראות סעיפים, ואחר כך ספרו כמה מילים מכיל כל אחד. הם חישבו ממוצעים פשוטים אך, החשוב יותר, התוו את טווח האורכים המלא באמצעות מודלים הסתברותיים מבוססים מבלשנות כמותית.
מה דפוסי המשפטים מגלים
ההפתעה הראשונה היא שאורך המשפט הממוצע כמעט זהה בתרגומי L1 ו-L2, ובדיקות סטטיסטיות אינן מראות הבדלים משמעותיים. במבט שטחי, שתי קבוצות המתרגמים מייצרות משפטים באורך דומה. עם זאת, כאשר החוקרים בוחנים כיצד אורכי המשפטים מתפלגים, מתגלים ניגודים חבויים. כאשר הם מקבצים משפטים לטווחים (לדוגמה, 1–5 מילים, 6–10 מילים וכדומה) ומתאימים מודל מתוחכם הידוע כ-Extended Positive Negative Binomial, שני פרמטרים של המודל שונים בעקביות בין תרגומי L1 ל-L2. במילים פשוטות, שני הכיוונים מעדיפים משפטים באורך בינוני, אך הצורה המדויקת של ה"גבעה" ואופן הצטמצמות התדירויות לכיוון משפטים קצרים מאוד או ארוכים מאוד מקודדים רמזים חזקים לגבי כיוון התרגום.
מה שסעיפים מוסיפים
סעיפים, היחידות הקטנות בתוך המשפטים, מספרים סיפור מפורט יותר. כאן האורך הממוצע כן שונה: תרגומים לשפה שנייה נוטים להכיל סעיפים מעט ארוכים יותר ובעליהם יותר שונות. עם זאת, ממוצעים אלה מושפעים בחוזקה מהסגנון האישי של כל מתרגם, מה שמגביל את תוחלתם כמיון לפי כיוון. כאשר החוקרים בודקים את דפוס המיקום-תדירות של אורכי הסעיפים (כמה פעמים מופיע האורך הנפוץ ביותר, אחר כך השני בחשיבותו, וכן הלאה) ומתאימים מודל הנקרא Hyperpoisson, פרמטרי המודל רגישים מאוד לכיוון התרגום ובו בזמן לוכדים טביעות סגנוניות אישיות. לעומת זאת, כאשר הם מביטים באורך-תדירות של אורכי הסעיפים ומתאימים מודל מסוג Shenton–Skees–geometric, הפרמטרים כבר אינם מבחינים היטב בין הכיוונים, אם כי הם עדיין משקפים הבדלים סגנוניים בין המתרגמים.
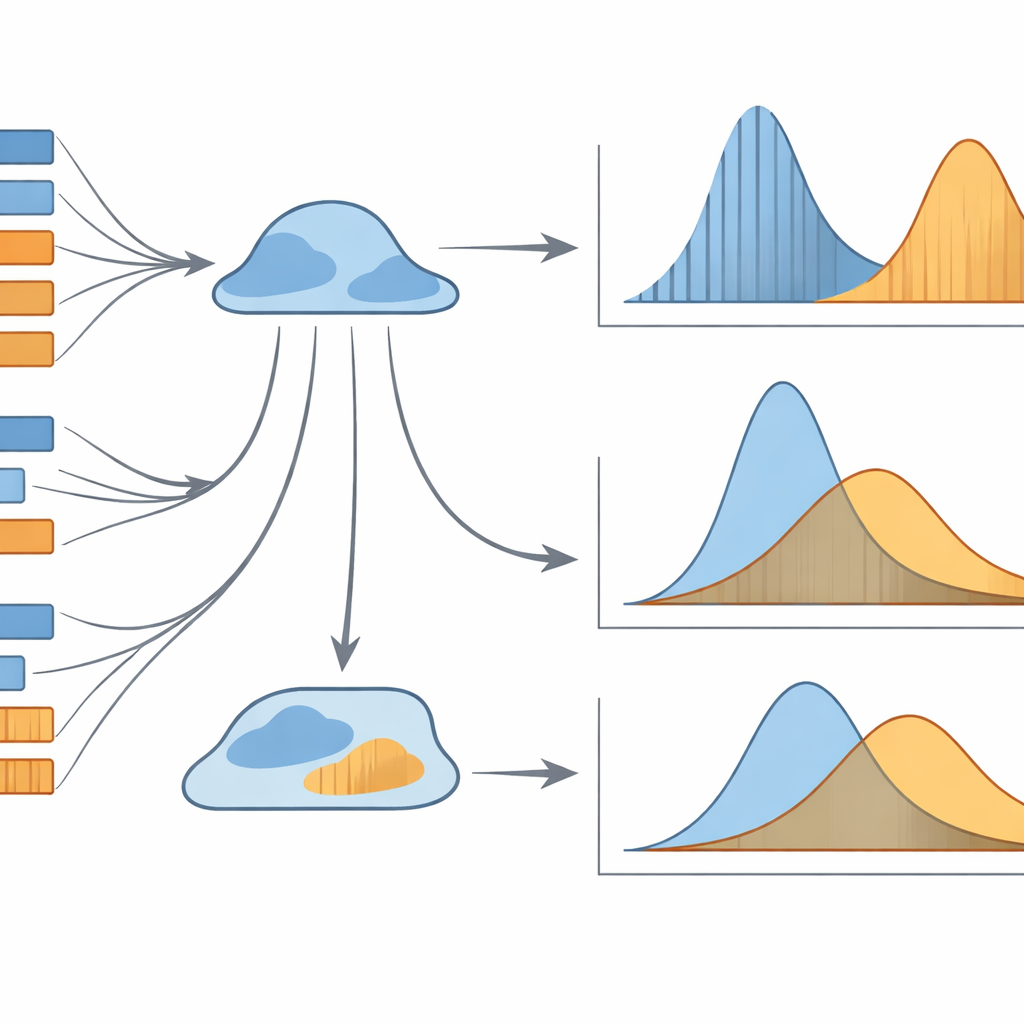
מדוע דפוסים חבויים אלה חשובים
בסך הכל, המחקר מראה שממוצעים פשוטים של אורך משפט או סעיף הם כלים כהים להבנת התרגום. צורת ההתפלגות ההסתברותית המלאה של דפוסי האורכים היא זו שנושאת את האות המידע המועיל ביותר. שתי קומבינציות מסוימות בולטות כחזקות במיוחד: התפלגות אורך-תדירות של אורכי המשפטים והתפלגות מיקום-תדירות של אורכי הסעיפים. ביחד, המודלים האלה יכולים להבחין באופן אמין האם תרגום נעשה לשפת האם או לשפה שנייה, גם כאשר הטקסטים נראים דומים באופן שטחי. עבור קהל שאינו מומחה, המסר הוא שתרגומים נושאים עקבות סטטיסטיים עדינים של אופן יצירתם — עקבות שמחשבים יכולים לקרוא, גם אם בני אדם לא מרגישים אותן ישירות. טכניקות אלה עשויות בסופו של דבר לסייע בהערכת איכות תרגום, בפרופילינג של סגנונות מתרגמים או בהבחנה בין תרגום אנושי למכונה, ובו בזמן להעמיק את הבנתנו כיצד שפה מתנהגת כשהיא עוברת בין לשונות.
ציטוט: Zhan, J., Fu, Y. & Jiang, Y. Can probabilistic distributions of sentence and clause lengths differentiate between translation directions?. Humanit Soc Sci Commun 13, 412 (2026). https://doi.org/10.1057/s41599-026-06737-8
מילות מפתח: כיוון התרגום, התפלגות אורכי משפטים, אורך סעיף, בלשנות כמותית, תרגומי לו שון