Clear Sky Science · nl
Kunnen probabilistische verdelingen van zin- en clauselengtes vertaalsrichtingen onderscheiden?
Waarom de lengte van zinnen in vertalingen ertoe doet
Wanneer we een vertaald verhaal lezen, stoppen we zelden bij de kleine bouwstenen van de tekst: hoe lang elke zin of clausule is, of hoe vaak bepaalde lengtes voorkomen. Toch kunnen deze patronen stilletjes onthullen wie de vertaling heeft gemaakt en in welke richting de vertaling plaatsvond — in de moedertaal van de vertaler of in een tweede taal. Dit artikel onderzoekt of de statistische vingerafdrukken van zin- en clauselengtes die vertaalsrichtingen betrouwbaarder kunnen onderscheiden dan eenvoudige gemiddelden, en biedt zo een nieuw perspectief op hoe vertaald taalgebruik verschilt van normaal geschreven taalgebruik.
Voorbij eenvoudige gemiddelden kijken
Decennialang gebruikten onderzoekers zinslengte als een grove indicator van schrijfstijl, auteursidentiteit en zelfs genre. Vroege studies richtten zich op basismaten zoals het gemiddelde aantal woorden per zin, maar die bleken vaak te grof om vragen als wie een betwist tekst schreef te kunnen beantwoorden. Recenter werk keek naar volledige verdelingen — hoe vaak korte, middelgrote en lange zinnen voorkomen — om subtielere patronen bloot te leggen. De huidige studie hanteert deze verdelingsbenadering binnen de vertaalwetenschap en onderzoekt of zij licht kan werpen op de lang betwiste kwestie van vertaalsrichting: vertalen in iemands moedertaal (L1) versus vertalen in een tweede taal (L2).
Een zorgvuldig afgestemde set verhalen
Om dit idee te testen bouwden de auteurs een strikt gecontroleerd corpus op basis van tien korte verhalen van de invloedrijke Chinese schrijver Lu Xun. Elk verhaal heeft meerdere Engelse vertalingen uitgevoerd door vier zeer bekwame vertalers. Twee zijn native speakers van het Engels die uit het Chinees vertalen (L1-vertaling naar hun moedertaal), en twee zijn native speakers van het Chinees die naar het Engels vertalen (L2-vertaling naar een tweede taal). Met behulp van op maat gemaakte computerscripts segmenteerden de onderzoekers de Engelse teksten in zinnen en kleinere eenheden die clausules worden genoemd, en telden vervolgens het aantal woorden per eenheid. Ze berekenden eenvoudige gemiddelden maar, belangrijker nog, modelleerden ze de volledige spreiding van lengtes met gevestigde probabilistische verdelingen uit de kwantitatieve taalkunde.
Wat zinspatronen onthullen
De eerste verrassing is dat de gemiddelde zinslengte bijna identiek is in L1- en L2-vertalingen, en statistische toetsen laten geen wezenlijk verschil zien. Op het eerste gezicht produceren beide groepen vertalers zinnen van vergelijkbare totale lengte. Echter, wanneer de auteurs kijken naar hoe zinslengtes verdeeld zijn, komen verborgen tegenstellingen bovendrijven. Wanneer zij zinnen groeperen in banden (bijvoorbeeld 1–5 woorden, 6–10 woorden, enz.) en een verfijnd model passen, bekend als het Extended Positive Negative Binomial-model, verschillen twee van de modelparameters consequent tussen L1- en L2-vertalingen. In gewone termen: beide richtingen geven de voorkeur aan zinnen van middellange lengte, maar de precieze vorm van die "heuvel" en de manier waarop frequenties afnemen naar zeer korte of zeer lange zinnen bevatten sterke aanwijzingen over wie in welke richting vertaalde.
Wat clausulepatronen toevoegen
Clausules, de kleinere eenheden binnen zinnen, vertellen een genuanceerder verhaal. Hier verschilt de gemiddelde lengte wel: vertalingen naar een tweede taal hebben de neiging iets langere clausules en meer variatie te hebben. Toch worden deze gemiddelden sterk beïnvloed door de persoonlijke stijl van elke vertaler, wat hun bruikbaarheid voor het classificeren van richting beperkt. Wanneer de auteurs het rang‑frequentiepatroon van clauselengtes onderzoeken (hoe vaak de meest voorkomende lengte voorkomt, daarna de op één na meest voorkomende, enz.) en een verdeling passen die het Hyperpoisson-model wordt genoemd, blijken de modelparameters zeer gevoelig voor vertaalsrichting en vangen ze ook individuele stilistische kenmerken. Daarentegen, wanneer ze clauselengte vanuit een ander perspectief bekijken — het lengte‑frequentiepatroon dat wordt passend gemaakt met een Shenton–Skees–geometrisch model — onderscheiden de parameters richtingen niet langer goed, hoewel ze nog steeds stilistische verschillen tussen vertalers weergeven.
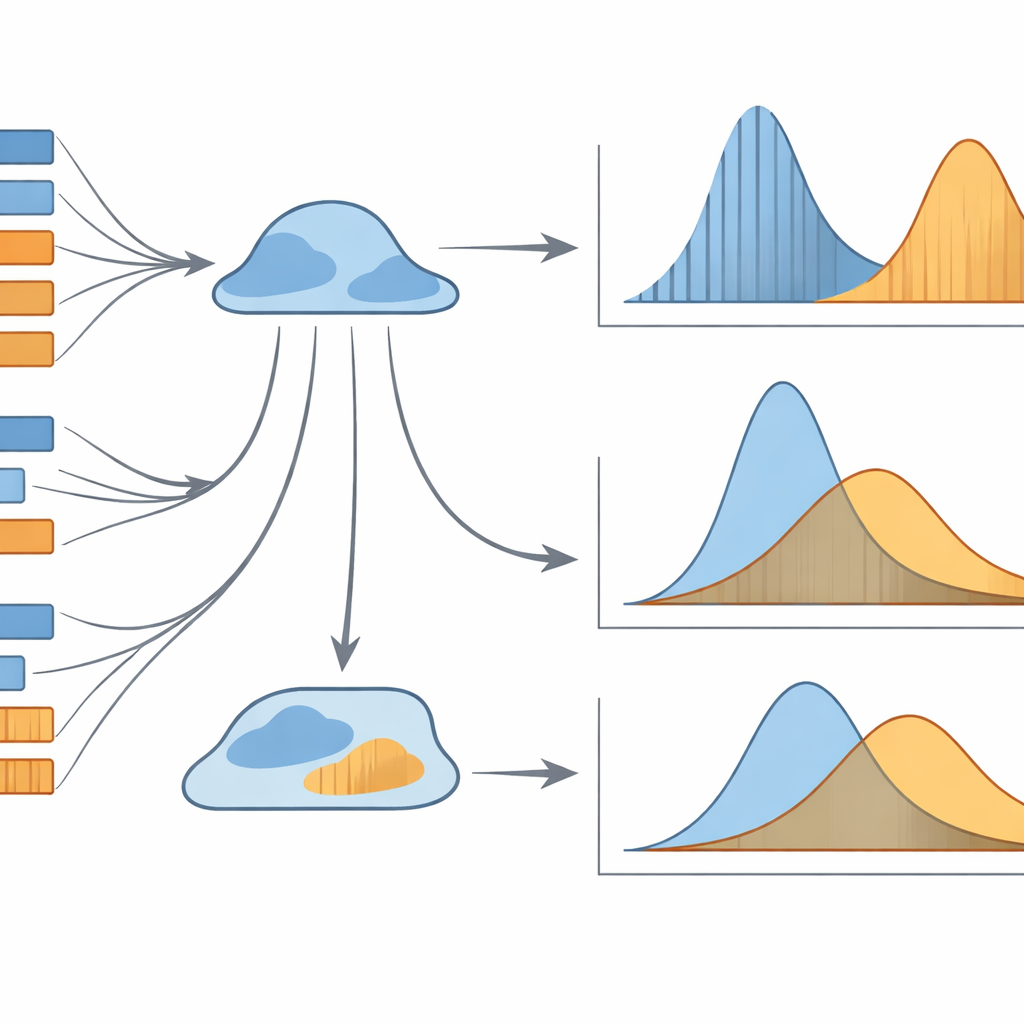
Waarom deze verborgen patronen ertoe doen
Alles bij elkaar toont de studie aan dat eenvoudige gemiddelden van zin‑ of clauselengte botte instrumenten zijn om vertalen te begrijpen. Het is de volledige probabilistische vorm van de lengtepatronen die het meest informatieve signaal draagt. Twee specifieke combinaties springen eruit als bijzonder krachtig: de lengte‑frequentieverdeling van zinslengtes en de rang‑frequentieverdeling van clauselengtes. Samen kunnen deze modellen betrouwbaar aangeven of een vertaling in iemands moedertaal of in een tweede taal is gedaan, zelfs wanneer de teksten oppervlakkig vergelijkbaar lijken. Voor niet‑specialisten is de boodschap dat vertalingen delicate statistische sporen dragen van hoe ze tot stand kwamen — sporen die computers kunnen lezen, ook al voelen mensen ze misschien niet direct. Deze technieken kunnen uiteindelijk helpen bij het beoordelen van vertaalkwaliteit, het profileren van vertalersstijlen of het onderscheiden van menselijke en machinevertalingen, en tegelijkertijd ons begrip verdiepen van hoe taal zich gedraagt wanneer ze tussen talen beweegt.
Bronvermelding: Zhan, J., Fu, Y. & Jiang, Y. Can probabilistic distributions of sentence and clause lengths differentiate between translation directions?. Humanit Soc Sci Commun 13, 412 (2026). https://doi.org/10.1057/s41599-026-06737-8
Trefwoorden: vertaalsrichting, verdeling van zinslengte, clauselengte, kwantitatieve taalkunde, vertalingen van Lu Xun