Clear Sky Science · pt
Distribuições probabilísticas de comprimentos de sentenças e orações podem diferenciar a direção da tradução?
Por que o comprimento das sentenças na tradução importa
Quando lemos uma história traduzida, raramente paramos para pensar nos pequenos blocos que compõem o texto: quão longa é cada sentença ou oração, ou com que frequência certos comprimentos aparecem. Ainda assim, esses padrões podem revelar discretamente quem está traduzindo e em que direção a tradução se dá — para a língua materna do tradutor ou para uma segunda língua. Este artigo investiga se as impressões digitais estatísticas dos comprimentos de sentenças e orações conseguem distinguir essas direções de tradução de forma mais confiável do que médias simples, oferecendo uma nova lente sobre como a linguagem traduzida difere da escrita comum.
Indo além das médias simples
Por décadas, pesquisadores usaram o comprimento da sentença como um indicador aproximado de estilo de escrita, identidade do autor e até de gênero. Estudos iniciais focavam em medidas básicas, como o número médio de palavras por sentença, mas essas medidas muitas vezes se mostraram demasiado grosseiras para resolver questões como a autoria de um texto disputado. Trabalhos mais recentes voltaram-se para distribuições completas — com que frequência aparecem sentenças curtas, médias e longas — para revelar padrões mais sutis. O presente estudo adota essa abordagem distributiva no campo dos estudos da tradução, perguntando se ela pode lançar luz sobre a questão muito debatida da direção da tradução: traduzir para a própria língua nativa (L1) versus traduzir para uma segunda língua (L2).
Um conjunto de contos cuidadosamente pareado
Para testar essa ideia, os autores construíram um corpus rigorosamente controlado a partir de dez contos do influente escritor chinês Lu Xun. Cada conto tem múltiplas traduções para o inglês realizadas por quatro tradutores altamente competentes. Dois são falantes nativos de inglês traduzindo do chinês (tradução L1 para a língua materna) e dois são falantes nativos de chinês traduzindo para o inglês (tradução L2 para uma segunda língua). Usando scripts de computador personalizados, os pesquisadores segmentaram os textos em inglês em sentenças e em unidades menores chamadas orações, e então contaram quantas palavras cada uma continha. Calcularam médias simples, mas, mais importante, modelaram a distribuição completa dos comprimentos usando distribuições probabilísticas estabelecidas na linguística quantitativa.
O que os padrões de sentença revelam
A primeira surpresa é que o comprimento médio das sentenças é quase idêntico nas traduções L1 e L2, e testes estatísticos não mostram diferença significativa. Na superfície, ambos os grupos de tradutores produzem sentenças de comprimento geral semelhante. Contudo, quando os autores examinam como os comprimentos das sentenças estão distribuídos, contrastes ocultos emergem. Ao agrupar sentenças em faixas (por exemplo, 1–5 palavras, 6–10 palavras etc.) e ajustar um modelo sofisticado conhecido como modelo Binomial Negativo Positivo Estendido, dois dos parâmetros do modelo diferem de forma consistente entre traduções L1 e L2. Em termos simples, ambas as direções privilegiam sentenças de comprimento médio, mas a forma exata da “colina” e a maneira como as frequências diminuem para sentenças muito curtas ou muito longas codificam pistas fortes sobre quem traduziu em qual direção.
O que os padrões de oração acrescentam
As orações, unidades menores dentro das sentenças, contam uma história mais matizada. Aqui, o comprimento médio difere: traduções para uma segunda língua tendem a ter orações ligeiramente mais longas e com maior variação. Ainda assim, essas médias são fortemente influenciadas pelo estilo pessoal de cada tradutor, o que limita sua utilidade para classificar a direção. Quando os autores examinam o padrão de frequência por posto dos comprimentos das orações (com que frequência ocorre o comprimento mais comum, depois o segundo mais comum etc.) e ajustam uma distribuição chamada modelo Hiperpoisson, os parâmetros do modelo mostram-se altamente sensíveis à direção da tradução e também capturam impressões digitais estilísticas individuais. Em contraste, ao olhar para o comprimento das orações por outro ângulo — o padrão comprimento–frequência ajustado com um modelo Shenton–Skees–geométrico — os parâmetros deixam de distinguir bem as direções, embora ainda reflitam diferenças estilísticas entre tradutores.
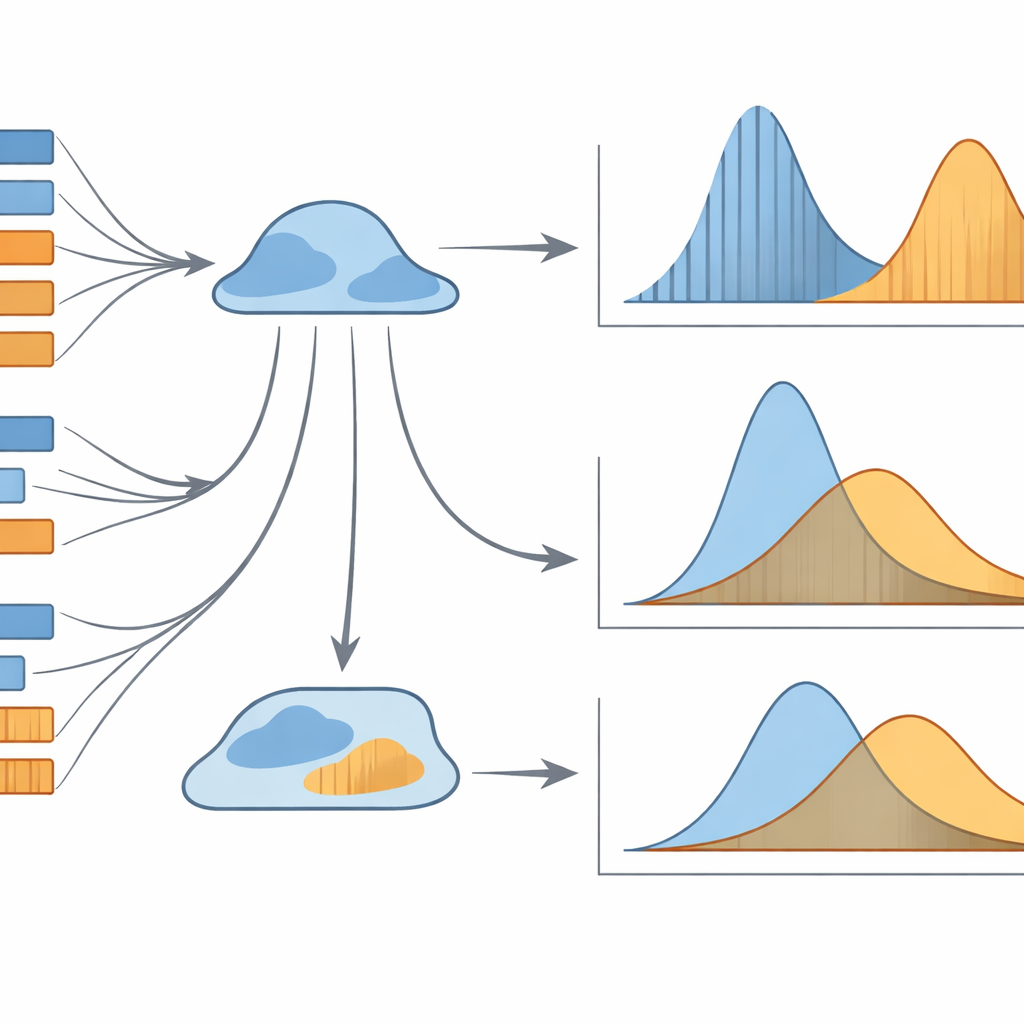
Por que esses padrões ocultos importam
No geral, o estudo mostra que médias simples do comprimento de sentenças ou orações são ferramentas pouco precisas para entender a tradução. É a forma probabilística completa dos padrões de comprimento que carrega o sinal mais informativo. Duas combinações se destacam como especialmente poderosas: a distribuição comprimento–frequência dos comprimentos de sentenças e a distribuição posto–frequência dos comprimentos de orações. Em conjunto, esses modelos podem indicar de forma confiável se uma tradução foi feita para a língua nativa ou para uma segunda língua, mesmo quando os textos parecem superficialmente semelhantes. Para não especialistas, a mensagem é que traduções carregam traços estatísticos delicados de como foram produzidas — traços que os computadores podem ler, mesmo que os humanos não os percebam diretamente. Essas técnicas podem, no futuro, ajudar a avaliar a qualidade de traduções, traçar perfis de estilos de tradutores ou distinguir tradução humana de automática, além de aprofundar nossa compreensão de como a linguagem se comporta ao transitar entre línguas.
Citação: Zhan, J., Fu, Y. & Jiang, Y. Can probabilistic distributions of sentence and clause lengths differentiate between translation directions?. Humanit Soc Sci Commun 13, 412 (2026). https://doi.org/10.1057/s41599-026-06737-8
Palavras-chave: direção da tradução, distribuição do comprimento das sentenças, comprimento da oração, linguística quantitativa, traduções de Lu Xun