Clear Sky Science · ru
Могут ли вероятностные распределения длин предложений и клауз отличать направления перевода?
Почему длина предложений в переводе важна
Когда мы читаем переводной рассказ, мы редко задумываемся о его мельчайших строительных блоках: насколько длинно каждое предложение или клауза, как часто встречаются те или иные длины. Тем не менее эти паттерны могут тихо выдать, кто выполнял перевод и в каком направлении он шёл — на родной язык переводчика или на его второй язык. В этой статье исследуется, способны ли статистические отпечатки распределений длин предложений и клауз различать направления перевода более надёжно, чем простые средние, и дают ли они новый ракурс на то, чем переводной язык отличается от обычной письменной речи.
Смотреть дальше простых средних
Десятилетиями исследователи использовали длину предложения как грубый индикатор стиля письма, личности автора и даже жанра. Ранние работы фокусировались на простых мерах, таких как среднее число слов в предложении, но они часто оказывались слишком грубыми, чтобы решать вопросы вроде авторства спорного текста. Более поздние исследования перешли к полным распределениям — тому, с какой частотой появляются короткие, средние и длинные предложения — чтобы выявить более тонкие закономерности. В настоящем исследовании этот распределенческий подход применяется к переводу: выясняется, может ли он пролить свет на давний вопрос о направлении перевода — перевод в родной язык (L1) против перевода во второй язык (L2).
Тщательно подобранный корпус рассказов
Чтобы проверить идею, авторы собрали строго контролируемый корпус, основанный на десяти коротких рассказах влиятельного китайского писателя Лу Сюня. Каждый рассказ представлен несколькими английскими переводами, выполненными четырьмя высококвалифицированными переводчиками. Двое — носители английского языка, переводившие с китайского (перевод в L1, на родной язык), и двое — носители китайского, переводившие на английский (перевод в L2, на второй язык). С помощью специальных скриптов исследователи сегментировали английские тексты на предложения и более мелкие единицы — клаузы, а затем подсчитали число слов в каждой. Они рассчитали простые средние, но, что важнее, смоделировали полное распределение длин, используя проверенные в количественной лингвистике вероятностные модели.
Что показывают паттерны предложений
Первый сюрприз заключается в том, что средняя длина предложения почти не отличается между переводами в L1 и в L2, и статистические тесты не выявляют значимой разницы. На первый взгляд обе группы переводчиков дают предложения примерно одинаковой общей длины. Однако при исследовании распределения длин предложений всплывают скрытые контрасты. Когда предложения группируют по диапазонам (например, 1–5 слов, 6–10 слов и так далее) и подгоняют сложную модель — расширенную положительно-отрицательную биномиальную (Extended Positive Negative Binomial), два параметра модели систематически различаются для переводов в L1 и L2. Проще говоря, в обоих направлениях преобладают предложения средней длины, но точная форма «холма» и то, как частоты убывают у очень коротких или очень длинных предложений, содержат сильные подсказки о направлении перевода.
Что добавляют паттерны клауз
Клаузы, более мелкие единицы внутри предложений, рассказывают более тонкую историю. Здесь средняя длина действительно различается: переводы на второй язык склонны иметь слегка длиннее клаузы и большую вариативность. Однако эти средние сильно зависят от индивидуального стиля каждого переводчика, что ограничивает их полезность для классификации направления. Когда авторы рассматривают ранг–частотную закономерность длин клауз (как часто встречается наиболее распространённая длина, затем вторая по распространённости и так далее) и подгоняют модель Hyperpoisson, параметры модели оказываются очень чувствительными к направлению перевода и одновременно захватывают индивидуальные стилевые отпечатки переводчиков. В отличие от этого, при рассмотрении «длина–частота» клауз и подгонке модели Shenton–Skees–geometric параметры уже хуже различают направления, хотя по-прежнему отражают стилистические различия между переводчиками.
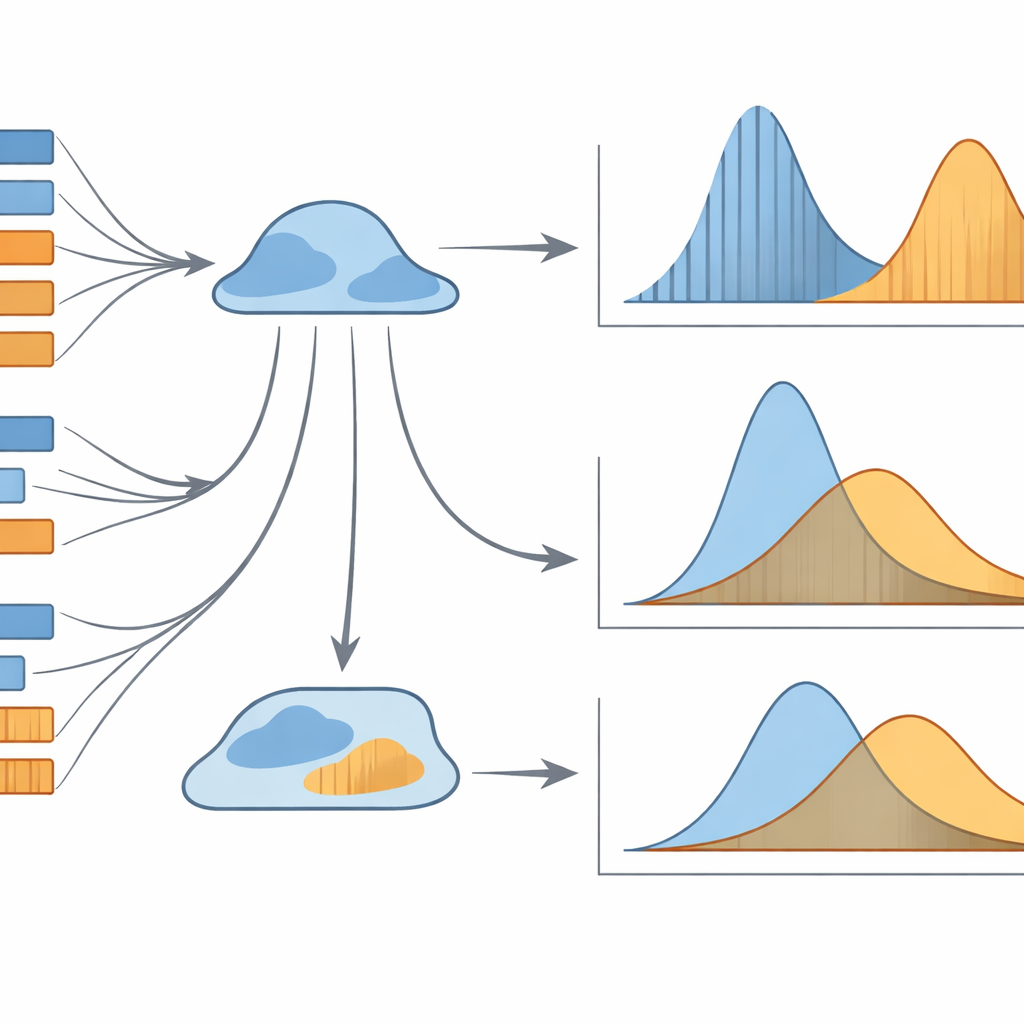
Почему эти скрытые паттерны важны
В целом исследование показывает, что простые средние длины предложений или клауз — грубый инструмент для понимания перевода. Именно полная вероятностная форма распределений длины несёт наиболее информативный сигнал. Особенно сильными оказываются две комбинации: распределение «длина–частота» для предложений и распределение «ранг–частота» для клауз. Вместе эти модели надёжно определяют, выполнен ли перевод на родной язык или на второй язык, даже когда тексты внешне кажутся похожими. Для неспециалистов вывод таков: переводы несут тонкие статистические следы способов их создания — следы, которые могут «прочитать» компьютеры, хотя человек их не всегда ощутит. Эти методы со временем могут помочь в оценке качества перевода, профилировании стилей переводчиков или в отличии человека от машинного перевода, а также углубить наше понимание того, как язык себя ведёт при переходе между языками.
Цитирование: Zhan, J., Fu, Y. & Jiang, Y. Can probabilistic distributions of sentence and clause lengths differentiate between translation directions?. Humanit Soc Sci Commun 13, 412 (2026). https://doi.org/10.1057/s41599-026-06737-8
Ключевые слова: направление перевода, распределение длины предложений, длина клаузы, количественная лингвистика, переводы Лу Сюня