Clear Sky Science · en
Can probabilistic distributions of sentence and clause lengths differentiate between translation directions?
Why the Length of Sentences in Translation Matters
When we read a translated story, we rarely stop to think about the tiny building blocks of the text: how long each sentence or clause is, or how often certain lengths appear. Yet these patterns can quietly reveal who is doing the translating and in which direction the translation is going—into the translator’s mother tongue or into a second language. This article explores whether the statistical fingerprints of sentence and clause lengths can tell these translation directions apart more reliably than simple averages, offering a new lens on how translated language differs from ordinary writing.
Looking Beyond Simple Averages
For decades, researchers have used sentence length as a rough indicator of writing style, author identity, and even genre. Early studies focused on basic measures such as the average number of words per sentence, but these often proved too crude to settle questions like who wrote a disputed text. More recent work has turned to full distributions—how often short, medium, and long sentences appear—to uncover subtler patterns. The present study takes this distributional approach into the field of translation studies, asking whether it can shed light on the long-debated issue of translation direction: translating into one’s native language (L1) versus translating into a second language (L2).
A Carefully Matched Set of Stories
To test this idea, the authors built a tightly controlled corpus based on ten short stories by the influential Chinese writer Lu Xun. Each story has multiple English translations carried out by four highly skilled translators. Two are native speakers of English translating from Chinese (L1 translation into their mother tongue), and two are native speakers of Chinese translating into English (L2 translation into a second language). Using custom computer scripts, the researchers segmented the English texts into sentences and shorter units called clauses, then counted how many words each contained. They calculated simple averages but, more importantly, modeled the full spread of lengths using established probabilistic distributions from quantitative linguistics.
What Sentence Patterns Reveal
The first surprise is that average sentence length is almost identical in L1 and L2 translations, and statistical tests show no meaningful difference. On the surface, both groups of translators produce sentences of similar overall length. However, once the authors examine how sentence lengths are distributed, hidden contrasts emerge. When they group sentences into bands (for example, 1–5 words, 6–10 words, and so on) and fit a sophisticated distribution known as the Extended Positive Negative Binomial model, two of the model’s parameters differ consistently between L1 and L2 translations. In plain terms, both directions favor medium-length sentences, but the exact shape of the “hill” and the way frequencies taper off toward very short or very long sentences encode strong cues about who translated in which direction.
What Clause Patterns Add
Clauses, the smaller units within sentences, tell a more nuanced story. Here, average length does differ: translations into a second language tend to have slightly longer clauses and more variation. Yet these averages are strongly influenced by each translator’s personal style, limiting their usefulness for classifying direction. When the authors examine the rank–frequency pattern of clause lengths (how often the most common length occurs, then the second most common, and so on) and fit a distribution called the Hyperpoisson model, the model’s parameters prove highly sensitive to translation direction and also capture individual stylistic fingerprints. In contrast, when they look at clause length from another angle—the length–frequency pattern fitted with a Shenton–Skees–geometric model—the parameters no longer distinguish directions well, though they still reflect stylistic differences among translators.
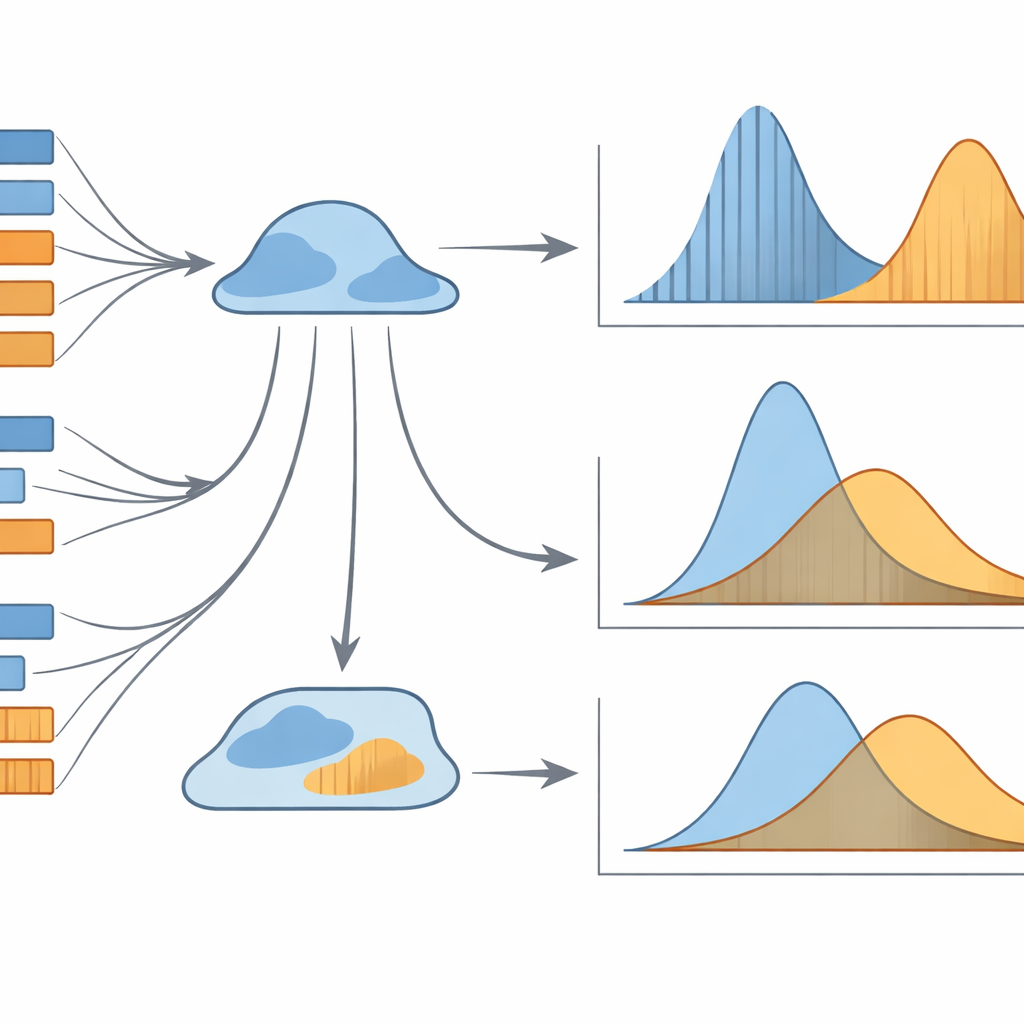
Why These Hidden Patterns Matter
Overall, the study shows that simple averages of sentence or clause length are blunt tools for understanding translation. It is the full probabilistic shape of the length patterns that carries the most informative signal. Two particular combinations stand out as especially powerful: the length–frequency distribution of sentence lengths and the rank–frequency distribution of clause lengths. Together, these models can reliably tell whether a translation was done into a native language or into a second language, even when the texts look superficially similar. For non-specialists, the message is that translations carry delicate statistical traces of how they were produced—traces that computers can read, even if humans cannot feel them directly. These techniques may eventually help in assessing translation quality, profiling translator styles, or distinguishing human from machine translation, while also deepening our understanding of how language behaves when it moves between tongues.
Citation: Zhan, J., Fu, Y. & Jiang, Y. Can probabilistic distributions of sentence and clause lengths differentiate between translation directions?. Humanit Soc Sci Commun 13, 412 (2026). https://doi.org/10.1057/s41599-026-06737-8
Keywords: translation direction, sentence length distribution, clause length, quantitative linguistics, Lu Xun translations