Clear Sky Science · sv
Kan sannolikhetsfördelningar för meningars och satsers längd särskilja översättningsriktningar?
Varför meningslängd i översättning spelar roll
När vi läser en översatt berättelse tänker vi sällan på textens små byggstenar: hur långa varje mening eller sats är, eller hur ofta vissa längder förekommer. Ändå kan dessa mönster tyst avslöja vem som gjort översättningen och i vilken riktning den gått — till översättarens modersmål eller till ett andraspråk. Denna artikel undersöker om de statistiska fingeravtrycken i menings- och satslängder kan skilja dessa översättningsriktningar åt mer tillförlitligt än enkla medelvärden, och erbjuder en ny lins på hur översatt språk skiljer sig från vanlig text.
Bortom enkla medelvärden
I årtionden har forskare använt meningslängd som en grov indikator på skrivstil, författaridentitet och till och med genre. Tidigare studier fokuserade på grundläggande mått som genomsnittligt antal ord per mening, men dessa visade sig ofta för grova för att avgöra frågor som vem som skrivit en omstridd text. Nyare arbete har vänt sig till fulla fördelningar — hur ofta korta, medellånga och långa meningar förekommer — för att upptäcka mer subtila mönster. Denna studie för över detta fördelningsmässiga angreppssätt till översättningsstudier och frågar om det kan kasta ljus över den länge diskuterade frågan om översättningsriktning: att översätta till sitt modersmål (L1) kontra att översätta till ett andraspråk (L2).
En noggrant matchad samling berättelser
För att testa idén byggde författarna ett tätt kontrollerat korpus baserat på tio noveller av den inflytelserika kinesiska författaren Lu Xun. Varje berättelse har flera engelska översättningar gjorda av fyra högkvalificerade översättare. Två är infödda engelsktalande som översätter från kinesiska (L1-översättning in i modersmålet), och två är infödda kinesisktalande som översätter till engelska (L2-översättning till ett andraspråk). Med skräddarsydda datorprogram delade forskarna upp de engelska texterna i meningar och i mindre enheter kallade satser, och räknade hur många ord varje innehöll. De beräknade enkla medelvärden men, viktigare, modellerade hela spridningen av längder med etablerade sannolikhetsfördelningar från kvantitativ lingvistik.
Vad meningsmönster avslöjar
Den första överraskningen är att genomsnittlig meningslängd är nästan identisk i L1- och L2-översättningar, och statistiska tester visar ingen meningsfull skillnad. På ytan producerar båda grupperna meningar av liknande total längd. Men när författarna granskar hur meningslängderna fördelar sig framträder dolda kontraster. När de grupperar meningar i intervall (till exempel 1–5 ord, 6–10 ord och så vidare) och anpassar en sofistikerad fördelning känd som Extended Positive Negative Binomial-modellen, skiljer sig två av modellens parametrar konsekvent mellan L1- och L2-översättningar. Enkel sagt föredrar båda riktningarna medellånga meningar, men den exakta formen på "kullen" och hur frekvenserna avtar mot mycket korta eller mycket långa meningar kodar starka ledtrådar om vem som översatt åt vilket håll.
Vad satsmönster tillför
Satserna, de mindre enheterna inom meningar, berättar en mer nyanserad historia. Här skiljer sig medellängden: översättningar till ett andraspråk tenderar att ha något längre satser och större variation. Men dessa medelvärden påverkas starkt av varje översättares personliga stil, vilket begränsar deras användbarhet för att klassificera riktning. När författarna undersöker rang–frekvensmönstret för satslängder (hur ofta den vanligaste längden förekommer, sedan den näst vanligaste osv.) och anpassar en fördelning kallad Hyperpoisson-modellen, visar sig modellens parametrar vara mycket känsliga för översättningsriktning och fångar också individuella stilavtryck. I kontrast, när de betraktar satslängd från en annan vinkel — längd–frekvensmönstret anpassat med en Shenton–Skees–geometric-modell — skiljer parametrarna inte längre riktningarna väl, även om de fortfarande speglar stilistiska skillnader mellan översättare.
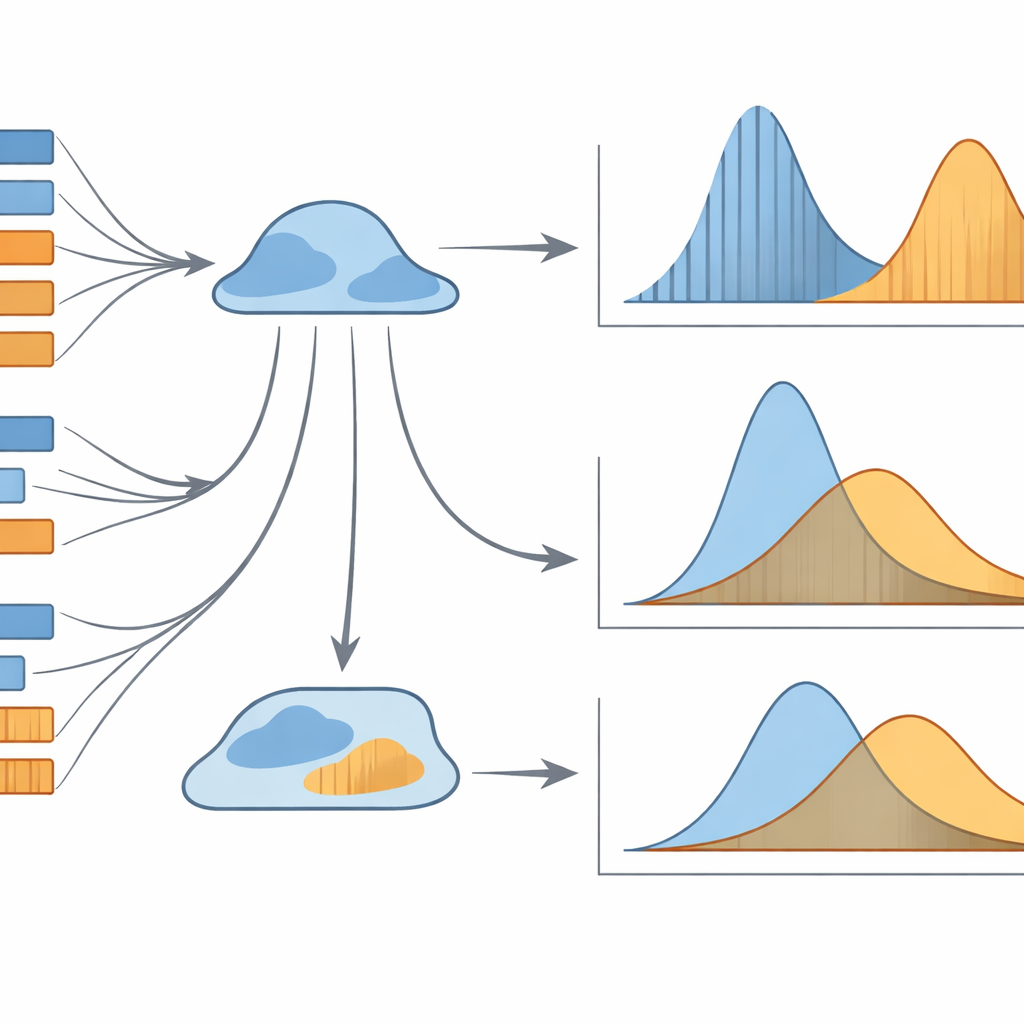
Varför dessa dolda mönster är viktiga
Sammantaget visar studien att enkla medelvärden av meningars eller satsers längd är trubbiga verktyg för att förstå översättning. Det är den fulla sannolikhetsformade formen av längdmönstren som bär den mest informativa signalen. Två särskilda kombinationer framträder som särskilt kraftfulla: längd–frekvensfördelningen för meningslängder och rang–frekvensfördelningen för satslängder. Tillsammans kan dessa modeller pålitligt ange om en översättning gjorts till ett modersmål eller till ett andraspråk, även när texterna vid en första anblick verkar mycket lika. För lekmän är budskapet att översättningar bär fina statistiska spår av hur de producerats — spår som datorer kan läsa, även om människor inte direkt uppfattar dem. Dessa tekniker kan så småningom hjälpa till att bedöma översättningskvalitet, profilera översättares stilar eller skilja mänsklig från maskinell översättning, samtidigt som de fördjupar vår förståelse för hur språk beter sig när det rör sig mellan tungomål.
Citering: Zhan, J., Fu, Y. & Jiang, Y. Can probabilistic distributions of sentence and clause lengths differentiate between translation directions?. Humanit Soc Sci Commun 13, 412 (2026). https://doi.org/10.1057/s41599-026-06737-8
Nyckelord: översättningsriktning, fördelning av meningslängd, satslängd, kvantitativ lingvistik, översättningar av Lu Xun