Clear Sky Science · sv
Ett SMILES-baserat flervegs hypergrafinferenznätverk för rekonstruktion av metaboliska modeller
Varför det spelar roll att fylla metaboliska blinda fläckar
Varje levande cell sjuder av tusentals små kemiska reaktioner som håller den vid liv, låter den växa och anpassa sig. Forskare bygger storskaliga ”kartor” över dessa reaktioner för att konstruera bättre mikrober för bränsleproduktion, studera hur tarmbakterier påverkar hälsa och till och med söka efter nya läkemedelsmål. Men många av dessa kartor innehåller luckor: reaktioner som mycket sannolikt sker i celler men saknas i våra modeller. Denna artikel presenterar MuSHIN, ett nytt artificiellt intelligenssystem som hjälper till att fylla dessa blinda fläckar, vilket gör våra kartor över metabolism skarpare, mer tillförlitliga och betydligt mer användbara.
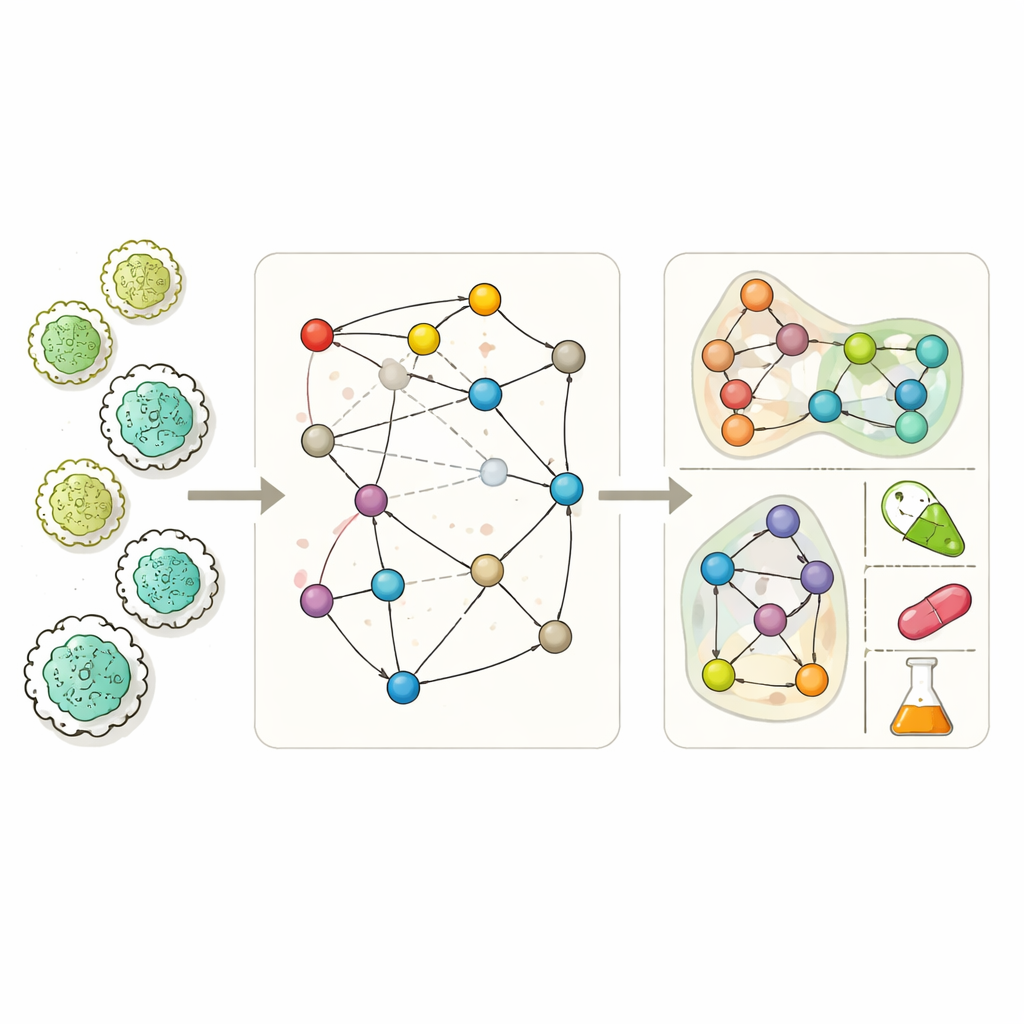
Bygga bättre kartor över cellkemi
Moderna genomskaliga metaboliska modeller syftar till att lista i stort sett varje kemisk reaktion en organism kan utföra. Med dem kan forskare simulera hur en mikroorganism växer i olika miljöer, vilka biprodukter den utsöndrar och vilka gener som är nödvändiga för överlevnad. Ändå är dessa modeller ofta ofullständiga. Luckor i biokemisk kunskap, fel i genannotering och begränsade experiment lämnar hål i nätverken, så simulerade celler ibland inte kan växa, inte kan producera kända fermenteringsprodukter eller felaktigt förutsäger vilka gener som är avgörande. Befintliga ”gap-filling”-verktyg försöker täppa igen dessa hål, men många förlitar sig i hög grad på villkorsspecifika experimentdata eller förenklar nätverket så mycket att de missar de komplexa, mångmolekylära interaktioner som verkliga reaktioner innebär.
Från enkla länkar till rikare hyperkopplingar
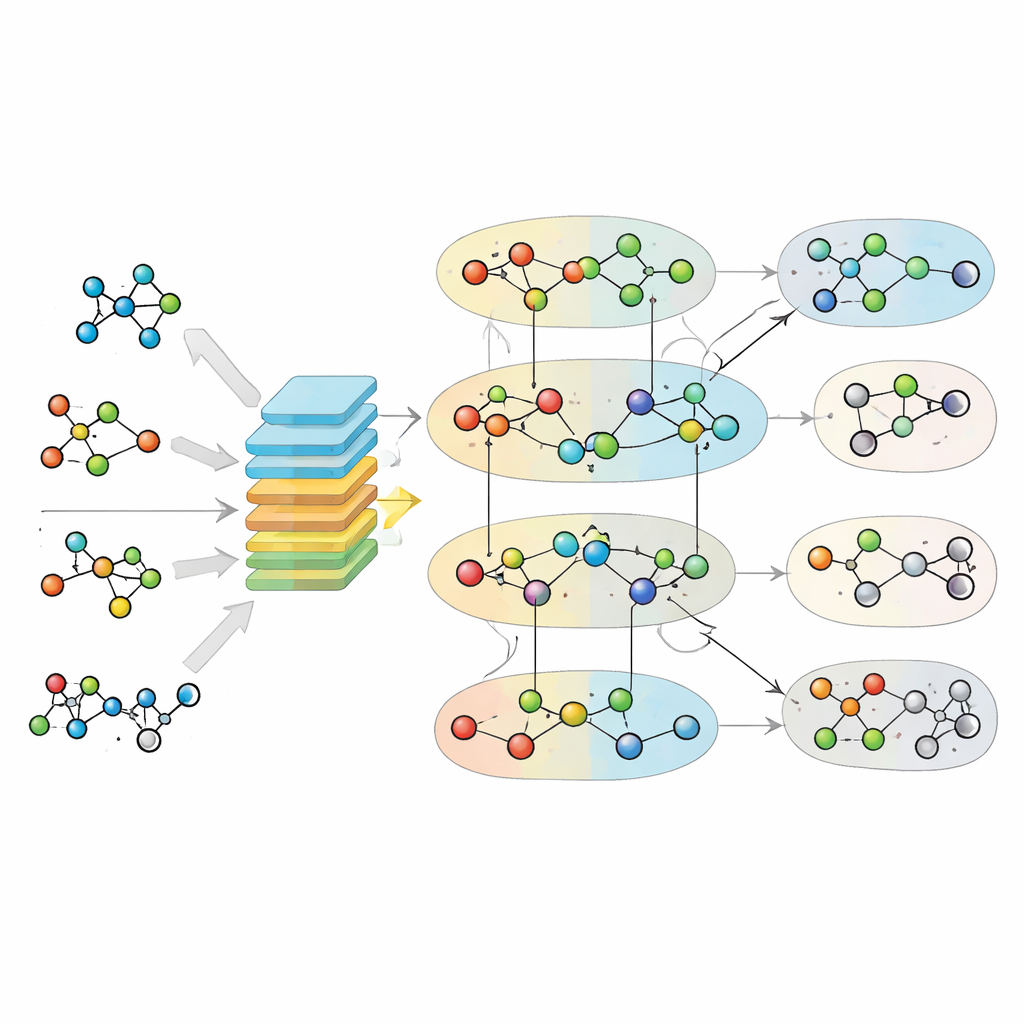
MuSHIN angriper problemet genom att representera metabolism på ett mer troget sätt. Istället för att behandla varje reaktion som en enkel parvis länk mellan två metaboliter använder det en hypergraf, där en enda koppling kan binda samman ett godtyckligt antal molekyler samtidigt. Detta speglar verklig biokemi, där en reaktion ofta omvandlar flera substrat till flera produkter samtidigt. MuSHIN berikar sedan denna struktur med kemisk ”mening.” Den omvandlar varje metabolit och reaktion, beskrivna som SMILES-strängar (en textkodning av molekylstruktur), till högdimensionella numeriska fingeravtryck med hjälp av två transformerbaserade kemimodeller kallade ChemBERTa och RXNFP. Dessa fingeravtryck låter systemet resonera inte bara om vem som är kopplad till vem i nätverket, utan också om hur molekylerna och reaktionerna ser ut kemiskt.
Hur inlärningsmotorn fungerar
När hypergrafen och de kemiska fingeravtrycken är på plats lär sig MuSHIN att skilja verkliga reaktioner från falska. Författarna bygger träningsset genom att ta kända reaktioner från högkvalitativa metaboliska modeller och sedan skapa ”negativa” exempel genom att subtilt förvränga deltagarna i varje reaktion, bevara den övergripande balansen men göra kemin osannolik. MuSHIN använder en dubbelt uppmärksamhetsmekanism för att skicka information fram och tillbaka mellan metabolitnoder och reaktionshyperkanter, och förfinar upprepade gånger sina interna representationer av båda. Denna uppmärksamhetsprocess hjälper modellen att fokusera på de mest informativa delarna av nätverket och de mest avslöjande kemiska dragen. I slutsteget poängsätter MuSHIN varje reaktion och anger hur sannolik den är att vara giltig och därmed en bra kandidat för att fylla en lucka.
Sätta MuSHIN på prov
Forskarna testade MuSHIN noggrant på 926 metaboliska modeller från två stora databaser, genom att systematiskt ta bort kända reaktioner och be modellen återskapa dem. Över ett spektrum av kvalitetsmått överträffade MuSHIN konsekvent flera ledande hypergraf- och djupinlärningsmetoder, i vissa fall med en förbättring på omkring 17 procentenheter. Anmärkningsvärt är att den förblev noggrann även när så mycket som 80 % av reaktionerna var borttagna, vilket visar på robusthet i extremt ofullständiga nätverk. I en annan uppsättning experiment tillämpade teamet MuSHIN på 24 utkastmodeller av anaeroba bakterier involverade i fermentering. Genom att lägga till endast de 100 högst rankade reaktionerna som MuSHIN föreslog för varje organism förbättrade de dramatiskt modellernas förmåga att förutsäga vilka fermenteringsprodukter — såsom etanol, mjölksyra eller myrsyra — som faktiskt observeras i experiment, medan konkurrerande metoder behövde många fler tillagda reaktioner för att nå blygsamma förbättringar.
Upptäcka dolda vägar i metabolismen
En närmare granskning av de reaktioner MuSHIN föreslår visar varför dess förutsägelser är så värdefulla. Nästan hälften av dess föreslagna tillägg visar sig vara transport- och utbytesreaktioner — steg som flyttar molekyler över cellmembran eller in och ut ur det modellerade systemet. Dessa reaktioner är ökända för att vara underrepresenterade men styr ofta om en väg alls kan bära någon flöde. Genom att korrekt återställa sådana gränssteg öppnar MuSHIN blockerade metaboliska rutter och återhämtar saknade fermenteringsprodukter över flera arter. Modellen åtgärdar också mer intrikata luckor, såsom att återställa succinatproduktion i en tarmbakterie genom att lägga till koordinerade transportörer som fullbordar en gren av den centrala energigenererande cykeln.
Vad detta betyder för biologi och medicin
För icke-specialister är huvudbudskapet att MuSHIN får våra virtuella celler att bete sig mer som verkliga. Genom att förena en rikare nätverksrepresentation med kemiinsiktsfull AI kan den upptäcka saknade reaktioner som andra metoder förbiser, särskilt i dåligt studerade mikrober. Denna förbättrade noggrannhet skulle kunna snabba upp utformningen av industriella stammar för produktion av bränslen och kemikalier, skärpa modeller av den mänskliga tarmmikrobiomen och stödja mer precisa simuleringar av sjukdomsmetabolism och behandlingssvar. När framtida utvidgningar inkluderar gener, reglering och till och med nya reaktioner som aldrig setts tidigare, kan verktyg som MuSHIN bli centrala för att omvandla genomdata till pålitliga, prediktiva ritningar av levande system.
Citering: Zhao, Y., Chen, Y., Yu, Y. et al. A multi-way SMILES-based hypergraph inference network for metabolic model reconstruction. Commun Biol 9, 531 (2026). https://doi.org/10.1038/s42003-026-09761-1
Nyckelord: genomskaliga metaboliska modeller, rekonstruktion av metaboliska nätverk, hypergraf-neurala nätverk, djupinlärning i systembiologi, mikrobiell fermentering