Clear Sky Science · ru
Многопутевая гиперграфная инференционная сеть на основе SMILES для восстановления метаболических моделей
Почему важно заполнять метаболические «слепые зоны»
Каждая живая клетка содержит тысячи мелких химических реакций, которые поддерживают её жизнь, рост и адаптацию. Учёные создают крупномасштабные «карты» этих реакций, чтобы проектировать более эффективные микроорганизмы для производства топлива, изучать влияние кишечной микробиоты на здоровье и даже искать новые мишени для лекарств. Однако многие такие карты полны пробелов: реакции, которые почти наверняка происходят в клетках, отсутствуют в наших моделях. В этой статье представлен MuSHIN — новая система искусственного интеллекта, которая помогает закрывать эти пробелы, делая наши карты метаболизма более чёткими, надёжными и полезными.
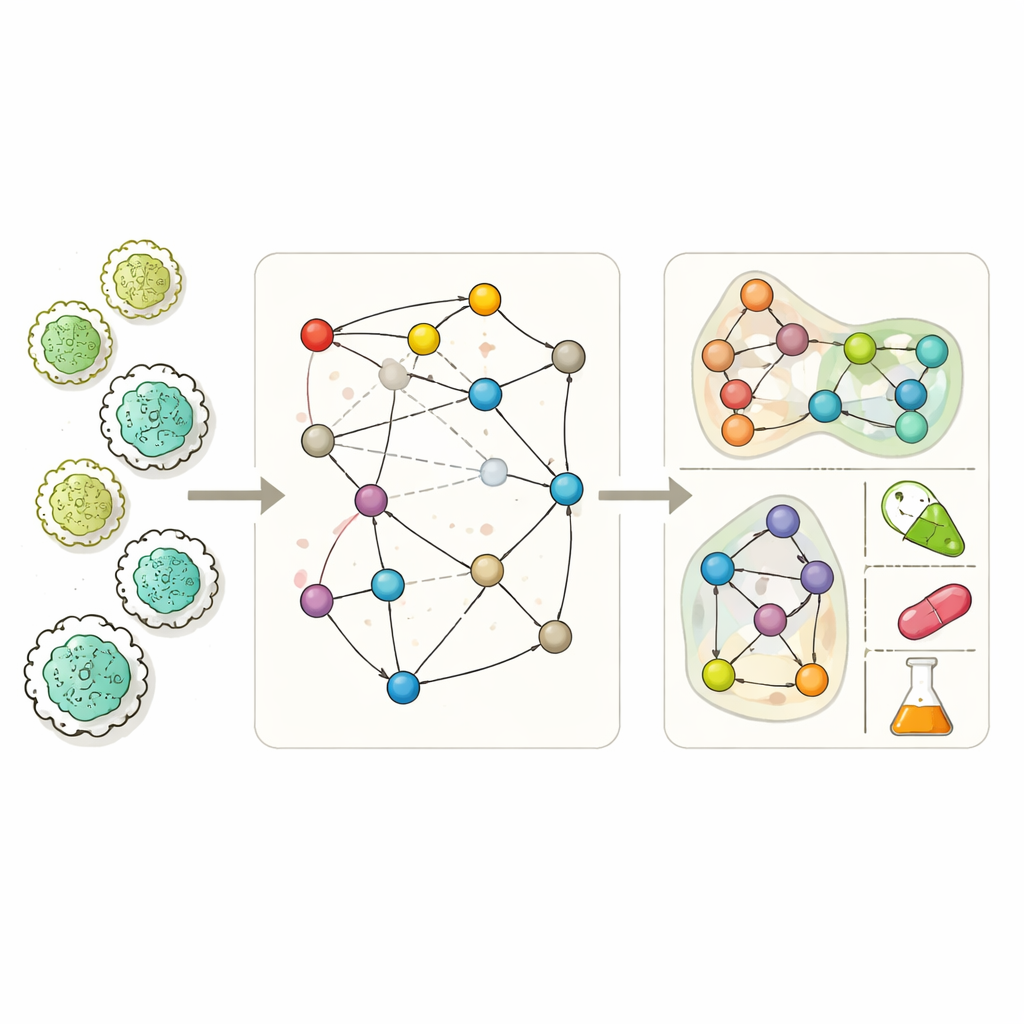
Построение лучших карт клеточной химии
Современные метаболические модели масштаба генома стремятся перечислить почти все химические реакции, которые способен осуществлять организм. С их помощью исследователи могут моделировать рост микроба в разных условиях, какие побочные продукты он выделяет и какие гены необходимы для выживания. Тем не менее эти модели часто неполны. Пробелы в биохимических знаниях, ошибки аннотации генома и ограниченность экспериментальных данных оставляют дыры в сетях, из-за чего смоделированные клетки иногда не растут, не способны производить известные ферментационные продукты или неверно предсказывают ключевые гены. Существующие инструменты «заполнения пробелов» пытаются закрыть эти дыры, но многие из них сильно зависят от условий эксперимента или упрощают сеть до такой степени, что упускают сложные много-молекулярные взаимодействия, характерные для реальных реакций.
От простых связей к богатым гиперсвязям
MuSHIN решает эту проблему, представляя метаболизм более правдоподобно. Вместо того чтобы трактовать каждую реакцию как простую попарную связь между двумя метаболитами, система использует гиперграф, где одно соединение может одновременно связывать любое число молекул. Это отражает реальную биохимию, в которой одна реакция часто превращает несколько субстратов в несколько продуктов одновременно. MuSHIN затем наполняет эту структуру «химическим смыслом». Он переводит каждый метаболит и реакцию, описанные SMILES-строками (текстовое кодирование структуры молекулы), в векторные представления высокой размерности с помощью двух трансформерных химических моделей — ChemBERTa и RXNFP. Эти отпечатки позволяют системе рассуждать не только о том, кто с кем связан в сети, но и о том, как молекулы и реакции выглядят с химической точки зрения.
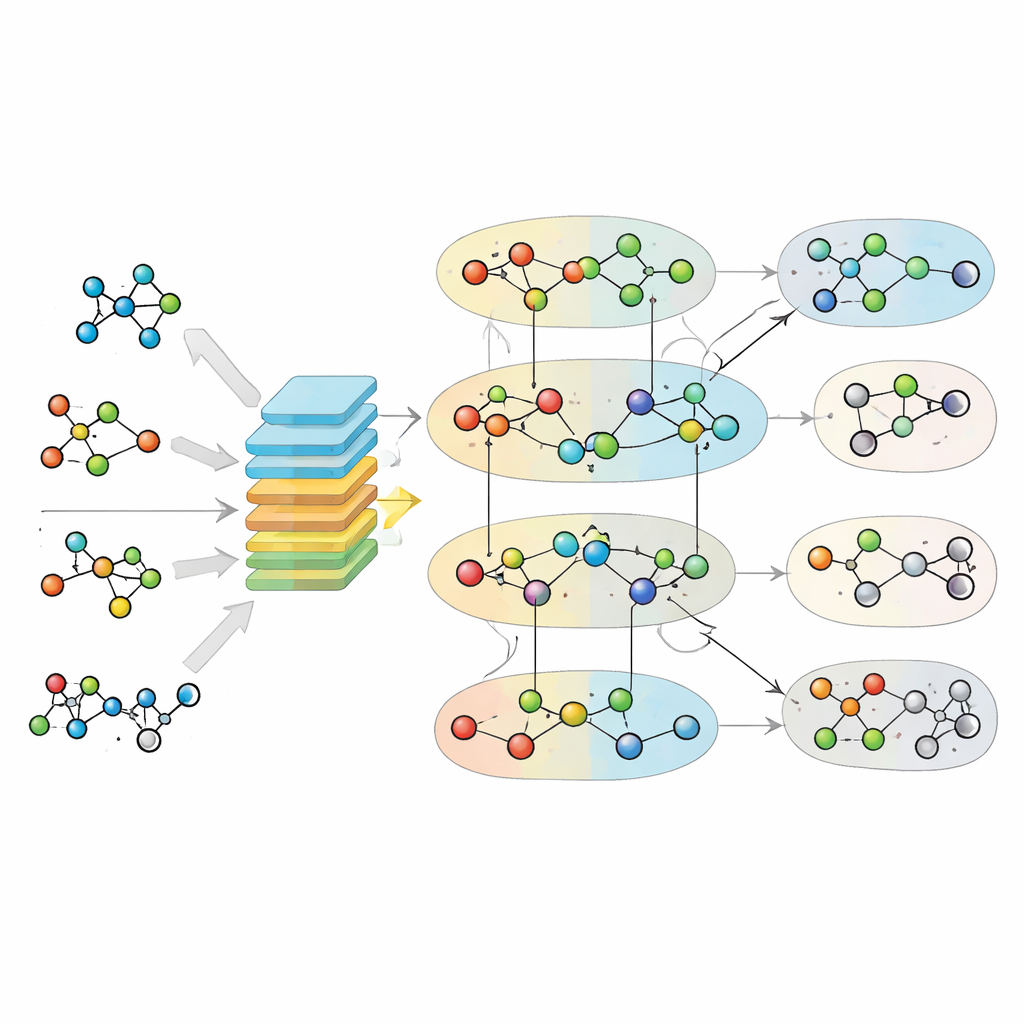
Как работает обучающий модуль
После построения гиперграфа и получения химических отпечатков MuSHIN учится различать реальные реакции и поддельные. Авторы формируют обучающие наборы, беря известные реакции из высококачественных метаболических моделей и создавая «негативные» примеры путём тонкого перемешивания участников реакции, сохраняя общий стехиометрический баланс, но делая химию неправдоподобной. MuSHIN использует двойной механизм внимания для обмена информацией между узлами-метаболитами и гиперребрами-реакциями, многократно уточняя внутренние представления обоих типов объектов. Этот процесс внимания помогает модели сосредоточиться на наиболее информативных частях сети и на наиболее показательных химических признаках. На финальном этапе MuSHIN присваивает каждой реакции оценку — насколько вероятно, что она валидна и подходит для заполнения пробела.
Тестирование MuSHIN
Исследователи всесторонне протестировали MuSHIN на 926 метаболических моделях из двух крупных баз данных, систематически удаляя известные реакции и проверяя, сможет ли модель восстановить их. По ряду показателей качества MuSHIN последовательно превосходил несколько ведущих гиперграфных и глубоких методов, в некоторых случаях повышая показатели примерно на 17 процентных пунктов. Примечательно, что модель оставалась точной даже когда было удалено до 80% реакций, демонстрируя устойчивость в чрезвычайно неполных сетях. В другом эксперименте команда применяла MuSHIN к 24 черновым моделям анаэробных бактерий, участвующих в ферментации. Добавив только по 100 лучших реакций, оценённых MuSHIN для каждого организма, они значительно улучшили способность моделей предсказывать ферментационные продукты — такие как этанол, молочная кислота или муравьиная кислота — тогда как конкурирующие методы требовали значительно большего числа добавленных реакций для достижения скромных улучшений.
Выявление скрытых ворот в метаболизме
Более детальный анализ предлагаемых MuSHIN реакций показывает, почему его предсказания ценны. Почти половина предлагаемых дополнений оказываются транспортными и обменными реакциями — шагами, которые переносят молекулы через клеточные мембраны или вовне/внутрь моделируемой системы. Эти реакции традиционно недостаточно представлены, хотя зачастую именно они решают, может ли путь проводить поток веществ. Правильно восстанавливая такие граничные шаги, MuSHIN вновь открывает заблокированные метаболические маршруты и возвращает недостающие продукты ферментации в разных видах. Модель также восстанавливает более сложные пробелы, например восстановление производства сукцината в кишечном бактериальном виде путём добавления скоординированных транспортеров, завершающих ветвь центрального энергетического цикла.
Что это значит для биологии и медицины
Для неспециалистов главное сообщение таково: MuSHIN делает наши виртуальные клетки более похожими на реальные. Сочетая более богатое представление сети с химически подкованным ИИ, он может находить пропущенные реакции, которые другие методы упускают, особенно в плохо изученных микроорганизмах. Повышенная точность может ускорить разработку промышленных штаммов для производства топлива и химикатов, улучшить модели микробиоты человека и поддержать более точное моделирование метаболизма при заболеваниях и ответах на лечение. По мере того как будущие расширения будут включать гены, регуляцию и даже ранее не описанные реакции, инструменты вроде MuSHIN могут стать ключевыми в превращении геномных данных в надёжные предсказательные схемы живых систем.
Цитирование: Zhao, Y., Chen, Y., Yu, Y. et al. A multi-way SMILES-based hypergraph inference network for metabolic model reconstruction. Commun Biol 9, 531 (2026). https://doi.org/10.1038/s42003-026-09761-1
Ключевые слова: метаболические модели масштаба генома, восстановление метаболических сетей, гиперграфные нейронные сети, глубокое обучение в системной биологии, микробная ферментация