Clear Sky Science · nl
Een multi-way SMILES-gebaseerd hypergraaf-inferentienetwerk voor reconstructie van metabolische modellen
Waarom het opvullen van metabolische blinde vlekken ertoe doet
Elke levende cel gonst van duizenden kleine chemische reacties die het in leven, groei en aanpassing houden. Wetenschappers bouwen grootschalige "kaarten" van deze reacties om betere microben te ontwerpen voor brandstoffen, te bestuderen hoe onze darmbacteriën de gezondheid beïnvloeden en zelfs nieuwe medicatiedoelen te zoeken. Maar veel van deze kaarten bevatten ontbrekende stukken: reacties die zeer waarschijnlijk in cellen plaatsvinden maar afwezig zijn in onze modellen. Dit artikel introduceert MuSHIN, een nieuw kunstmatig intelligentsiesysteem dat helpt die blinde vlekken op te vullen, waardoor onze kaarten van het metabolisme scherper, betrouwbaarder en veel nuttiger worden.
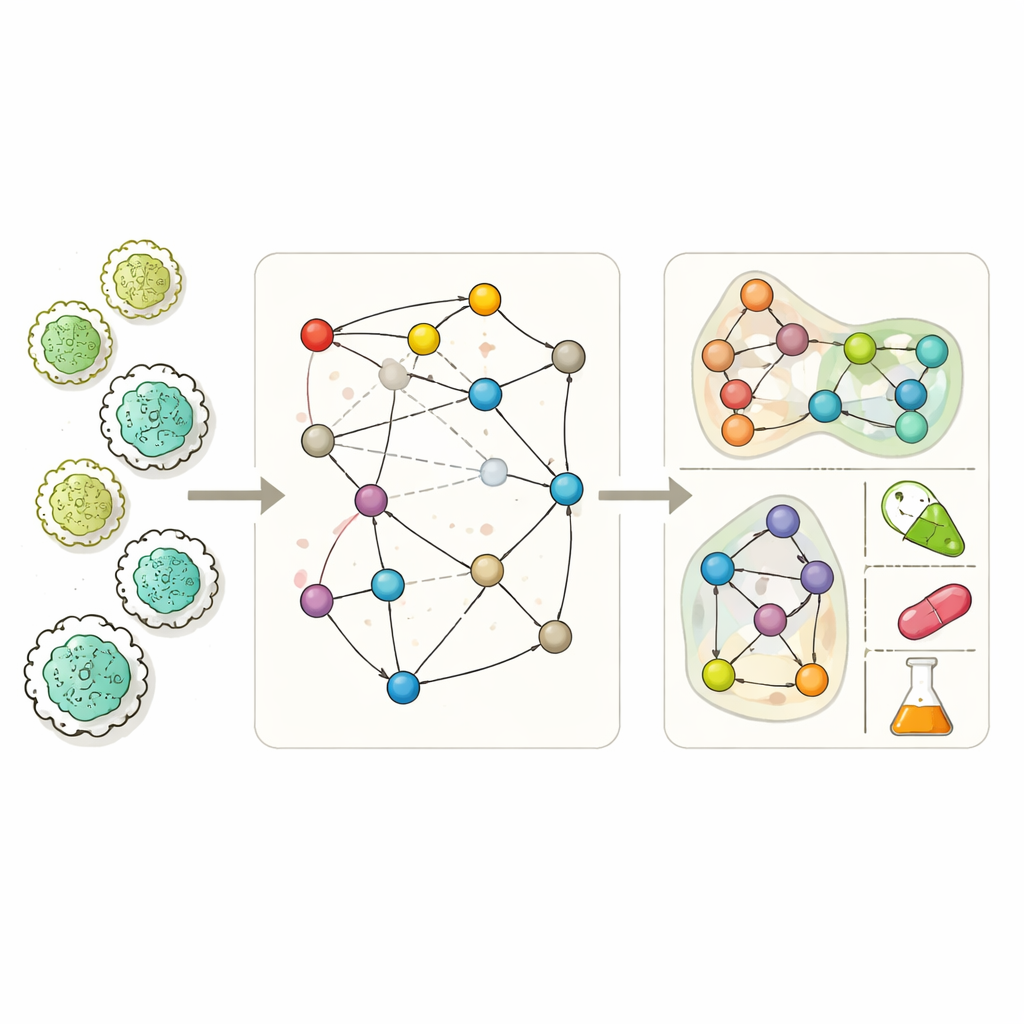
Beter kaarten van cellulaire chemie maken
Moderne genoom-schaal metabolische modellen streven ernaar vrijwel elke chemische reactie op te sommen die een organisme kan uitvoeren. Daarmee kunnen onderzoekers simuleren hoe een microbe groeit in verschillende omgevingen, welke bijproducten het uitscheidt en welke genen essentieel zijn voor overleving. Toch zijn deze modellen vaak onvolledig. Hiaten in biochemische kennis, fouten in genannotatie en beperkte experimenten laten gaten in de netwerken achter, waardoor gesimuleerde cellen soms niet groeien, bekende fermentatieproducten niet kunnen produceren of verkeerd voorspellen welke genen vitaal zijn. Bestaande "gap-filling"-hulpmiddelen proberen deze gaten te dichten, maar veel daarvan zijn sterk afhankelijk van conditiespecifieke experimentele gegevens of vereenvoudigen het netwerk zo veel dat ze de complexe, veel-molecuul interacties die echte reacties omvatten missen.
Van eenvoudige koppelingen naar rijke hyper-verbindingen
MuSHIN pakt dit probleem aan door het metabolisme op een meer getrouwe manier te representeren. In plaats van elke reactie te behandelen als een eenvoudige paargewijze koppeling tussen twee metabolieten, gebruikt het een hypergraaf, waarbij een enkele verbinding elke hoeveelheid moleculen tegelijk kan verbinden. Dit weerspiegelt de echte biochemie, waarin één reactie vaak meerdere substraten gelijktijdig in meerdere producten transformeert. MuSHIN verrijkt deze structuur vervolgens met chemische "betekenis." Het zet elk metaboliet en elke reactie, beschreven als SMILES-strings (een tekstcodering van moleculaire structuur), om in hoge-dimensionale numerieke vingerafdrukken met twee op transformatoren gebaseerde chemie-modellen genaamd ChemBERTa en RXNFP. Deze vingerafdrukken stellen het systeem in staat niet alleen te redeneren over wie met wie verbonden is in het netwerk, maar ook over hoe de moleculen en reacties er chemisch uitzien.
Hoe de leerengine werkt
Zodra de hypergraaf en chemische vingerafdrukken aanwezig zijn, leert MuSHIN echte reacties te onderscheiden van nepreacties. De auteurs bouwen trainingssets door bekende reacties uit hoogwaardige metabolische modellen te nemen en vervolgens "negatieve" voorbeelden te creëren door de deelnemers in elke reactie subtiel door elkaar te husselen, waarbij de algehele balans behouden blijft maar de chemie onwaarschijnlijk wordt. MuSHIN gebruikt een dubbele attentie-mechanisme om informatie heen en weer te sturen tussen metabolietknopen en reactie-hyperedges, waardoor het herhaaldelijk zowel zijn interne representatie van beide verfijnt. Dit attentieproces helpt het model zich te concentreren op de meest informatieve delen van het netwerk en de meest veelzeggende chemische kenmerken. In de laatste stap scoort MuSHIN elke reactie en geeft het de waarschijnlijkheid terug dat deze geldig is en dus een goede kandidaat om een gat te vullen.
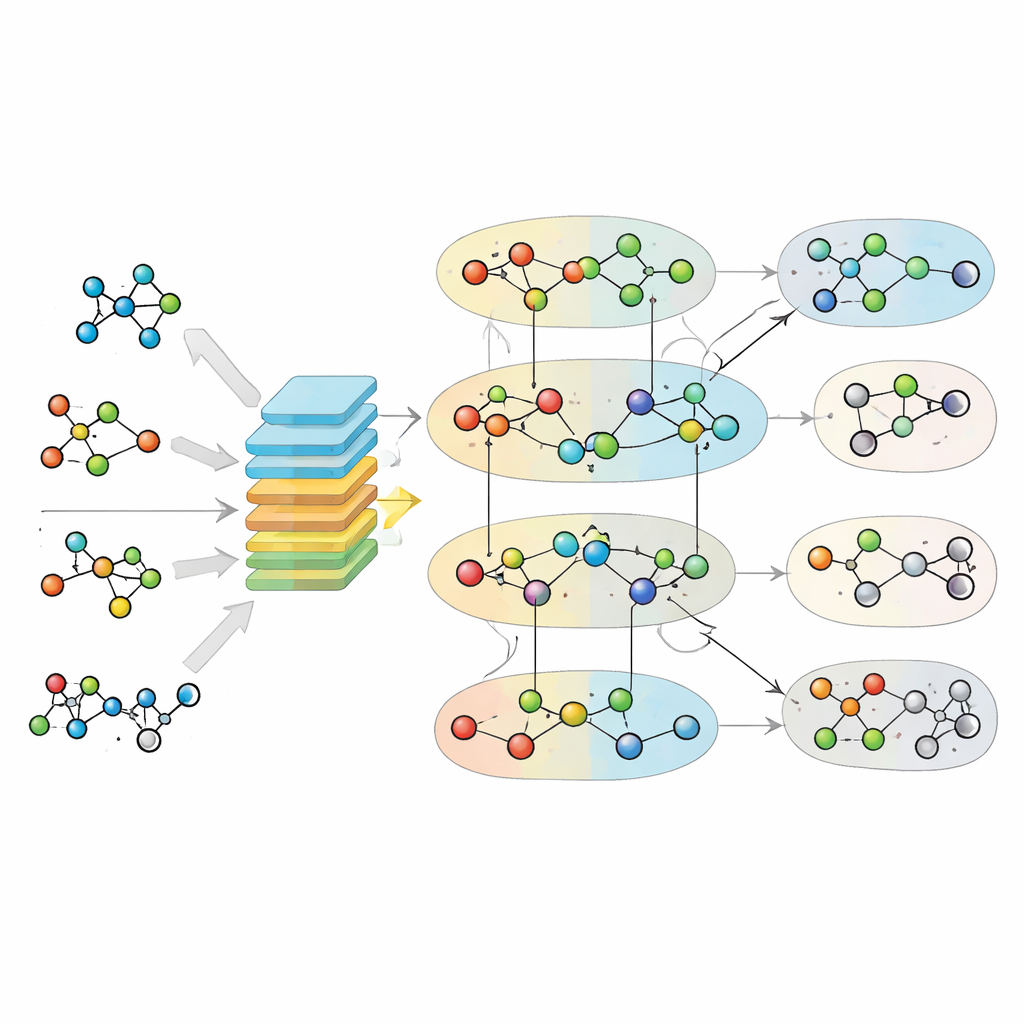
MuSHIN aan de tand voelen
De onderzoekers testten MuSHIN rigoureus op 926 metabolische modellen uit twee grote databases, waarbij ze systematisch bekende reacties verwijderden en het model vroegen deze te herstellen. Over een reeks kwaliteitsmaatregelen presteerde MuSHIN consequent beter dan meerdere toonaangevende hypergraaf- en deep-learning-methoden, in sommige gevallen met een prestatieverbetering van ongeveer 17 procentpunten. Remarkabel genoeg bleef het nauwkeurig zelfs wanneer tot 80% van de reacties was verwijderd, wat veerkracht toont in extreem onvolledige netwerken. In een andere reeks experimenten paste het team MuSHIN toe op 24 conceptmodellen van anaerobe bacteriën die bij fermentatie betrokken zijn. Door per organisme slechts de top 100 reacties toe te voegen die MuSHIN rangschikte, verbeterden zij dramatisch het vermogen van deze modellen om te voorspellen welke fermentatieproducten — zoals ethanol, melkzuur of mierenzuur — daadwerkelijk in experimenten worden waargenomen, terwijl concurrerende methoden veel meer toegevoegde reacties nodig hadden om bescheiden winst te behalen.
Verborgen doorgangen in het metabolisme onthullen
Een nadere blik op de reacties die MuSHIN voorstelt laat zien waarom de voorspellingen zo waardevol zijn. Bijna de helft van de voorgestelde toevoegingen blijken transport- en uitwisselingsreacties te zijn — stappen die moleculen door celmembranen verplaatsen of in en uit het gemodelleerde systeem brengen. Deze reacties zijn berucht ondervertegenwoordigd, maar bepalen vaak of een pad überhaupt flux kan dragen. Door dergelijke grensstappen correct te herstellen, opent MuSHIN geblokkeerde metabolische routes opnieuw en herstelt het ontbrekende fermentatieproducten in meerdere soorten. Het model lost ook meer ingewikkelde gaten op, zoals het herstellen van succinaatproductie in een darmbacterie door gecoördineerde transporters toe te voegen die een tak van de centrale energie-genererende cyclus compleet maken.
Wat dit betekent voor biologie en geneeskunde
Voor niet-specialisten is de kernboodschap dat MuSHIN onze virtuele cellen realistischer laat gedragen. Door een rijkere netwerkrepresentatie te combineren met chemisch-onderlegde AI kan het ontbrekende reacties opsporen die andere methoden over het hoofd zien, vooral bij slecht bestudeerde microben. Deze verbeterde nauwkeurigheid kan het ontwerpen van industriële stammen voor de productie van brandstoffen en chemicaliën versnellen, modellen van het menselijke darmmicrobioom aanscherpen en meer precieze simulaties van ziektemetabolisme en behandelingsreacties ondersteunen. Naarmate toekomstige uitbreidingen genen, regulatie en zelfs nog nooit eerder geziene reacties incorporeren, kunnen tools zoals MuSHIN centraal komen te staan in het omzetten van genomische gegevens in betrouwbare, voorspellende blauwdrukken van levende systemen.
Bronvermelding: Zhao, Y., Chen, Y., Yu, Y. et al. A multi-way SMILES-based hypergraph inference network for metabolic model reconstruction. Commun Biol 9, 531 (2026). https://doi.org/10.1038/s42003-026-09761-1
Trefwoorden: genoom-schaal metabolische modellen, reconstructie van metabolische netwerken, hypergraaf neurale netwerken, deep learning in systeembiologie, microbiële fermentatie