Clear Sky Science · it
Una rete di inferenza ipergrafica basata su SMILES multi-via per la ricostruzione di modelli metabolici
Perché colmare i punti ciechi metabolici conta
Ogni cellula vivente è animata da migliaia di piccole reazioni chimiche che la mantengono in vita, la fanno crescere e le permettono di adattarsi. Gli scienziati costruiscono «mappe» su larga scala di queste reazioni per progettare microbi migliori per la produzione di combustibili, studiare come i batteri intestinali influenzano la salute e persino cercare nuovi bersagli farmacologici. Tuttavia molte di queste mappe presentano dei pezzi mancanti: reazioni che molto probabilmente avvengono nelle cellule ma sono assenti nei nostri modelli. Questo articolo presenta MuSHIN, un nuovo sistema di intelligenza artificiale che aiuta a colmare quei punti ciechi, rendendo le nostre mappe del metabolismo più nitide, più affidabili e molto più utili.
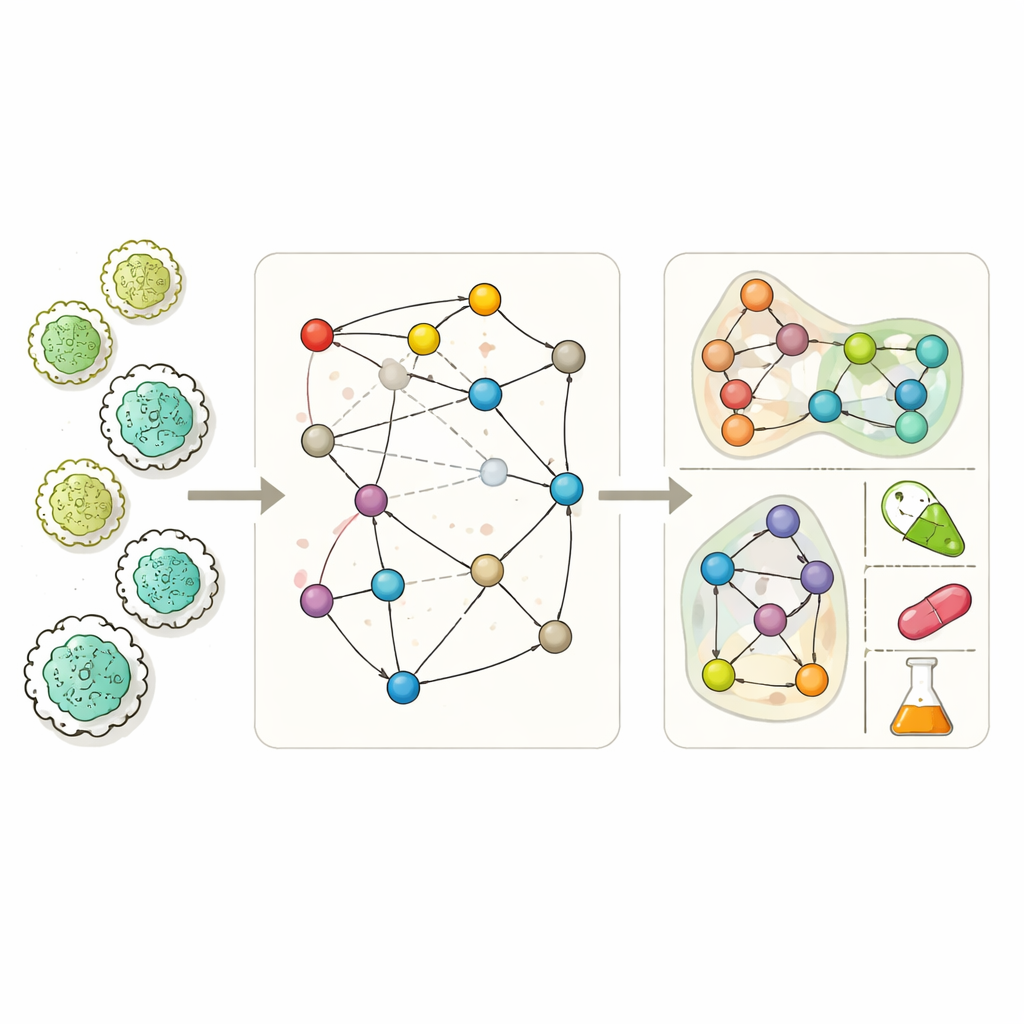
Costruire mappe migliori della chimica cellulare
I moderni modelli metabolici su scala genomica mirano a elencare quasi tutte le reazioni chimiche che un organismo può svolgere. Con essi, i ricercatori possono simulare come un microbo cresce in ambienti diversi, quali sottoprodotti secerne e quali geni sono essenziali per la sopravvivenza. Eppure questi modelli sono spesso incompleti. Lacune nella conoscenza biochimica, errori nell'annotazione del genoma e dati sperimentali limitati lasciano buchi nelle reti, perciò le cellule simulate a volte non crescono, non possono produrre noti prodotti di fermentazione o prevedono in modo errato quali geni siano vitali. Gli strumenti esistenti per il «gap-filling» cercano di tappare questi buchi, ma molti dipendono fortemente da dati sperimentali specifici per certe condizioni o semplificano la rete a tal punto da perdere le complesse interazioni a più molecole che le reazioni reali implicano.
Da semplici collegamenti a ricche iper-connessioni
MuSHIN affronta questo problema rappresentando il metabolismo in modo più fedele. Invece di trattare ogni reazione come un semplice collegamento binario tra due metaboliti, utilizza un ipergrafo, dove una singola connessione può legare insieme qualsiasi numero di molecole contemporaneamente. Questo rispecchia la biochimica reale, nella quale una reazione spesso trasforma più substrati in più prodotti simultaneamente. MuSHIN arricchisce quindi questa struttura con un «significato» chimico. Converte ogni metabolita e reazione, descritti come stringhe SMILES (una codifica testuale della struttura molecolare), in impronte numeriche ad alta dimensionalità usando due modelli di chimica basati su transformer chiamati ChemBERTa e RXNFP. Queste impronte permettono al sistema di ragionare non solo su chi è connesso a chi nella rete, ma anche su come appaiono chimicamente le molecole e le reazioni.
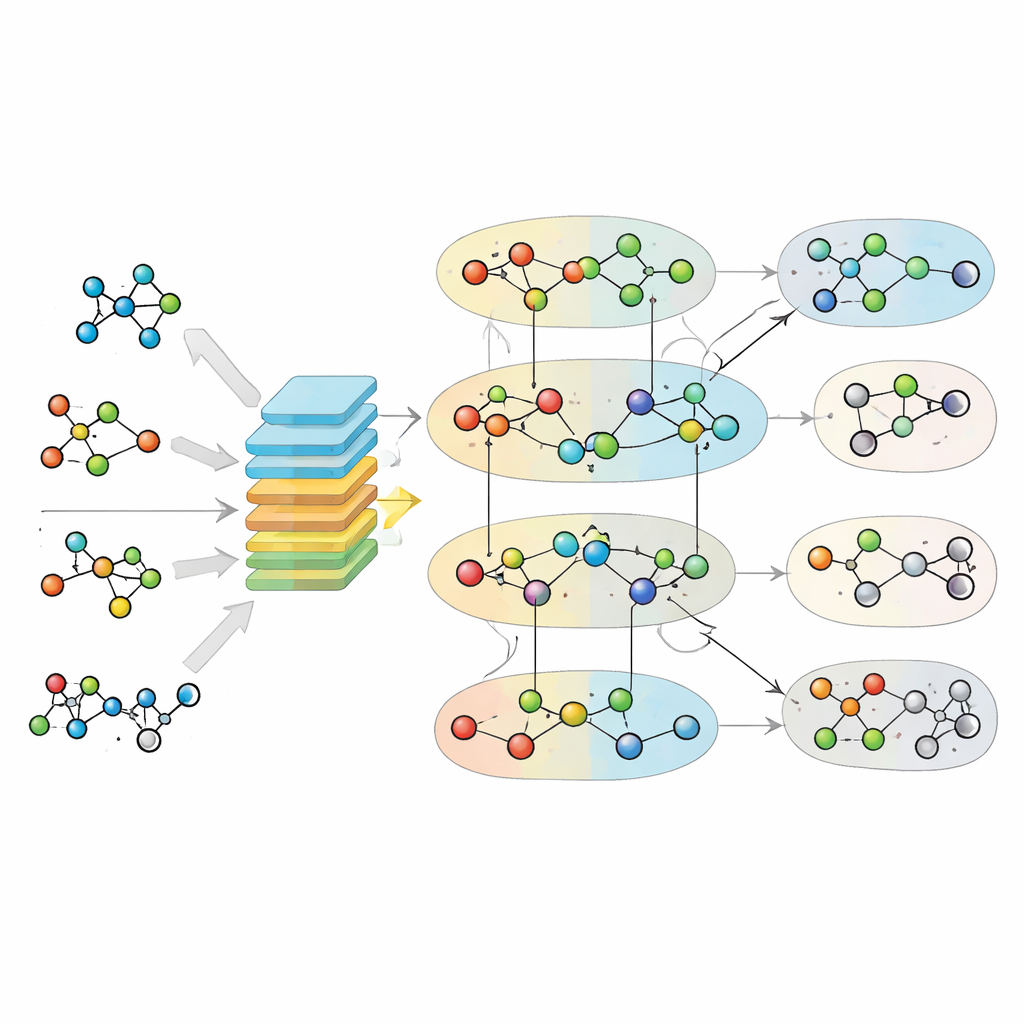
Come funziona il motore di apprendimento
Una volta che l'ipergrafo e le impronte chimiche sono in posizione, MuSHIN impara a distinguere le reazioni reali da quelle false. Gli autori costruiscono set di addestramento prendendo reazioni note da modelli metabolici di alta qualità e poi creando esempi «negativi» rimescolando sottilmente i partecipanti di ciascuna reazione, preservando l'equilibrio complessivo ma rendendo la chimica implausibile. MuSHIN usa un meccanismo di attenzione duale per scambiare informazioni tra i nodi metaboliti e gli iperarchi delle reazioni, raffinando ripetutamente la sua rappresentazione interna di entrambi. Questo processo di attenzione aiuta il modello a concentrarsi sulle parti più informative della rete e sulle caratteristiche chimiche più indicative. Nella fase finale, MuSHIN valuta ogni reazione, restituendo quanto è probabile che sia valida e quindi un buon candidato per colmare un gap.
Mettere MuSHIN alla prova
I ricercatori hanno testato rigorosamente MuSHIN su 926 modelli metabolici provenienti da due grandi database, rimuovendo sistematicamente reazioni note e chiedendo al modello di recuperarle. Su una serie di misure di qualità, MuSHIN ha costantemente superato diversi metodi di punta basati su ipergrafi e deep learning, in alcuni casi migliorando le prestazioni di circa 17 punti percentuali. Notevolmente, è rimasto accurato anche quando fino all'80% delle reazioni era stato rimosso, dimostrando resilienza in reti estremamente incomplete. In un altro insieme di esperimenti, il team ha applicato MuSHIN a 24 modelli preliminari di batteri anaerobici coinvolti nella fermentazione. Aggiungendo solo le prime 100 reazioni che MuSHIN ha classificato per ciascun organismo, hanno migliorato drasticamente la capacità di questi modelli di prevedere quali prodotti di fermentazione — come etanolo, acido lattico o acido formico — siano effettivamente osservati negli esperimenti, mentre metodi concorrenti hanno avuto bisogno di molte più reazioni aggiunte per ottenere guadagni modesti.
Scoprire ingressi nascosti nel metabolismo
Uno sguardo più attento alle reazioni proposte da MuSHIN rivela perché le sue previsioni sono così preziose. Quasi la metà delle aggiunte suggerite si è rivelata essere reazioni di trasporto e scambio — passaggi che spostano molecole attraverso le membrane cellulari o dentro e fuori dal sistema modellato. Queste reazioni sono notoriamente sottorappresentate ma spesso controllano se un percorso può avere flusso o meno. Ripristinando correttamente questi passaggi di confine, MuSHIN riapre rotte metaboliche bloccate e recupera prodotti di fermentazione mancanti in più specie. Il modello risolve anche lacune più intricate, ad esempio ripristinando la produzione di succinato in un batterio intestinale aggiungendo trasportatori coordinati che completano un ramo del ciclo centrale di produzione di energia.
Cosa significa questo per la biologia e la medicina
Per i non specialisti, il messaggio chiave è che MuSHIN fa comportare le nostre cellule virtuali più come quelle reali. Combinando una rappresentazione di rete più ricca con un'IA esperta di chimica, può individuare reazioni mancanti che altri metodi trascurano, specialmente in microbi poco studiati. Questa maggiore accuratezza potrebbe accelerare la progettazione di ceppi industriali per la produzione di combustibili e prodotti chimici, affinare i modelli del microbioma umano e supportare simulazioni più precise del metabolismo nelle malattie e nelle risposte ai trattamenti. Man mano che estensioni future incorporeranno geni, regolazione e persino nuove reazioni mai osservate prima, strumenti come MuSHIN potrebbero diventare centrali per trasformare i dati genomici in progetti affidabili e predittivi dei sistemi viventi.
Citazione: Zhao, Y., Chen, Y., Yu, Y. et al. A multi-way SMILES-based hypergraph inference network for metabolic model reconstruction. Commun Biol 9, 531 (2026). https://doi.org/10.1038/s42003-026-09761-1
Parole chiave: modelli metabolici su scala genomica, ricostruzione di reti metaboliche, reti neurali su ipergrafi, deep learning in biologia dei sistemi, fermentazione microbica