Clear Sky Science · es
Una red de inferencia hipergráfica basada en SMILES multivía para la reconstrucción de modelos metabólicos
Por qué importa rellenar los puntos ciegos metabólicos
Cada célula viva bulle con miles de pequeñas reacciones químicas que la mantienen viva, creciendo y adaptándose. Los científicos construyen “mapas” a gran escala de estas reacciones para diseñar mejores microbios productores de combustibles, estudiar cómo nuestras bacterias intestinales influyen en la salud e incluso buscar nuevos blancos farmacológicos. Pero muchos de estos mapas están llenos de piezas faltantes: reacciones que casi con seguridad ocurren en las células pero que están ausentes en nuestros modelos. Este artículo presenta MuSHIN, un nuevo sistema de inteligencia artificial que ayuda a rellenar esos puntos ciegos, afinando nuestros mapas del metabolismo, haciéndolos más fiables y mucho más útiles.
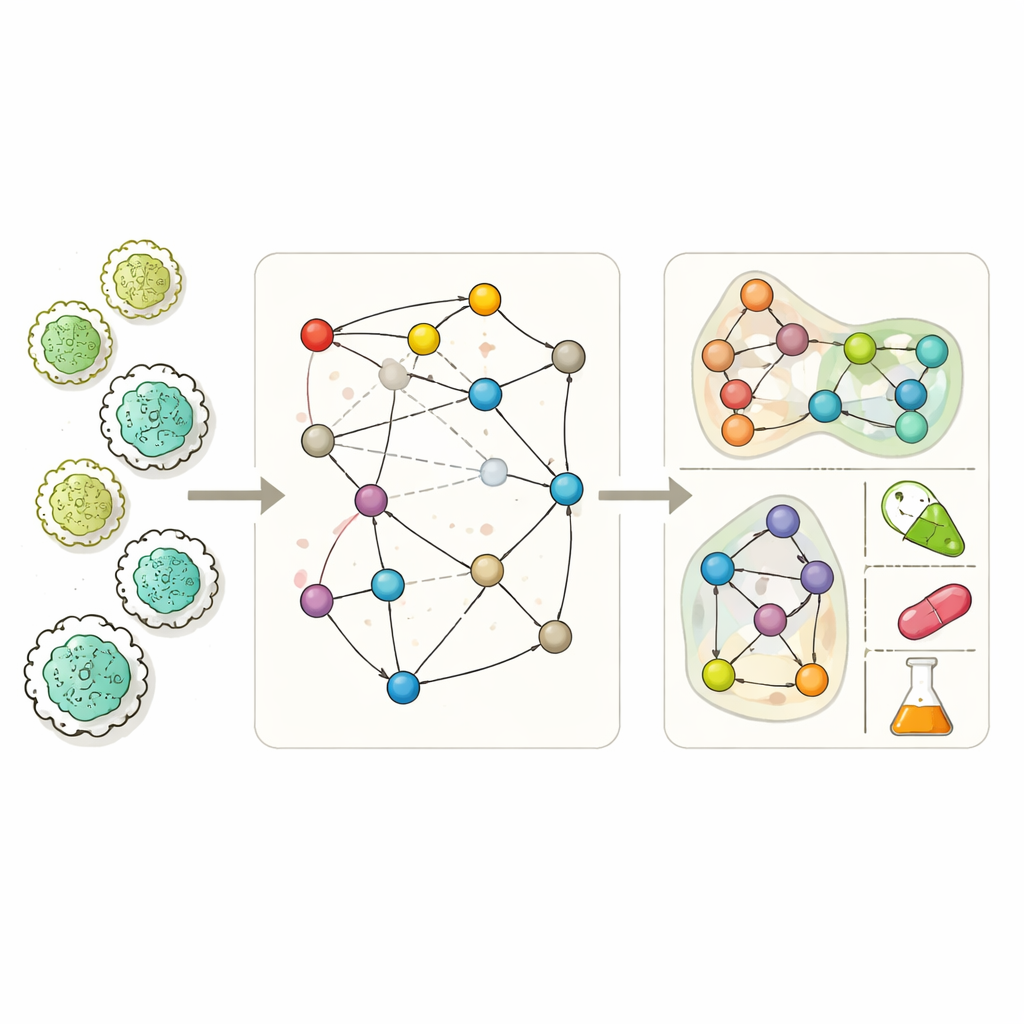
Construir mejores mapas de la química celular
Los modelos metabólicos a escala genómica modernos buscan listar casi todas las reacciones químicas que un organismo puede llevar a cabo. Con ellos, los investigadores pueden simular cómo crece un microbio en distintos entornos, qué subproductos secreta y qué genes son esenciales para la supervivencia. Sin embargo, estos modelos suelen estar incompletos. Lagunas en el conocimiento bioquímico, errores en la anotación del genoma y experimentos limitados dejan huecos en las redes, de modo que las células simuladas a veces no crecen, no pueden producir productos de fermentación conocidos o predicen erróneamente qué genes son vitales. Las herramientas existentes de “llenado de huecos” intentan tapar estas lagunas, pero muchas dependen en gran medida de datos experimentales específicos de condiciones o simplifican tanto la red que pasan por alto las interacciones complejas entre muchos compuestos que implican las reacciones reales.
De enlaces simples a hiperconexiones ricas
MuSHIN aborda este problema representando el metabolismo de una manera más fiel. En vez de tratar cada reacción como un enlace pareado simple entre dos metabolitos, emplea un hipergráfico, donde una única conexión puede unir simultáneamente cualquier número de moléculas. Esto refleja la bioquímica real, en la que una reacción a menudo transforma varios sustratos en varios productos a la vez. MuSHIN enriquece esta estructura con “significado” químico: convierte cada metabolito y reacción, descritos como cadenas SMILES (una codificación textual de la estructura molecular), en huellas numéricas de alta dimensión mediante dos modelos transformer de química llamados ChemBERTa y RXNFP. Estas huellas permiten al sistema razonar no solo sobre quién se conecta con quién en la red, sino también sobre cómo son químicamente las moléculas y las reacciones.
Cómo funciona el motor de aprendizaje
Una vez que el hipergráfico y las huellas químicas están en su sitio, MuSHIN aprende a distinguir reacciones reales de las falsas. Los autores construyen conjuntos de entrenamiento tomando reacciones conocidas de modelos metabólicos de alta calidad y luego creando ejemplos “negativos” al reordenar sutilmente los participantes de cada reacción, conservando el balance global pero volviendo la química implausible. MuSHIN usa un mecanismo de atención dual para pasar información de ida y vuelta entre los nodos metabolito y las hiperaristas de reacción, refinando repetidamente su representación interna de ambos. Este proceso de atención ayuda al modelo a centrarse en las partes más informativas de la red y en las características químicas más reveladoras. En el paso final, MuSHIN puntúa cada reacción, indicando cuán probable es que sea válida y, por tanto, una buena candidata para rellenar un hueco.
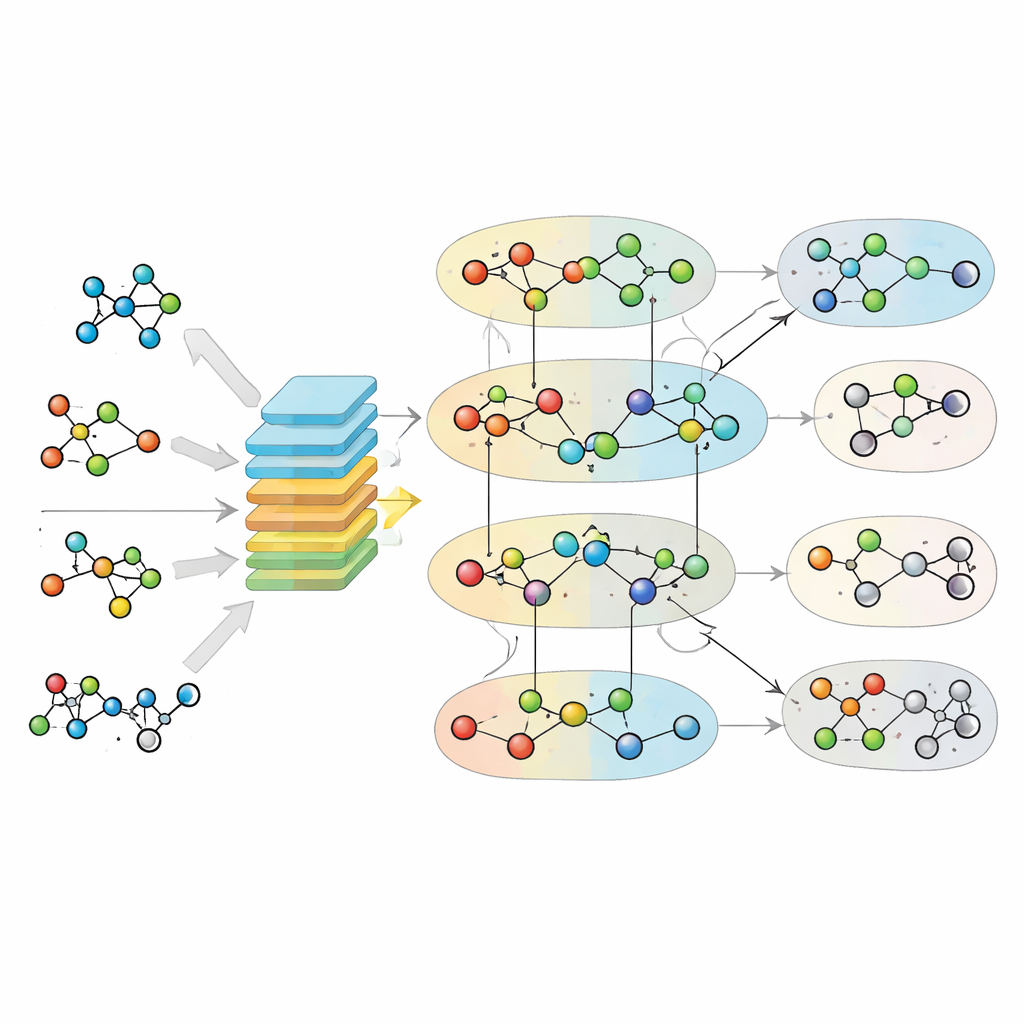
Poniendo a prueba a MuSHIN
Los investigadores probaron rigurosamente MuSHIN en 926 modelos metabólicos de dos bases de datos principales, eliminando sistemáticamente reacciones conocidas y pidiendo al modelo que las recuperara. A lo largo de varias medidas de calidad, MuSHIN superó de forma consistente a varios métodos líderes basados en hipergráficas y aprendizaje profundo, en algunos casos mejorando el rendimiento en alrededor de 17 puntos porcentuales. De forma notable, mantuvo la precisión incluso cuando hasta el 80 % de las reacciones fueron eliminadas, mostrando resiliencia en redes extremadamente incompletas. En otro conjunto de experimentos, el equipo aplicó MuSHIN a 24 modelos preliminares de bacterias anaerobias implicadas en la fermentación. Al añadir solo las 100 reacciones mejor clasificadas por MuSHIN para cada organismo, mejoraron dramáticamente la capacidad de estos modelos para predecir qué productos de fermentación—como etanol, ácido láctico o ácido fórmico—se observan realmente en experimentos, mientras que los métodos competidores necesitaron muchas más reacciones añadidas para lograr mejoras modestas.
Descubrir pasadizos ocultos en el metabolismo
Una mirada más detenida a las reacciones que propone MuSHIN revela por qué sus predicciones son tan valiosas. Casi la mitad de sus adiciones sugeridas resultan ser reacciones de transporte e intercambio—pasos que mueven moléculas a través de membranas celulares o dentro y fuera del sistema modelado. Estas reacciones están notoriamente subrepresentadas, pero con frecuencia controlan si una ruta puede transportar flujo alguno. Al restaurar correctamente tales pasos fronterizos, MuSHIN reabre rutas metabólicas bloqueadas y recupera productos de fermentación faltantes en múltiples especies. El modelo también resuelve huecos más intrincados, como restaurar la producción de succinato en una bacteria intestinal añadiendo transportadores coordinados que completan una rama del ciclo central de generación de energía.
Qué significa esto para la biología y la medicina
Para los no especialistas, el mensaje clave es que MuSHIN hace que nuestras células virtuales se comporten más como las reales. Al combinar una representación de red más rica con una IA sensible a la química, puede detectar reacciones faltantes que otros métodos pasan por alto, especialmente en microbios poco estudiados. Esta mayor precisión podría acelerar el diseño de cepas industriales para producir combustibles y químicos, afinar los modelos del microbioma humano y apoyar simulaciones más precisas del metabolismo en enfermedad y respuesta a tratamientos. A medida que futuras extensiones incorporen genes, regulación e incluso nuevas reacciones nunca antes vistas, herramientas como MuSHIN podrían convertirse en piezas centrales para transformar datos genómicos en planos predictivos, fiables de los sistemas vivos.
Cita: Zhao, Y., Chen, Y., Yu, Y. et al. A multi-way SMILES-based hypergraph inference network for metabolic model reconstruction. Commun Biol 9, 531 (2026). https://doi.org/10.1038/s42003-026-09761-1
Palabras clave: modelos metabólicos a escala genómica, reconstrucción de redes metabólicas, redes neuronales de hipergráficas, aprendizaje profundo en biología de sistemas, fermentación microbiana