Clear Sky Science · fr
Un réseau d'inférence hypergraphe multi-voies basé sur les SMILES pour la reconstruction de modèles métaboliques
Pourquoi combler les angles morts métaboliques importe
Chaque cellule vivante fourmille de milliers de petites réactions chimiques qui la maintiennent en vie, lui permettent de croître et de s'adapter. Les scientifiques dressent de vastes « cartes » de ces réactions pour concevoir de meilleurs microbes producteurs de carburant, étudier l'impact des bactéries intestinales sur la santé ou encore rechercher de nouvelles cibles médicamenteuses. Mais nombre de ces cartes contiennent des pièces manquantes : des réactions qui ont très probablement lieu en cellule mais absentent de nos modèles. Cet article présente MuSHIN, un nouveau système d'intelligence artificielle qui aide à combler ces angles morts, rendant nos cartes du métabolisme plus nettes, plus fiables et bien plus utiles.
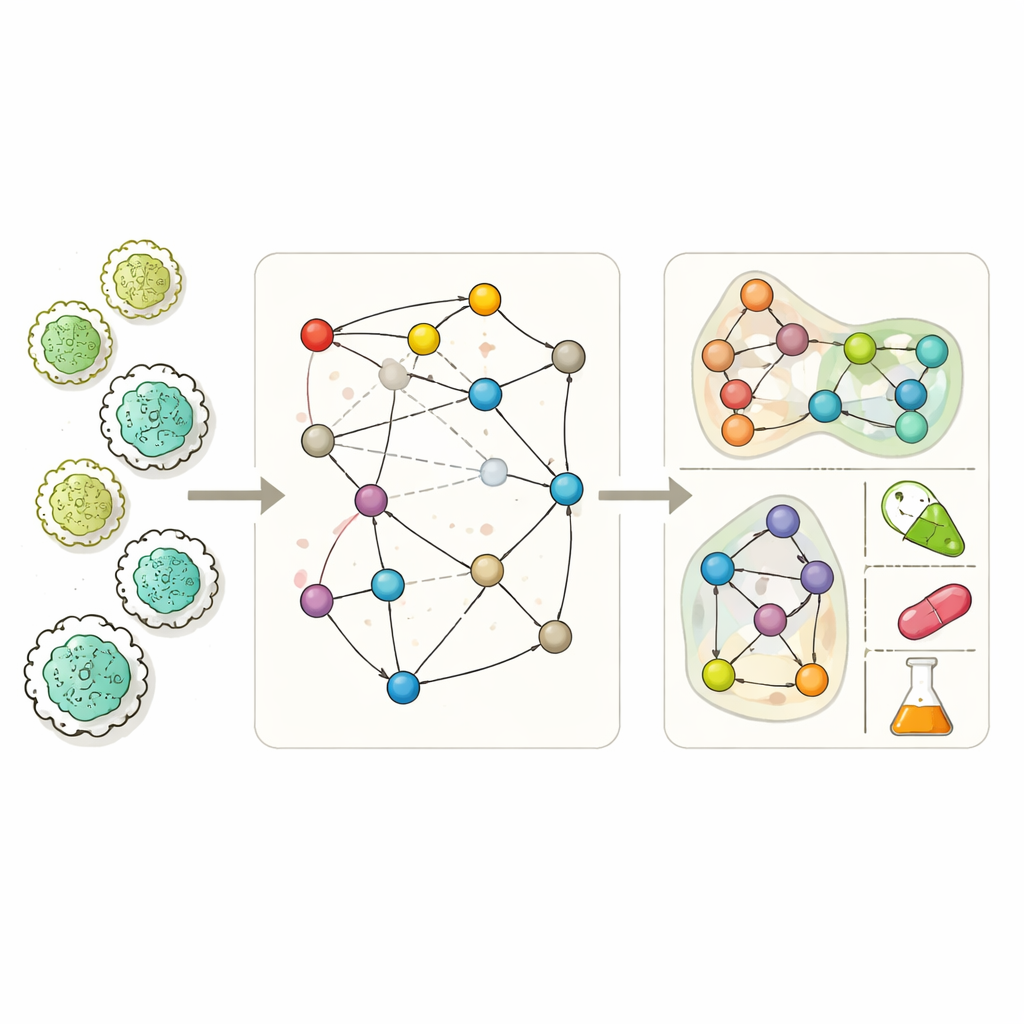
Construire de meilleures cartes de la chimie cellulaire
Les modèles métaboliques modernes à l'échelle du génome visent à répertorier quasiment toutes les réactions chimiques qu'un organisme peut réaliser. Grâce à eux, les chercheurs peuvent simuler la croissance d'un microbe dans différents environnements, les sous-produits qu'il sécrète et les gènes essentiels à sa survie. Pourtant ces modèles sont souvent incomplets. Les lacunes dans les connaissances biochimiques, les erreurs d'annotation génomique et le nombre limité d'expériences laissent des trous dans les réseaux : les cellules simulées échouent parfois à croître, ne peuvent pas produire des produits de fermentation connus ou prédisent à tort quels gènes sont vitaux. Les outils existants de « comblement de lacunes » tentent de boucher ces trous, mais beaucoup dépendent fortement de données expérimentales spécifiques aux conditions testées ou simplifient le réseau au point d'ignorer les interactions complexes à plusieurs molécules que les réactions réelles impliquent.
Des liens simples à des hyper-connexions riches
MuSHIN aborde ce problème en représentant le métabolisme de manière plus fidèle. Plutôt que de traiter chaque réaction comme un simple lien par paire entre deux métabolites, il utilise un hypergraphe, où une seule connexion peut relier un nombre arbitraire de molécules simultanément. Cela reflète la biochimie réelle, dans laquelle une réaction transforme souvent plusieurs substrats en plusieurs produits à la fois. MuSHIN enrichit ensuite cette structure d'une « signification » chimique. Il convertit chaque métabolite et réaction, décrits par des chaînes SMILES (un codage textuel de la structure moléculaire), en empreintes numériques de haute dimension à l'aide de deux modèles de chimie basés sur des transformeurs, appelés ChemBERTa et RXNFP. Ces empreintes permettent au système de raisonner non seulement sur qui se connecte à qui dans le réseau, mais aussi sur l'apparence chimique des molécules et des réactions.
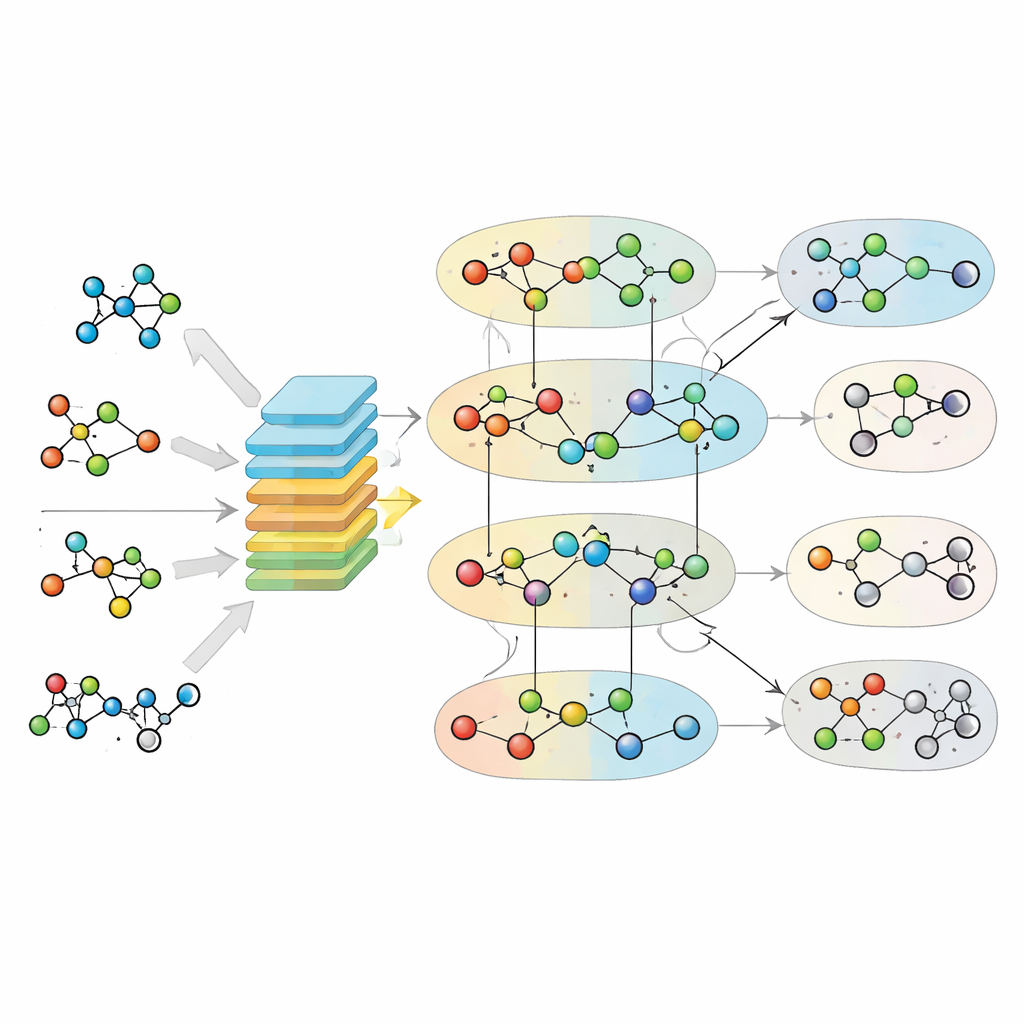
Comment fonctionne le moteur d'apprentissage
Une fois l'hypergraphe et les empreintes chimiques en place, MuSHIN apprend à distinguer les réactions réelles des fausses. Les auteurs constituent des jeux d'entraînement en prenant des réactions connues issues de modèles métaboliques de haute qualité, puis en créant des exemples « négatifs » en remaniant subtilement les participants de chaque réaction, préservant l'équilibre global mais rendant la chimie implausible. MuSHIN utilise un mécanisme d'attention dual pour faire circuler l'information entre les nœuds métabolites et les hyperarêtes de réaction, affinant à plusieurs reprises sa représentation interne des deux. Ce processus d'attention aide le modèle à se concentrer sur les parties les plus informatives du réseau et sur les caractéristiques chimiques les plus révélatrices. À l'étape finale, MuSHIN note chaque réaction, indiquant la probabilité qu'elle soit valide et qu'elle constitue donc un bon candidat pour combler une lacune.
Mettre MuSHIN à l'épreuve
Les chercheurs ont testé rigoureusement MuSHIN sur 926 modèles métaboliques provenant de deux bases de données majeures, en retirant systématiquement des réactions connues et en demandant au modèle de les retrouver. Sur une gamme de mesures de qualité, MuSHIN a systématiquement surpassé plusieurs méthodes de pointe basées sur les hypergraphes et l'apprentissage profond, améliorant dans certains cas les performances d'environ 17 points de pourcentage. Remarquablement, il est resté précis même lorsque jusqu'à 80 % des réactions avaient été supprimées, montrant une résilience dans des réseaux extrêmement incomplets. Dans une autre série d'expériences, l'équipe a appliqué MuSHIN à 24 modèles provisoires de bactéries anaérobies impliquées dans la fermentation. En ajoutant seulement les 100 meilleures réactions classées par MuSHIN pour chaque organisme, ils ont considérablement amélioré la capacité de ces modèles à prédire quels produits de fermentation — tels que l'éthanol, l'acide lactique ou l'acide formique — sont effectivement observés en expérimentation, alors que les méthodes concurrentes ont eu besoin d'ajouter beaucoup plus de réactions pour obtenir des gains modestes.
Dénicher des passerelles cachées dans le métabolisme
Un examen plus approfondi des réactions proposées par MuSHIN révèle pourquoi ses prédictions sont si précieuses. Près de la moitié de ses ajouts suggérés se révèlent être des réactions de transport et d'échange — des étapes qui déplacent des molécules à travers les membranes cellulaires ou à l'entrée et à la sortie du système modélisé. Ces réactions sont notoirement sous-représentées mais contrôlent souvent si une voie peut supporter un flux ou non. En restaurant correctement de telles étapes frontières, MuSHIN rouvre des itinéraires métaboliques bloqués et récupère des produits de fermentation manquants chez plusieurs espèces. Le modèle résout également des lacunes plus complexes, par exemple en restaurant la production de succinate dans une bactérie intestinale en ajoutant des transporteurs coordonnés qui complètent une branche du cycle central de production d'énergie.
Ce que cela signifie pour la biologie et la médecine
Pour les non-spécialistes, le message clé est que MuSHIN fait en sorte que nos cellules virtuelles se comportent davantage comme des cellules réelles. En combinant une représentation de réseau plus riche avec une IA consciente de la chimie, il peut repérer des réactions manquantes que d'autres méthodes négligent, en particulier chez des microbes peu étudiés. Cette amélioration de la précision pourrait accélérer la conception de souches industrielles pour la production de carburants et de produits chimiques, affiner les modèles du microbiome intestinal humain et soutenir des simulations plus précises du métabolisme en pathologie et des réponses aux traitements. À mesure que des extensions futures intégreront les gènes, la régulation et même de nouvelles réactions jamais observées auparavant, des outils comme MuSHIN pourraient devenir centraux pour transformer les données génomiques en plans fiables et prédictifs des systèmes vivants.
Citation: Zhao, Y., Chen, Y., Yu, Y. et al. A multi-way SMILES-based hypergraph inference network for metabolic model reconstruction. Commun Biol 9, 531 (2026). https://doi.org/10.1038/s42003-026-09761-1
Mots-clés: modèles métaboliques à l'échelle du génome, reconstruction de réseaux métaboliques, réseaux neuronaux sur hypergraphes, apprentissage profond en biologie des systèmes, fermentation microbienne