Clear Sky Science · sv
Automatisk RECIST-klassificering av tumörsvar genom promptstyrda stora språkmodeller
Varför detta är viktigt för personer med cancer
När någon behandlas för cancer förlitar sig läkare på undersökningsrapporter för att avgöra om en behandling fungerar, bör ändras eller kan avslutas. Att läsa och sammanfatta dessa rapporter tar tid och kan vara känsligt för små misstag. Denna studie undersöker om en stor språkmodell, en typ av artificiell intelligens som förstår text, kan hjälpa läkare att säkert sortera undersökningsrapporter i standardiserade svarskategorier samtidigt som patientdata hålls kvar inom sjukhusets väggar.
Hur läkare vanligen följer tumörförändringar
I onkologi används CT‑skanningar rutinmässigt för att kontrollera hur tumörer svarar på behandling. Läkare använder ofta regelsamlingen RECIST, som grupperar en patients situation i kategorier som komplett respons, partiell respons, stabil sjukdom, progressiv sjukdom eller baslinje innan behandling påbörjats. Även om många sjukhus använder semistrukturerade mallar för dessa rapporter skrivs det slutgiltiga omdömet ofta i fri text. Det innebär att en mänsklig expert måste tolka mätningar, jämföra dem med tidigare skanningar och översätta allt detta till en av standardkategorierna — en process som kan vara mödosam och ibland inkonsekvent.
Vad forskarna bad datorn göra
Teamet vid ett tysk universitetssjukhus testade om en allmän språkmodell, LLaMA 3.3 med 70 miljarder parametrar, kunde läsa verkliga CT‑radiologirapporter från cancerpatienter och tilldela korrekt RECIST‑kategori utan extra träning på lokala data. De arbetade helt offline inom sjukhusets säkra infrastruktur så att ingen patientinformation lämnade institutionen. Innan modellen fick se rapporterna togs de ursprungliga svarsetiketterna bort, men alla mätningar och referensvärden behölls så att systemet kunde jämföra nuvarande tumörstorlekar med tidigare baslinjer eller minsta uppmätta storlekar.
Olika sätt att styra AI:n
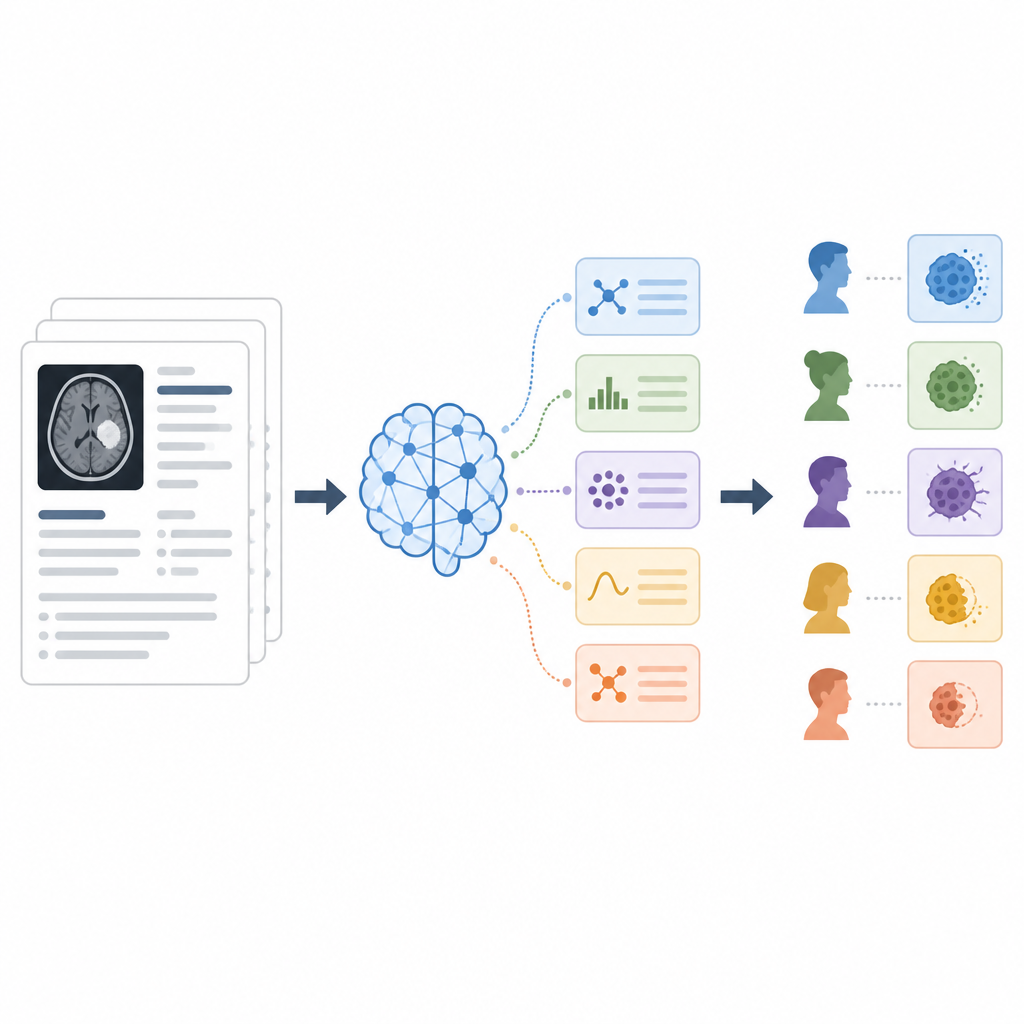
Forskarna provade tre sätt att instruera modellen, så kallade prompting‑strategier. I zero‑shot‑ansatsen fick modellen enbart rapporten och en kort instruktion att ange en av de fem kategorierna. I few‑shot‑ansatsen visade de modellen flera exempelutdrag ur rapporter tillsammans med rätt kategori och lärde den genom demonstration. I chain‑of‑thought‑ansatsen bad de modellen förklara sitt resonemang steg för steg i vanlig text innan den angav en slutgiltig kategori, och flera oberoende resonemangskörningar kombinerades för att nå en majoritetsbedömning. Över 142 rapporter mätte de hur ofta AI:n stämde överens med mänskliga experter med hjälp av noggrannhet och vanliga klassificeringsmått.
Hur väl systemet motsvarade mänskliga läsare
Chain‑of‑thought‑strategin presterade bäst, klassificerade korrekt omkring fyra av fem rapporter totalt och uppnådde den bästa balansen mellan att fånga sanna positiva och undvika falska larm. Den var särskilt bra på att skilja partiell respons från stabil sjukdom, två kategorier som ofta förväxlas, och förbättrade prestanda för mer sällsynta utfall såsom komplett respons. Zero‑shot‑prompting klarade sig redan förvånansvärt bra, ibland bättre än att ge några exempel, vilket tyder på att hur instruktionerna är formulerade kan spela större roll än att enbart lägga till fler träningsexempel. Few‑shot‑prompting hjälpte vissa svåra kategorier men kunde också introducera nya fel när det lilla exemplet inte fullt ut speglade variationen i verkliga rapporter.
Vad felen och begränsningarna visar
Genom att studera förväxlingsmatriser, som visar vilka kategorier systemet tenderade att blanda ihop, fann författarna att chain‑of‑thought‑metoden gav färre systematiska fel och ett mönster som liknade noggrant kliniskt resonerande. Modellen hade dock fortfarande svårt i gränsfall där texten inte tydligt skiljde mellan en startskanning och en senare skanning utan synlig kvarvarande tumör. Studien använde rapporter från en enda institution som följde standardiserade mallar, så resultaten kan skilja sig i sjukhus med friare skrivstilar. Arbetet fokuserade på en rapport i taget och inkorporerade ännu inte längre historik över flera besök, vilket krävs för vissa formella prövningsregler.
Vad detta kan innebära för framtida cancervård
För en lekmannaläsare är huvudbudskapet att en textläsande AI kan assistera radiologer genom att dubbelkolla om slutsatserna i CT‑rapporter stämmer överens med de siffror och regler som styr cancerbehandlingsbeslut. Att köra systemet helt offline skyddar patientsekretessen samtidigt som det erbjuder ett skalbart verktyg som kan minska manuellt arbete och lyfta fram inkonsekvenser. Författarna betonar att sådana modeller bör stödja, inte ersätta, kliniker och bör valideras över fler sjukhus och integreras med mänsklig granskning. Om de utvecklas varsamt kan system som detta bidra till att säkerställa att berättelsen i en undersökningsrapport stämmer bättre överens med fakta i bilderna och de standarder som används för att styra behandlingen.
Citering: Mergen, M., Busch, F., Sauter, A.P. et al. Automated RECIST tumor response classification through prompt-guided large language models. Sci Rep 16, 16433 (2026). https://doi.org/10.1038/s41598-026-54979-y
Nyckelord: radiologi-AI, tumörsvar, RECIST, stora språkmodeller, onkologirapportering