Clear Sky Science · nl
Geautomatiseerde RECIST-classificatie van tumorrepons via prompt-gestuurde grote taalmodellen
Waarom dit belangrijk is voor mensen met kanker
Wanneer iemand behandeld wordt voor kanker, vertrouwen artsen op scanrapporten om te beslissen of een therapie werkt, gewijzigd moet worden of kan worden stopgezet. Het lezen en samenvatten van deze rapporten kost veel tijd en kan gevoelig zijn voor kleine fouten. Deze studie onderzoekt of een groot taalmodel, een vorm van kunstmatige intelligentie die tekst begrijpt, artsen veilig kan helpen om scanrapporten in standaardresponscategorieën te sorteren terwijl patiëntgegevens binnen het ziekenhuis blijven.
Hoe artsen gewoonlijk tumeveranderingen bijhouden
In de oncologie worden CT-scans routinematig gebruikt om te controleren hoe tumoren op behandeling reageren. Artsen gebruiken vaak een regelsysteem dat RECIST heet, dat de situatie van een patiënt indeelt in categorieën zoals volledige respons, gedeeltelijke respons, stabiele ziekte, progressieve ziekte of baseline voordat de behandeling is gestart. Hoewel veel ziekenhuizen semi-gestructureerde sjablonen voor deze rapporten gebruiken, wordt het uiteindelijke oordeel over de respons vaak in vrije tekst vastgelegd. Dat betekent dat een menselijke expert metingen moet interpreteren, deze met eerdere scans moet vergelijken en alles moet vertalen naar één van de standaardcategorieën — een proces dat tijdrovend en soms inconsistent kan zijn.
Wat de onderzoekers de computer lieten doen
Het team van een Duits universitair ziekenhuis testte of een algemeen taalmodel, LLaMA 3.3 met 70 miljard parameters, echte CT-radiologierapporten van kankerpatiënten kon lezen en de juiste RECIST-categorie kon toewijzen zonder extra training op lokale data. Ze werkten volledig offline binnen de veilige infrastructuur van het ziekenhuis zodat geen patiëntinformatie de instelling verliet. Voordat het model de rapporten zag, werden de originele responslabels verwijderd, maar alle metingen en referentiewaarden bleven staan zodat het systeem huidige tumorgroottes met eerdere baselines of de kleinste geregistreerde maten kon vergelijken.
Verschillende manieren om de AI te sturen
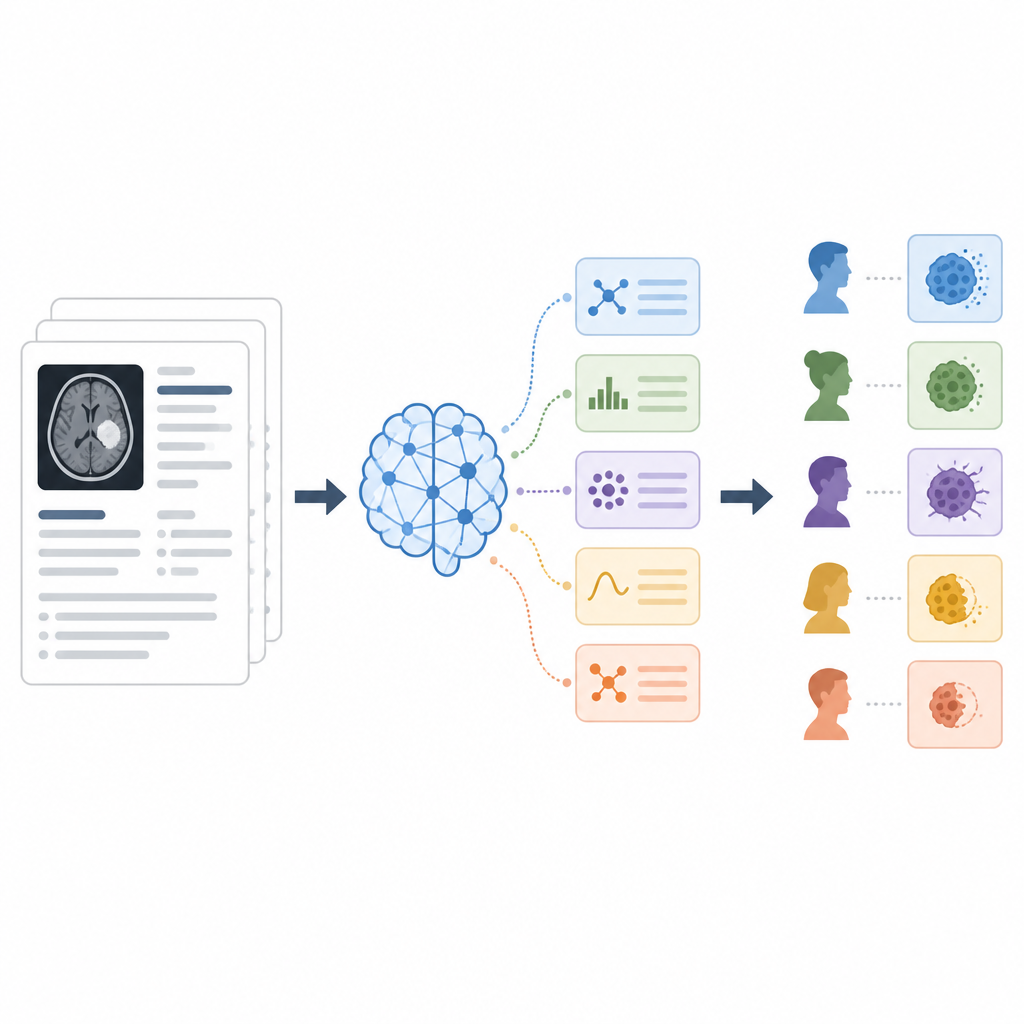
De onderzoekers probeerden drie manieren om het model instructies te geven, bekend als promptingstrategieën. In de zero-shotbenadering ontving het model alleen het rapport en een korte instructie om één van de vijf categorieën uit te geven. In de few-shotbenadering toonden ze het model meerdere voorbeeldfragmenten van rapporten met de juiste categorie, waardoor het leerde door voorbeelden. In de chain-of-thoughtbenadering werd het model gevraagd zijn redenering stap voor stap in gewone taal uit te leggen voordat het een definitieve categorie vermeldde, en meerdere onafhankelijke redeneeruitvoeringen werden gecombineerd om tot een meerderheidsbesluit te komen. Over 142 rapporten maten ze hoe vaak de AI overeenkwam met de menselijke experts met behulp van nauwkeurigheid en gangbare classificatiescores.
Hoe goed het systeem overeenkwam met menselijke lezers
De chain-of-thoughtstrategie presteerde het beste: die classificeerde ongeveer vier van de vijf rapporten correct en behaalde de beste balans tussen het vangen van werkelijke positieven en het vermijden van valse alarmen. Het was bijzonder goed in het onderscheiden van gedeeltelijke respons en stabiele ziekte — twee categorieën die vaak door elkaar worden gehaald — en verbeterde de prestaties bij zeldzamere uitkomsten zoals volledige respons. Zero-shotprompting deed het al verrassend goed, soms beter dan het geven van enkele voorbeelden, wat suggereert dat de formulering van instructies belangrijker kan zijn dan simpelweg meer voorbeelden toevoegen. Few-shotprompting hielp bij sommige moeilijke categorieën, maar kon ook nieuwe fouten introduceren wanneer de kleine set voorbeelden de variatie in echte rapporten niet volledig weerspiegelde.
Wat de fouten en beperkingen onthullen
Door verwarringsmatrices te bestuderen, die laten zien welke categorieën het systeem vaak door elkaar haalde, vonden de auteurs dat de chain-of-thoughtmethode minder systematische fouten produceerde en een patroon liet zien dat leek op zorgvuldige klinische redenering. Het model had echter nog steeds moeite in grensgevallen waarin de tekst niet duidelijk onderscheid maakte tussen een beginscan en een latere scan zonder zichtbare tumorrest. De studie gebruikte rapporten van één instelling die standaardiseerde sjablonen volgde, dus de resultaten kunnen verschillen in ziekenhuizen met lossere schrijfstijlen. Het werk concentreerde zich op één rapport tegelijk en omvatte nog geen langere voorgeschiedenissen over meerdere bezoeken, die voor sommige formele trialregels vereist zijn.
Wat dit kan betekenen voor toekomstige kankerzorg
Voor de leek is de kernboodschap dat een tekst-lezende AI radiologen kan ondersteunen door na te gaan of de conclusies in CT-rapporten overeenkomen met de getallen en regels die behandelbeslissingen sturen. Het systeem helemaal offline laten draaien beschermt de privacy van patiënten en biedt tegelijkertijd een schaalbaar hulpmiddel dat handmatig werk kan verminderen en inconsistenties kan signaleren. De auteurs benadrukken dat zulke modellen clinici moeten ondersteunen en niet vervangen, en dat ze gevalideerd moeten worden in meerdere ziekenhuizen en geïntegreerd met menselijke controle. Bij zorgvuldige ontwikkeling zouden systemen als deze kunnen helpen waarborgen dat het verhaal in een scanrapport betrouwbaarder overeenstemt met de feiten op de beelden en met de standaarden die therapie richting geven.
Bronvermelding: Mergen, M., Busch, F., Sauter, A.P. et al. Automated RECIST tumor response classification through prompt-guided large language models. Sci Rep 16, 16433 (2026). https://doi.org/10.1038/s41598-026-54979-y
Trefwoorden: radiologie-AI, tumorrepons, RECIST, grote taalmodellen, oncologische verslaggeving