Clear Sky Science · en
Automated RECIST tumor response classification through prompt-guided large language models
Why this matters for people with cancer
When someone is treated for cancer, doctors rely on scan reports to decide whether a therapy is working, should be changed, or can be stopped. Reading and summarizing these reports is time consuming and can be prone to small mistakes. This study explores whether a large language model, a type of artificial intelligence that understands text, can safely help doctors sort scan reports into standard response categories while keeping patient data inside the hospital walls.
How doctors usually track tumor changes
In oncology, CT scans are routinely used to check how tumors respond to treatment. Doctors often use a rule set called RECIST, which groups a patient’s situation into categories such as complete response, partial response, stable disease, progressive disease, or baseline before treatment has started. Although many hospitals use semi-structured templates for these reports, the final judgment about response is often written in free text. That means a human expert must interpret measurements, compare them with earlier scans, and translate all of this into one of the standard categories, a process that can be tedious and occasionally inconsistent.
What the researchers asked the computer to do
The team at a German university hospital tested whether a general-purpose language model, LLaMA 3.3 with 70 billion parameters, could read real CT radiology reports from cancer patients and assign the correct RECIST category without any extra training on local data. They worked entirely offline inside the hospital’s secure infrastructure so that no patient information left the institution. Before the model saw the reports, the original response labels were removed, but all measurements and reference values stayed in place so the system could compare current tumor sizes with earlier baselines or smallest recorded sizes.
Different ways of guiding the AI
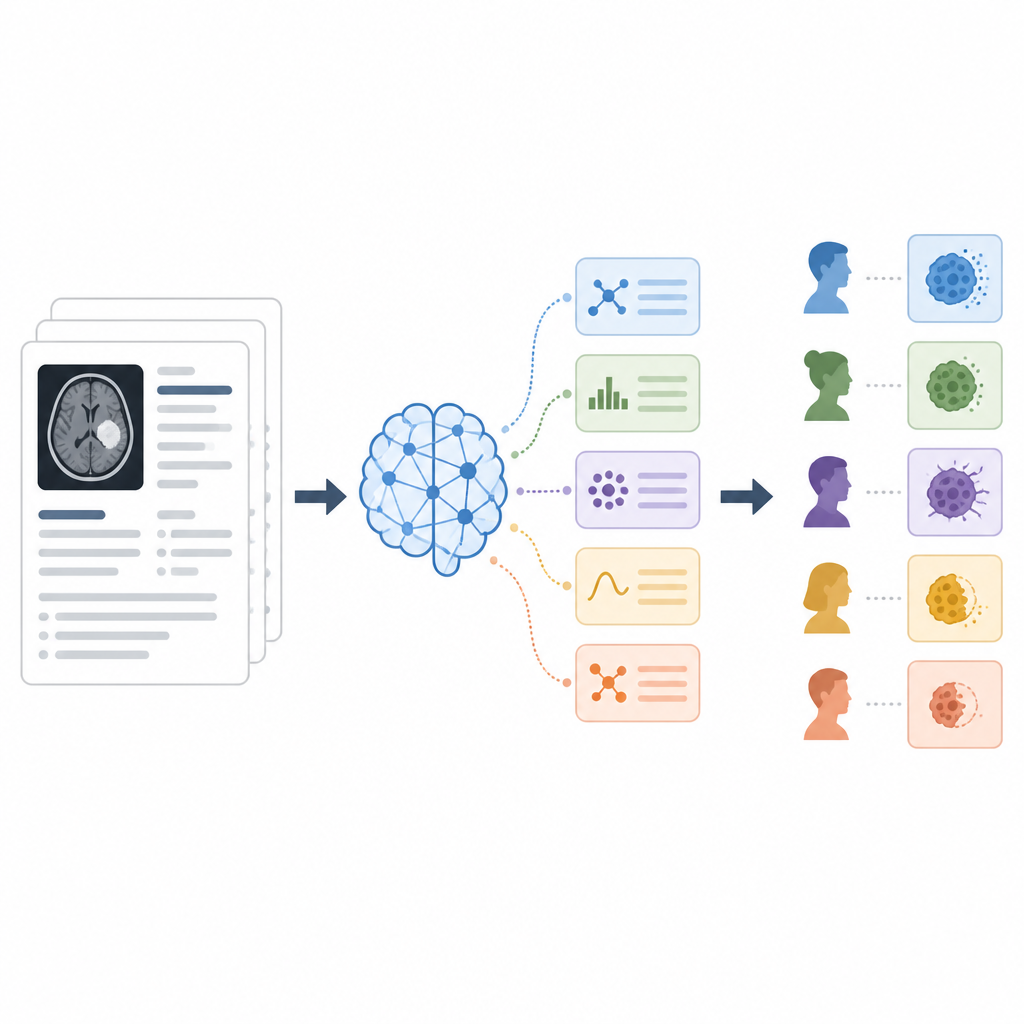
The researchers tried three ways of telling the model what to do, known as prompting strategies. In the zero-shot approach, the model simply received the report and a short instruction to output one of the five categories. In the few-shot approach, they showed the model several example snippets of reports together with the correct category, teaching it by demonstration. In the chain-of-thought approach, the model was asked to explain its reasoning step by step in plain language before stating a final category, and several independent reasoning runs were combined to reach a majority decision. Across 142 reports, they measured how often the AI matched the human experts using accuracy and standard classification scores.
How well the system matched human readers
The chain-of-thought strategy performed best, correctly classifying about four out of five reports overall and achieving the highest balance between catching true positives and avoiding false alarms. It was especially good at separating partial response and stable disease, two categories that are often confused, and improved performance on rarer outcomes such as complete response. Zero-shot prompting already did surprisingly well, sometimes better than giving a few examples, which suggests that the way instructions are phrased can matter more than simply adding more training examples. Few-shot prompting helped some difficult categories but could also introduce new mistakes when the small set of examples did not fully reflect the variety of real reports.
What the errors and limits reveal
By studying confusion matrices, which show which categories the system tended to mix up, the authors found that the chain-of-thought method produced fewer systematic errors and a pattern that resembled careful clinical reasoning. However, the model still struggled in borderline situations where the text did not clearly distinguish between a starting scan and a later scan with no remaining visible tumor. The study used reports from a single institution that followed standardized templates, so results might differ in hospitals with looser writing styles. The work focused on one report at a time and did not yet incorporate longer histories across multiple visits, which are required for some formal trial rules.
What this could mean for future cancer care
For a layperson, the key message is that a text-reading AI can assist radiologists by double-checking whether the conclusions written in CT reports match the numbers and rules that guide cancer treatment decisions. Running the system completely offline protects patient privacy while still offering a scalable tool that could reduce manual workload and highlight inconsistencies. The authors stress that such models should support, not replace, clinicians, and should be validated across more hospitals and integrated with human review. If developed carefully, systems like this could help ensure that the story told in a scan report lines up more reliably with the facts on the images and the standards used to guide therapy.
Citation: Mergen, M., Busch, F., Sauter, A.P. et al. Automated RECIST tumor response classification through prompt-guided large language models. Sci Rep 16, 16433 (2026). https://doi.org/10.1038/s41598-026-54979-y
Keywords: radiology AI, tumor response, RECIST, large language models, oncology reporting