Clear Sky Science · fr
Classification automatisée de la réponse tumorale RECIST via des grands modèles de langage guidés par prompts
Pourquoi cela compte pour les personnes atteintes de cancer
Lorsqu’une personne reçoit un traitement contre le cancer, les médecins s’appuient sur les rapports d’imagerie pour décider si une thérapie fonctionne, doit être modifiée ou peut être arrêtée. Lire et résumer ces rapports prend du temps et peut être sujet à de petites erreurs. Cette étude évalue si un grand modèle de langage, un type d’intelligence artificielle qui comprend le texte, peut aider en toute sécurité les médecins à classer les rapports de scanner selon des catégories de réponse standard tout en maintenant les données des patients à l’intérieur de l’hôpital.
Comment les médecins suivent habituellement les changements tumoraux
En oncologie, les scanners CT sont couramment utilisés pour vérifier la réponse des tumeurs aux traitements. Les cliniciens utilisent souvent un ensemble de règles appelé RECIST, qui classe la situation d’un patient en catégories telles que réponse complète, réponse partielle, maladie stable, progression de la maladie, ou état de référence avant le début du traitement. Bien que de nombreux hôpitaux utilisent des modèles semi-structurés pour ces rapports, le jugement final sur la réponse est souvent rédigé en texte libre. Cela signifie qu’un expert humain doit interpréter les mesures, les comparer aux scanners antérieurs et traduire le tout en l’une des catégories standard — un processus qui peut être fastidieux et parfois incohérent.
Ce qu’on a demandé à l’ordinateur
L’équipe d’un hôpital universitaire allemand a testé si un modèle de langage à usage général, LLaMA 3.3 de 70 milliards de paramètres, pouvait lire de vrais rapports de radiologie CT de patients cancéreux et attribuer la bonne catégorie RECIST sans entraînement supplémentaire sur des données locales. Ils ont travaillé entièrement hors ligne, au sein de l’infrastructure sécurisée de l’hôpital, de sorte qu’aucune information patient n’a quitté l’établissement. Avant que le modèle ne voie les rapports, les étiquettes de réponse d’origine ont été retirées, mais toutes les mesures et valeurs de référence sont restées en place afin que le système puisse comparer les tailles tumorales actuelles aux baselines antérieurs ou aux plus petites tailles enregistrées.
Différentes façons de guider l’IA
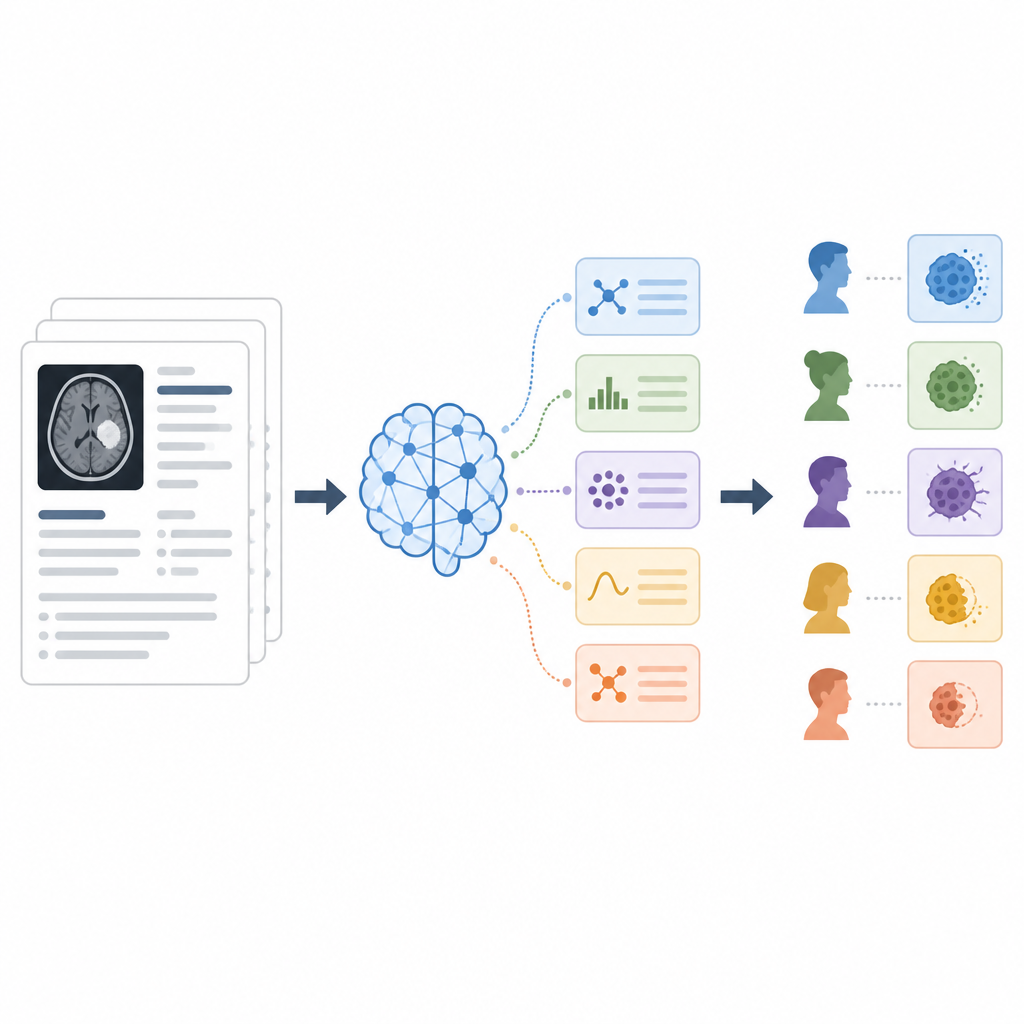
Les chercheurs ont testé trois manières d’indiquer au modèle ce qu’il devait faire, appelées stratégies de prompting. Dans l’approche zero-shot, le modèle recevait simplement le rapport et une courte instruction pour renvoyer l’une des cinq catégories. Dans l’approche few-shot, ils ont montré au modèle plusieurs extraits d’exemples de rapports accompagnés de la catégorie correcte, l’enseignant par démonstration. Dans l’approche chain-of-thought, le modèle était invité à expliquer son raisonnement étape par étape en langage clair avant d’indiquer une catégorie finale, et plusieurs exécutions de raisonnement indépendantes étaient combinées pour atteindre une décision majoritaire. Sur 142 rapports, ils ont mesuré la fréquence à laquelle l’IA correspondait aux experts humains en utilisant l’exactitude et des scores standard de classification.
À quel point le système s’est aligné sur les lecteurs humains
La stratégie chain-of-thought a donné les meilleurs résultats, classifiant correctement environ quatre rapports sur cinq au global et obtenant le meilleur compromis entre détection des vrais positifs et limitation des faux positifs. Elle a été particulièrement efficace pour distinguer réponse partielle et maladie stable, deux catégories souvent confondues, et a amélioré les performances sur des issues plus rares comme la réponse complète. Le prompting zero-shot a déjà étonnamment bien fonctionné, parfois mieux que le few-shot, ce qui suggère que la formulation des instructions peut compter davantage que l’ajout d’exemples. Le few-shot a aidé pour certaines catégories difficiles mais a aussi pu introduire de nouvelles erreurs lorsque l’ensemble limité d’exemples ne reflétait pas toute la variété des rapports réels.
Ce que révèlent les erreurs et les limites
En étudiant les matrices de confusion, qui montrent quelles catégories le système avait tendance à confondre, les auteurs ont constaté que la méthode chain-of-thought produisait moins d’erreurs systématiques et un schéma qui ressemblait à un raisonnement clinique prudent. Cependant, le modèle a encore eu des difficultés dans des situations limites où le texte ne distinguait pas clairement entre un scanner de départ et un scanner ultérieur sans tumeur visible résiduelle. L’étude utilisait des rapports d’une seule institution qui suivaient des modèles standardisés, donc les résultats pourraient différer dans des hôpitaux ayant des styles d’écriture plus libres. Le travail s’est concentré sur un rapport à la fois et n’a pas encore intégré des historiques plus longs couvrant plusieurs visites, requis pour certaines règles formelles d’essai clinique.
Ce que cela pourrait signifier pour les soins du cancer à l’avenir
Pour un non-spécialiste, le message principal est qu’une IA lisant du texte peut aider les radiologues en vérifiant si les conclusions rédigées dans les rapports CT correspondent aux chiffres et aux règles qui guident les décisions thérapeutiques en oncologie. Exécuter le système complètement hors ligne protège la confidentialité des patients tout en offrant un outil évolutif susceptible de réduire la charge de travail manuelle et de mettre en évidence des incohérences. Les auteurs insistent sur le fait que de tels modèles doivent assister, et non remplacer, les cliniciens, et qu’ils doivent être validés dans davantage d’hôpitaux et intégrés à une relecture humaine. Si elles sont développées avec soin, des solutions de ce type pourraient aider à s’assurer que le récit contenu dans un rapport de scanner correspond plus fidèlement aux faits visibles sur les images et aux normes qui guident la thérapie.
Citation: Mergen, M., Busch, F., Sauter, A.P. et al. Automated RECIST tumor response classification through prompt-guided large language models. Sci Rep 16, 16433 (2026). https://doi.org/10.1038/s41598-026-54979-y
Mots-clés: IA en radiologie, réponse tumorale, RECIST, grands modèles de langage, reporting en oncologie