Clear Sky Science · it
Classificazione automatica della risposta tumorale RECIST tramite modelli di linguaggio di grandi dimensioni guidati da prompt
Perché questo conta per le persone con il cancro
Quando una persona viene trattata per il cancro, i medici si affidano ai referti di imaging per decidere se una terapia funziona, deve essere cambiata o può essere interrotta. Leggere e riepilogare questi referti richiede tempo ed è soggetto a piccoli errori. Questo studio esplora se un modello di linguaggio di grandi dimensioni, un tipo di intelligenza artificiale che comprende il testo, possa aiutare in modo sicuro i medici a ordinare i referti in categorie di risposta standard mantenendo i dati dei pazienti all’interno dell’ospedale.
Come i medici monitorano di solito le variazioni tumorali
In oncologia, le TC sono usate di routine per verificare come i tumori rispondono al trattamento. I medici spesso impiegano un insieme di regole chiamato RECIST, che classifica la situazione del paziente in categorie come risposta completa, risposta parziale, malattia stabile, progressione di malattia, o baseline prima dell’inizio del trattamento. Sebbene molti ospedali usino template semi-strutturati per questi referti, il giudizio finale sulla risposta è spesso espresso in testo libero. Ciò significa che un esperto umano deve interpretare le misure, confrontarle con esami precedenti e tradurre il tutto in una delle categorie standard, un processo che può essere tedioso e talvolta incoerente.
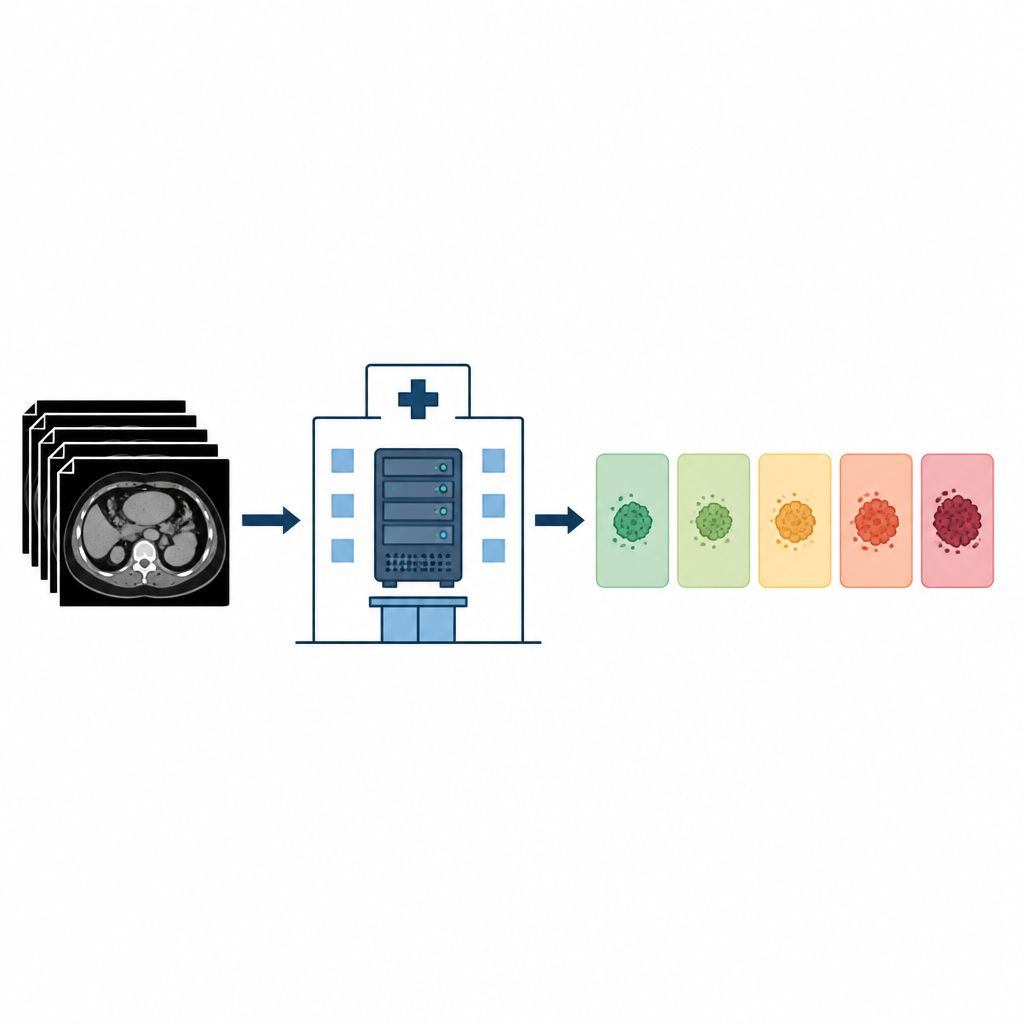
Cosa hanno chiesto i ricercatori al computer
Il team di un ospedale universitario tedesco ha testato se un modello di linguaggio di uso generale, LLaMA 3.3 con 70 miliardi di parametri, potesse leggere referti TC reali di pazienti oncologici e assegnare la corretta categoria RECIST senza alcun addestramento aggiuntivo sui dati locali. Hanno lavorato interamente offline nella infrastruttura sicura dell’ospedale in modo che nessuna informazione sui pazienti uscisse dall’istituzione. Prima che il modello vedesse i referti, le etichette originali di risposta sono state rimosse, ma tutte le misure e i valori di riferimento sono rimasti in modo che il sistema potesse confrontare le dimensioni tumorali correnti con baseline precedenti o con le dimensioni minime registrate.
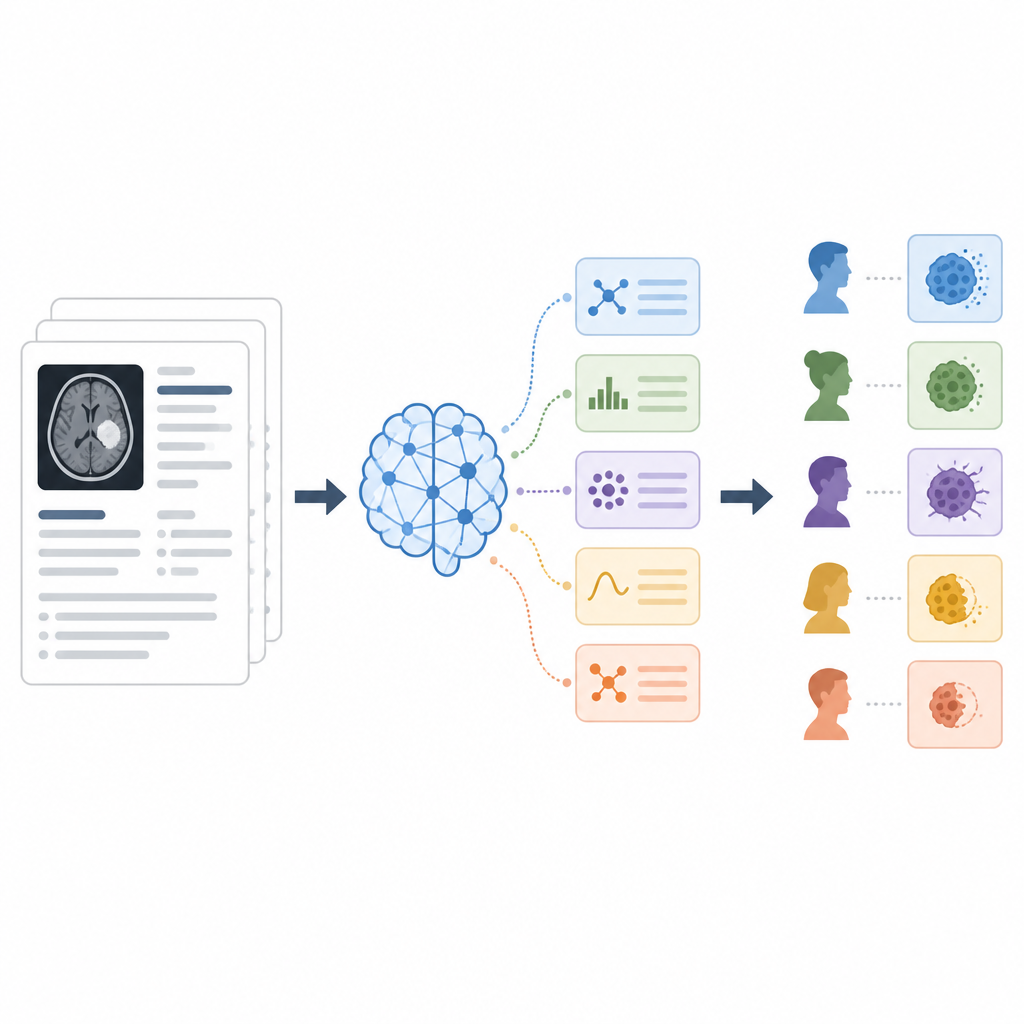
Diverse modalità per guidare l’IA
I ricercatori hanno provato tre modalità per dire al modello cosa fare, note come strategie di prompting. Nell’approccio zero-shot, il modello riceveva semplicemente il referto e una breve istruzione per restituire una delle cinque categorie. Nel few-shot, hanno mostrato al modello diversi esempi di estratti di referti insieme alla categoria corretta, insegnandogli per dimostrazione. Nell’approccio chain-of-thought, al modello è stato chiesto di spiegare il proprio ragionamento passo dopo passo in linguaggio semplice prima di indicare la categoria finale, e più esecuzioni di ragionamento indipendenti sono state combinate per raggiungere una decisione di maggioranza. Su 142 referti hanno misurato quanto spesso l’IA coincideva con gli esperti umani usando accuratezza e punteggi standard di classificazione.
Quanto il sistema ha corrisposto ai lettori umani
La strategia chain-of-thought ha ottenuto le migliori prestazioni, classificando correttamente circa quattro referti su cinque nel complesso e raggiungendo il miglior bilanciamento tra individuare i veri positivi ed evitare falsi allarmi. È stata particolarmente efficace nel separare risposta parziale e malattia stabile, due categorie spesso confuse, e ha migliorato le prestazioni su esiti più rari come la risposta completa. Il prompting zero-shot ha già fornito risultati sorprendentemente buoni, a volte migliori dell’inserire qualche esempio, il che suggerisce che il modo in cui sono formulate le istruzioni può contare più dell’aggiunta di esempi. Il few-shot ha aiutato alcune categorie difficili ma poteva anche introdurre nuovi errori quando il piccolo insieme di esempi non rifletteva appieno la varietà dei referti reali.
Cosa rivelano gli errori e i limiti
Analizzando le matrici di confusione, che mostrano quali categorie il sistema tendeva a confondere, gli autori hanno riscontrato che il metodo chain-of-thought produceva meno errori sistematici e un pattern simile a un ragionamento clinico attento. Tuttavia, il modello aveva ancora difficoltà in situazioni al limite in cui il testo non distingueva chiaramente tra un esame di partenza e un esame successivo senza tumore residuo visibile. Lo studio ha utilizzato referti di una singola istituzione che seguivano template standardizzati, quindi i risultati potrebbero differire in ospedali con stili di scrittura più liberi. Il lavoro si è concentrato su un referto alla volta e non ha ancora integrato storie cliniche più lunghe attraverso visite multiple, necessarie per alcune regole formali dei trial.
Cosa potrebbe significare per la cura oncologica futura
Per un lettore non specialistico, il messaggio chiave è che un’IA che legge testi può assistere i radiologi verificando se le conclusioni scritte nei referti TC sono coerenti con i numeri e le regole che guidano le decisioni terapeutiche oncologiche. Eseguire il sistema completamente offline protegge la privacy dei pazienti offrendo comunque uno strumento scalabile che potrebbe ridurre il carico di lavoro manuale e segnalare incoerenze. Gli autori sottolineano che tali modelli dovrebbero supportare, non sostituire, i clinici e dovrebbero essere validati in più ospedali e integrati con la revisione umana. Se sviluppati con cura, sistemi di questo tipo potrebbero contribuire a garantire che il racconto contenuto in un referto corrisponda in modo più affidabile ai fatti visibili nelle immagini e agli standard usati per orientare le terapie.
Citazione: Mergen, M., Busch, F., Sauter, A.P. et al. Automated RECIST tumor response classification through prompt-guided large language models. Sci Rep 16, 16433 (2026). https://doi.org/10.1038/s41598-026-54979-y
Parole chiave: IA in radiologia, risposta tumorale, RECIST, modelli di linguaggio di grandi dimensioni, refertazione oncologica