Clear Sky Science · de
Automatisierte RECIST-Tumorantwort-Klassifikation mittels promptgesteuerter großer Sprachmodelle
Warum das für Krebspatienten wichtig ist
Wenn jemand wegen Krebs behandelt wird, verlassen sich Ärztinnen und Ärzte auf Befundberichte, um zu entscheiden, ob eine Therapie wirkt, geändert werden sollte oder abgesetzt werden kann. Das Lesen und Zusammenfassen dieser Berichte ist zeitaufwendig und kann anfällig für kleine Fehler sein. Diese Studie prüft, ob ein großes Sprachmodell, eine Form künstlicher Intelligenz, die Text versteht, Ärztinnen und Ärzte sicher dabei unterstützen kann, Befunde in standardisierte Antwortkategorien einzuordnen, während die Patientendaten innerhalb der Krankenhausinfrastruktur verbleiben.
Wie Ärztinnen und Ärzte Tumorveränderungen üblicherweise verfolgen
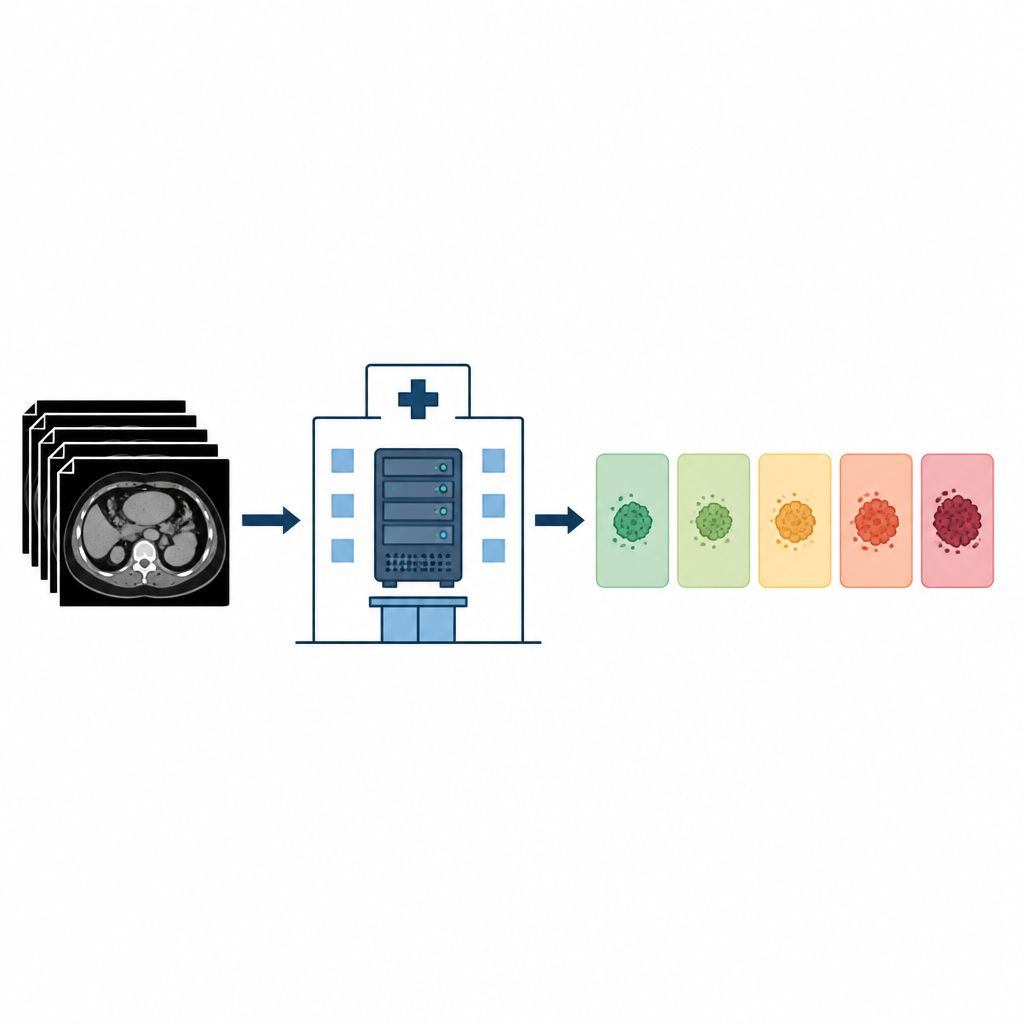
In der Onkologie werden CT-Scans routinemäßig verwendet, um zu überprüfen, wie Tumoren auf eine Behandlung reagieren. Ärztliche Teams nutzen oft ein Regelwerk namens RECIST, das die Situation einer Patientin oder eines Patienten in Kategorien wie Komplettansprechen, partielles Ansprechen, stabile Erkrankung, progrediente Erkrankung oder Ausgangsbefund vor Therapieeinleitung einteilt. Obwohl viele Kliniken halbstrukturierte Vorlagen für diese Berichte verwenden, steht das abschließende Urteil über die Antwort häufig im Freitext. Das bedeutet, dass ein menschlicher Experte Messungen interpretieren, sie mit früheren Scans vergleichen und alles in eine der Standardkategorien übersetzen muss — ein Prozess, der mühsam und gelegentlich inkonsistent sein kann.
Was die Forschenden dem Computer aufgaben
Das Team an einem deutschen Universitätskrankenhaus prüfte, ob ein allgemeines Sprachmodell, LLaMA 3.3 mit 70 Milliarden Parametern, reale CT-Radiologieberichte von Krebspatienten lesen und ohne zusätzliches Training an lokale Daten die korrekte RECIST-Kategorie zuweisen kann. Sie arbeiteten vollständig offline innerhalb der sicheren Infrastruktur des Krankenhauses, sodass keine Patientendaten das Institut verließen. Bevor das Modell die Berichte sah, wurden ursprüngliche Antwortlabels entfernt, aber alle Messwerte und Bezugsgrößen blieben erhalten, damit das System aktuelle Tumorgrößen mit früheren Ausgangswerten oder mit den kleinsten dokumentierten Größen vergleichen konnte.
Verschiedene Wege, die KI zu steuern
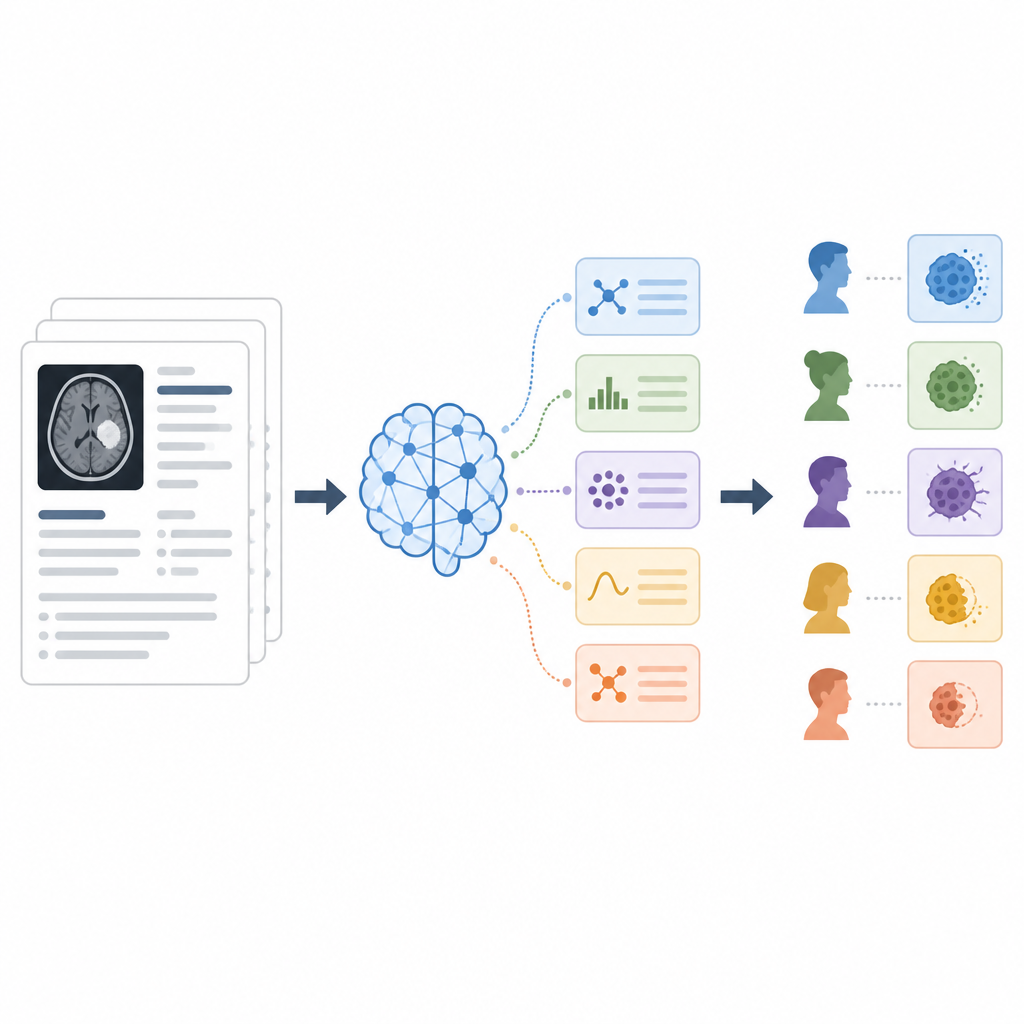
Die Forschenden probierten drei Arten, dem Modell Anweisungen zu geben, sogenannte Prompting-Strategien. Beim Zero-Shot-Ansatz erhielt das Modell lediglich den Bericht und eine kurze Aufforderung, eine der fünf Kategorien auszugeben. Beim Few-Shot-Ansatz zeigten sie dem Modell mehrere beispielhafte Berichtsausschnitte zusammen mit der korrekten Kategorie und lehrten es so durch Demonstration. Beim Chain-of-Thought-Ansatz wurde das Modell gebeten, seine Schlussfolgerungen schrittweise in klarer Sprache zu erklären, bevor es eine endgültige Kategorie nannte; mehrere unabhängige Denkdurchläufe wurden zu einer Mehrheitsentscheidung kombiniert. Über 142 Berichte hinweg maßen sie, wie oft die KI mit den menschlichen Expertinnen und Experten übereinstimmte, anhand von Genauigkeit und gängigen Klassifikationskennzahlen.
Wie gut das System mit menschlichen Leserinnen und Lesern übereinstimmte
Die Chain-of-Thought-Strategie schnitt am besten ab und klassifizierte insgesamt ungefähr vier von fünf Berichten korrekt. Sie erreichte die beste Balance zwischen dem Erfassen wahrer Positiver und dem Vermeiden falscher Alarme. Besonders gut trennte sie partielles Ansprechen und stabile Erkrankung — zwei Kategorien, die häufig verwechselt werden — und verbesserte die Leistung bei selteneren Ergebnissen wie dem Komplettansprechen. Zero-Shot-Prompting erzielte bereits überraschend gute Ergebnisse und war mitunter wirksamer als das Hinzufügen einiger Beispiele; das deutet darauf hin, dass die Formulierung der Anweisung wichtiger sein kann als die bloße Anzahl an Beispielen. Few-Shot-Prompting half bei einigen schwierigen Kategorien, konnte aber auch neue Fehler einführen, wenn der kleine Beispielsatz die Vielfalt realer Berichte nicht vollständig abbildete.
Was die Fehler und Grenzen offenbaren
Durch die Analyse von Konfusionsmatrizen, die zeigen, welche Kategorien das System zu verwechseln pflegte, stellten die Autorinnen und Autoren fest, dass die Chain-of-Thought-Methode weniger systematische Fehler erzeugte und ein Muster zeigte, das klinischem, sorgfältigem Denken ähnelte. Das Modell hatte jedoch weiterhin Schwierigkeiten in Randfällen, etwa wenn der Text nicht klar zwischen einem Ausgangsscan und einem späteren Scan ohne noch sichtbaren Tumor unterschied. Die Studie nutzte Berichte aus einer einzigen Institution, die standardisierte Vorlagen anwandte, sodass die Ergebnisse in Kliniken mit freierem Schreibstil abweichen könnten. Die Arbeit fokussierte sich auf jeweils einen Bericht und berücksichtigte noch nicht längere Krankengeschichten über mehrere Besuche hinweg, die für manche formalen Studiendefinitionen erforderlich sind.
Was das für die künftige Krebsversorgung bedeuten könnte
Für Laien ist die zentrale Botschaft, dass eine textlesende KI Radiologinnen und Radiologen unterstützen kann, indem sie prüft, ob die in CT-Berichten gezogenen Schlussfolgerungen mit den Zahlen und Regeln übereinstimmen, die Therapieentscheidungen leiten. Der vollständige Offline-Betrieb schützt die Privatsphäre der Patientinnen und Patienten und bietet gleichzeitig ein skalierbares Werkzeug, das manuelle Arbeit reduzieren und Inkonsistenzen hervorheben könnte. Die Autorinnen und Autoren betonen, dass solche Modelle die Klinikerinnen und Kliniker unterstützen, nicht ersetzen sollten, und dass sie über mehrere Krankenhäuser hinweg validiert und in menschliche Prüfprozesse integriert werden müssen. Bei sorgfältiger Entwicklung könnten Systeme wie dieses dazu beitragen, dass die im Bericht erzählte Geschichte verlässlicher mit den Bildbefunden und den zur Therapieplanung genutzten Standards übereinstimmt.
Zitation: Mergen, M., Busch, F., Sauter, A.P. et al. Automated RECIST tumor response classification through prompt-guided large language models. Sci Rep 16, 16433 (2026). https://doi.org/10.1038/s41598-026-54979-y
Schlüsselwörter: Radiologie-KI, Tumorantwort, RECIST, große Sprachmodelle, onkologische Berichterstattung