Clear Sky Science · pt
Classificação automatizada da resposta tumoral por RECIST usando grandes modelos de linguagem guiados por prompts
Por que isso importa para pessoas com câncer
Quando alguém recebe tratamento para câncer, os médicos dependem dos laudos de imagem para decidir se uma terapia está funcionando, deve ser alterada ou pode ser interrompida. Ler e resumir esses laudos consome tempo e pode estar sujeito a pequenos erros. Este estudo investiga se um grande modelo de linguagem, um tipo de inteligência artificial que compreende texto, pode auxiliar com segurança os médicos a classificar laudos de imagem em categorias padrão de resposta, mantendo os dados dos pacientes dentro das paredes do hospital.
Como os médicos costumam acompanhar mudanças tumorais
Em oncologia, tomografias computadorizadas (TC) são rotineiramente usadas para verificar como os tumores respondem ao tratamento. Os médicos frequentemente utilizam um conjunto de regras chamado RECIST, que agrupa a situação do paciente em categorias como resposta completa, resposta parcial, doença estável, doença progressiva ou linha de base antes do início do tratamento. Embora muitos hospitais usem templates semiestruturados para esses laudos, o julgamento final sobre a resposta costuma vir em texto livre. Isso significa que um especialista humano precisa interpretar medidas, compará‑las com exames anteriores e traduzir tudo isso para uma das categorias padrão, um processo que pode ser cansativo e por vezes inconsistente.
O que os pesquisadores pediram ao computador
A equipe de um hospital universitário alemão testou se um modelo de linguagem de uso geral, LLaMA 3.3 com 70 bilhões de parâmetros, conseguia ler laudos reais de TC de pacientes com câncer e atribuir a categoria RECIST correta sem treinamento adicional com dados locais. Eles trabalharam inteiramente offline dentro da infraestrutura segura do hospital, de modo que nenhuma informação do paciente saiu da instituição. Antes do modelo acessar os laudos, os rótulos de resposta originais foram removidos, mas todas as medições e valores de referência permaneceram para que o sistema pudesse comparar tamanhos atuais de tumor com linhas de base anteriores ou com os menores tamanhos registrados.
Diferentes formas de orientar a IA
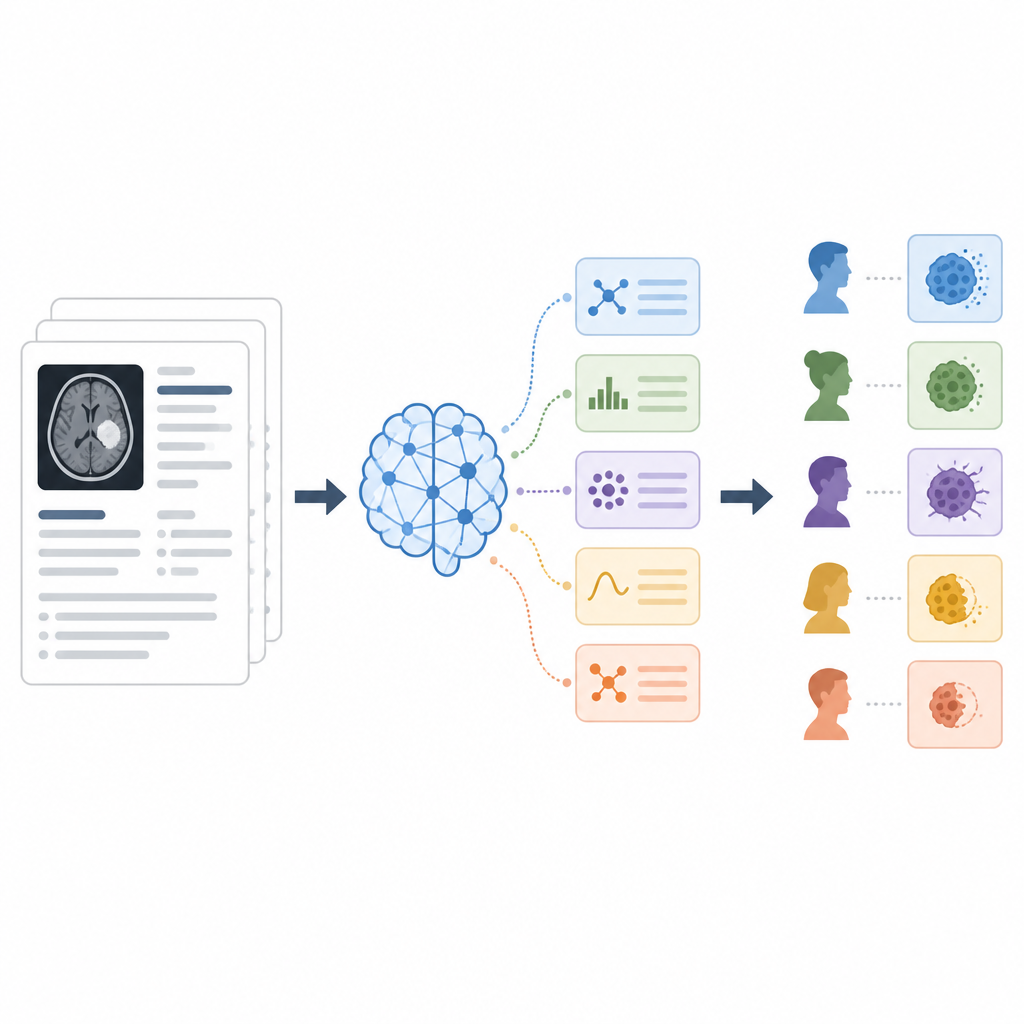
Os pesquisadores testaram três formas de instruir o modelo, conhecidas como estratégias de prompting. Na abordagem zero‑shot, o modelo recebia apenas o laudo e uma instrução curta para emitir uma das cinco categorias. Na few‑shot, mostraram ao modelo vários trechos de laudos junto com a categoria correta, ensinando por demonstração. Na chain‑of‑thought, pediu‑se ao modelo que explicasse seu raciocínio passo a passo em linguagem simples antes de declarar a categoria final, e várias execuções independentes do raciocínio foram combinadas para atingir uma decisão por maioria. Ao longo de 142 laudos, mediram com que frequência a IA concordou com os especialistas humanos usando acurácia e métricas padrão de classificação.
Quão bem o sistema concordou com leitores humanos
A estratégia chain‑of‑thought teve o melhor desempenho, classificando corretamente cerca de quatro em cada cinco laudos no geral e alcançando o melhor equilíbrio entre detectar verdadeiros positivos e evitar alarmes falsos. Ela foi particularmente eficaz em distinguir resposta parcial de doença estável, duas categorias frequentemente confundidas, e melhorou o desempenho em desfechos mais raros como resposta completa. O prompting zero‑shot já teve desempenho surpreendentemente bom, às vezes melhor do que fornecer alguns exemplos, o que sugere que a formulação das instruções pode importar mais do que simplesmente acrescentar exemplos de treinamento. O few‑shot ajudou em algumas categorias difíceis, mas também pode introduzir novos erros quando o pequeno conjunto de exemplos não refletem totalmente a variedade dos laudos reais.
O que os erros e limites revelam
Ao estudar matrizes de confusão, que mostram quais categorias o sistema tendia a confundir, os autores verificaram que o método chain‑of‑thought produziu menos erros sistemáticos e um padrão que lembrava um raciocínio clínico cuidadoso. Contudo, o modelo ainda teve dificuldades em situações de fronteira onde o texto não diferenciava claramente entre um exame inicial e um exame posterior sem tumor visível remanescente. O estudo usou laudos de uma única instituição que seguia templates padronizados, de modo que os resultados podem variar em hospitais com estilos de escrita mais flexíveis. O trabalho enfocou um laudo por vez e ainda não incorporou históricos mais longos ao longo de várias consultas, o que é necessário para algumas regras formais de ensaios clínicos.
O que isso pode significar para o cuidado do câncer no futuro
Para o leitor leigo, a mensagem principal é que uma IA que lê texto pode ajudar radiologistas conferindo se as conclusões escritas nos laudos de TC condizem com os números e regras que orientam decisões de tratamento oncológico. Rodar o sistema totalmente offline protege a privacidade dos pacientes e ainda oferece uma ferramenta escalável que pode reduzir a carga de trabalho manual e destacar inconsistências. Os autores enfatizam que tais modelos devem apoiar, não substituir, os clínicos, e devem ser validados em mais hospitais e integrados à revisão humana. Se desenvolvidos com cuidado, sistemas como este podem contribuir para que a narrativa contida num laudo de exame esteja mais alinhada com os fatos nas imagens e com os padrões usados para orientar a terapia.
Citação: Mergen, M., Busch, F., Sauter, A.P. et al. Automated RECIST tumor response classification through prompt-guided large language models. Sci Rep 16, 16433 (2026). https://doi.org/10.1038/s41598-026-54979-y
Palavras-chave: IA em radiologia, resposta tumoral, RECIST, grandes modelos de linguagem, relatórios oncológicos