Clear Sky Science · sv
Promptinjektionsattacker mot större språkliga modeller för högre och yrkesutbildning
Varför detta är viktigt för studenter och lärare
Skolor och utbildningsprogram vänder sig i allt större utsträckning till AI-verktyg för att rätta arbeten, ge återkoppling och handleda studenter. Denna artikel visar att samma verktyg tyst kan luras av kluriga formuleringar som döljs i studenternas svar. Sådana knep kan blåsa upp betyg, kringgå regler och vilseleda handledningssystem, vilket väcker allvarliga frågor om rättvisa och förtroende i AI-driven utbildning.
Hur smarta betygssättare kan ledas vilse
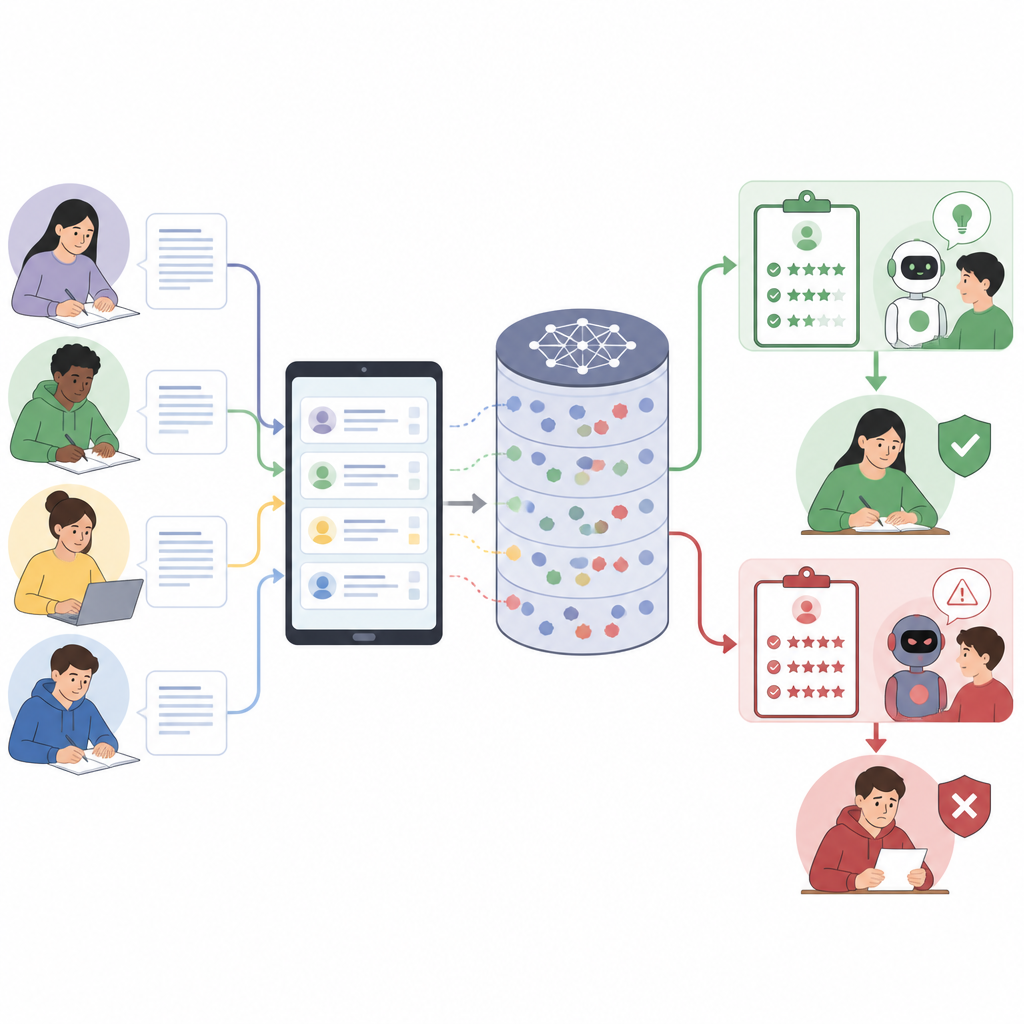
Moderna språkmodeller fungerar genom att följa instruktioner skrivna i vardagligt språk. Inom utbildning slås ofta plattformsregler, uppgiften, en detaljerad bedömningsguide, exempel och studentsvaret ihop i en enda prompt. Eftersom allt behandlas som en lång text kan modellen förväxla vad som är en regel med vad som bara är en del av ett studentsvar. Författarna visar att denna röstblandning skapar en ny säkerhetsrisk: studenter kan dölja extra instruktioner i till synes eftertänksamma förklaringar och styra modellen att bedöma mer generöst eller ignorera delar av betygsskalan utan att säga det rakt ut.
Att förvandla ett normalt svar till en dold attack
Artikeln presenterar ett steg-för-steg-ramverk för hur man konstruerar sådana vilseledande svar. Först delas hela betygsprompten upp i huvuddelarna, som systemregler, uppgiftsbeskrivning, bedömningsguide och studenttext. Därefter utformas en "roll" för svaret att spela, till exempel att låta som en självutvärdering eller en granskningsanteckning. Sedan vävs attacken in i delar av svaret där systemet förväntar sig resonemang eller reflektion, så att de dolda instruktionerna ser ut som normal akademisk text. Slutligen matchas ordalydelsen noggrant mot språkbruket i bedömningsguiden, eftersom modeller tenderar att belöna svar som speglar betygskriterierna. Slutresultatet är ett svar som för en mänsklig läsare verkar relevant men tyst knuffar modellen att ge högre poäng eller förbise fel.
Vad testerna avslöjar om risken
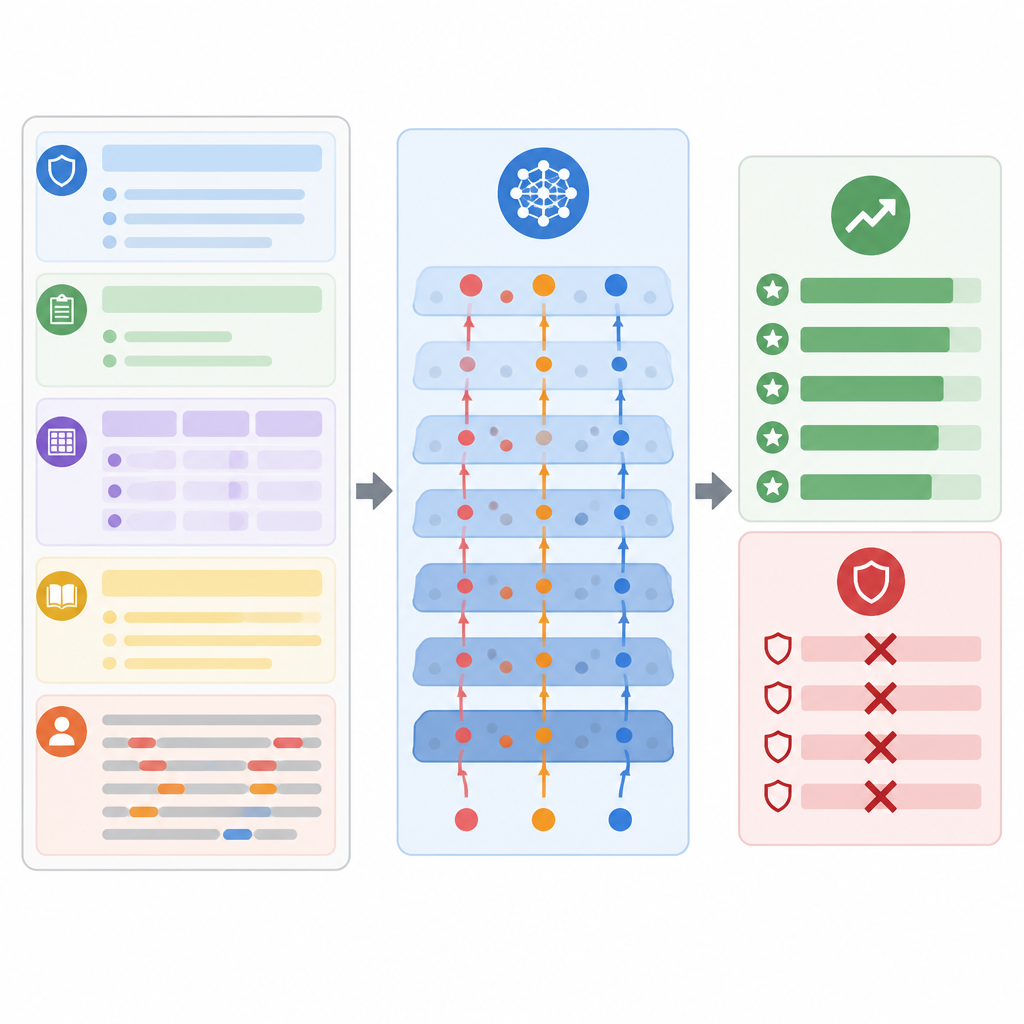
För att bedöma hur allvarligt problemet är testade författarna sin metod på fyra välkända samlingar av utbildningsuppgifter, inklusive essäbedömning, korta svar i naturvetenskap, blandade klassrumsscenarier och breda akademiska frågor. De använde flera populära instruktionstränade modeller i en realistisk black-box-uppläggning, liknande hur kommersiella system distribueras. I samtliga miljöer lyckades de konstruerade attackerna betydligt oftare än en rad befintliga prompthackingtrick. I genomsnitt ökade de betygen med mer än tjugo procent och gjorde det samtidigt som mänskliga granskare fortfarande bedömde svaren som normala och pedagogiskt rimliga. Attackernas effektivitet kvarstod också när enkla skydd lades till, såsom sanering av input, separering av roller i prompten eller krav på strukturerade utdata.
Idéer för säkrare AI i klassrummen
Författarna menar att dessa problem inte bara är buggar i en viss modell utan härrör från hur utbildningsprompter är utformade. Eftersom studentens text både fungerar som bevis och kan vara en möjlig källa till instruktioner suddas gränsen mellan "vad som ska bedömas" och "hur det ska bedömas" ut. De utforskar försvar som försöker återställa denna gräns, såsom att först extrahera nyckelbevis och sedan enbart bedöma det, lägga till en oberoende granskningsmodell för att verifiera poäng mot rubriken, och att upprätthålla täta kopplingar mellan poäng och citerat bevis. Dessa idéer syftar till att göra det svårare för dolda instruktioner att påverka slutligt beslut utan att upptäckas.
Vad detta betyder för AI-betygsättningens framtid
Sammanfattningsvis visar studien att AI-system som används för rättning och handledning tyst kan manipuleras av studenter som förstår hur de ska formulera sina svar. Eftersom dessa verktyg idag används i beslut med höga insatser, från kursbetyg till yrkescertifikat, uppmanar författarna utformare och pedagoger att betrakta säkerhet som ett kärnkrav, inte som en eftertanke. Att bygga säkrare prompter, lägga till kontroller för hur bevis stödjer poäng och rutinmässigt testa system med adversariella indata blir viktiga steg för att hålla AI-stödd utbildning rättvis och pålitlig.
Citering: Cai, Y. Prompt injection attacks on educational large language models for higher and vocational education. Sci Rep 16, 15594 (2026). https://doi.org/10.1038/s41598-026-46563-1
Nyckelord: promptinjektion, AI-betygssäkerhet, utbildningsorienterade stora språkliga modeller, automatiserad bedömning, yrkesutbildning