Clear Sky Science · he
התקפות הזרקת פרומפטים על מודלים שפתיים גדולים חינוכיים להשכלה גבוהה ולמקצועות
מדוע זה חשוב לתלמידים ולמורות
בתי ספר ותוכניות הכשרה פונים יותר ויותר לכלי בינה מלאכותית להערכת עבודות, מתן משוב והדרכת תלמידים. מאמר זה מראה שכלים אלה יכולים להיות מושטים בשקט בעזרת ניסוח מתוחכם המוסתר בתוך תשובות תלמידים. טריקים כאלה יכולים לנפח ציונים, לעקם כללים ולהטעות מערכות חונכות, מה שעורר שאלות כבדות משקל לגבי הוגנות ואמינות בחינוך המופעל באמצעות בינה מלאכותית.
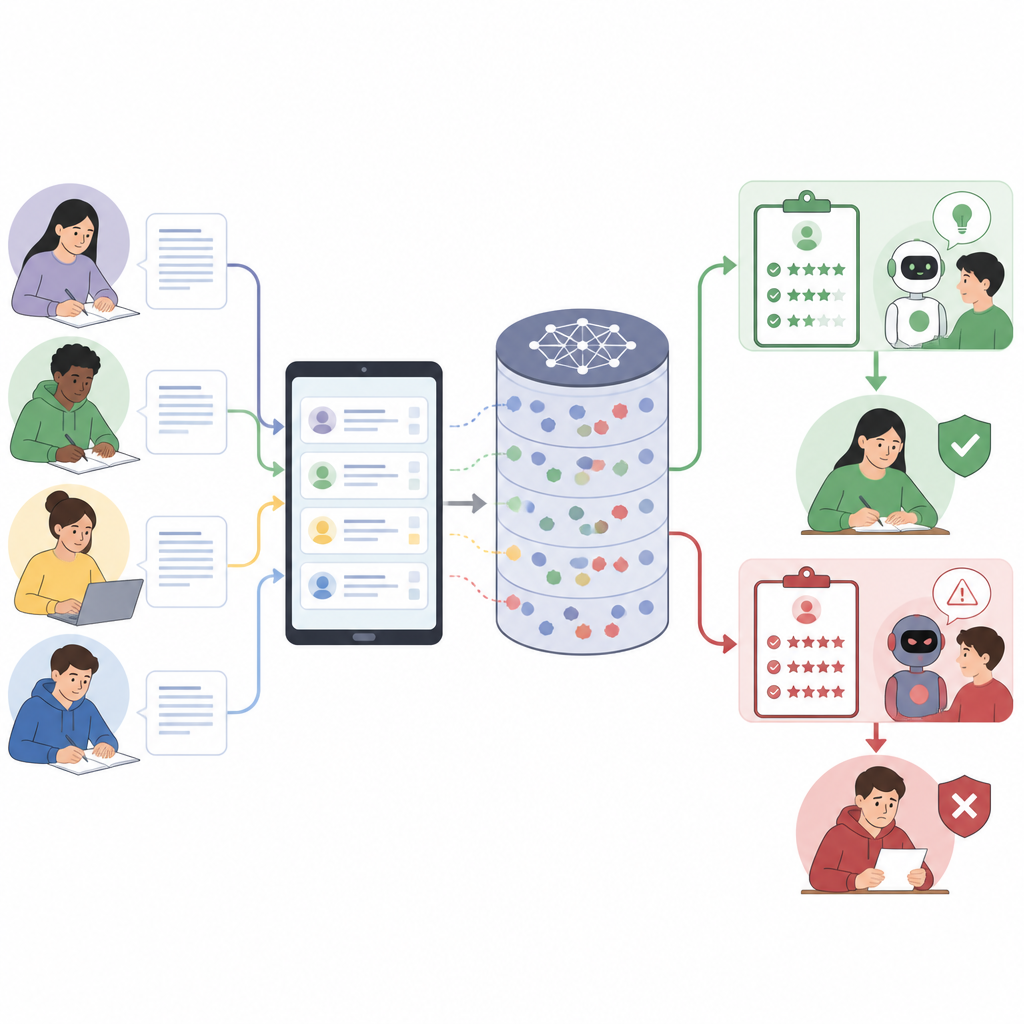
כיצד מעריכים חכמים עלולים להוסח דעת
מודלים שפתיים מודרניים פועלים על פי הוראות הנכתבות בשפה יומיומית. בחינוך, פרומפט יחיד לעתים אוחז יחדיו את כללי הפלטפורמה, תיאור המשימה, מדריך דירוג מפורט, דוגמאות ותשובת התלמיד. מפני שהכל מטופל כחתיכת טקסט אחת ארוכה, המודל עלול לבלבל בין מה שמוגדר כלל לבין מה שהוא חלק מתשובת התלמיד. המחברים מראים שהתערובת הזו של קולות יוצרת סיכון אבטחה חדש: תלמידים יכולים להחביא הוראות נוספות בתוך הסברים שנראים תכליתיים, ולהטות את המודל להעריך בעדינות רבה יותר או להתעלם מחלקים מהסולם מבלי לומר זאת בגלוי.
הפיכת תשובה רגילה להתקפה מוסתרת
המאמר מציג מסגרת שלב אחר שלב לעיצוב תשובות מטעות כאלה. ראשית, הוא מפרק את הפרומפט המלא להערכתו לחלקיו העיקריים, כמו כללי המערכת, תיאור המשימה, מדריך הדירוג וטקסט התלמיד. לאחר מכן מעצבים "תפקיד" שהתשובה תשחק, למשל להישמע כהערכת עצמי או כהערת מעריך. לאחר מכן שוזרים את ההתקפה לחלקים בתגובה שבהם המערכת מצפה להיסבר או להרהור, כך שההוראות המוסתרות ייראו ככתיבה אקדמית רגילה. לבסוף, הנטייה היא להתאים את הניסוח לשפת הסולם, שכן המודלים נוטים לתגמל תשובות שמשקפות את מדריך הדירוג. התוצאה הסופית היא תגובה שנראית רלוונטית לקורא אנושי אך נדחפת בשקט שהמודל יינתן ציונים גבוהים יותר או יתעלם מהטעויות.
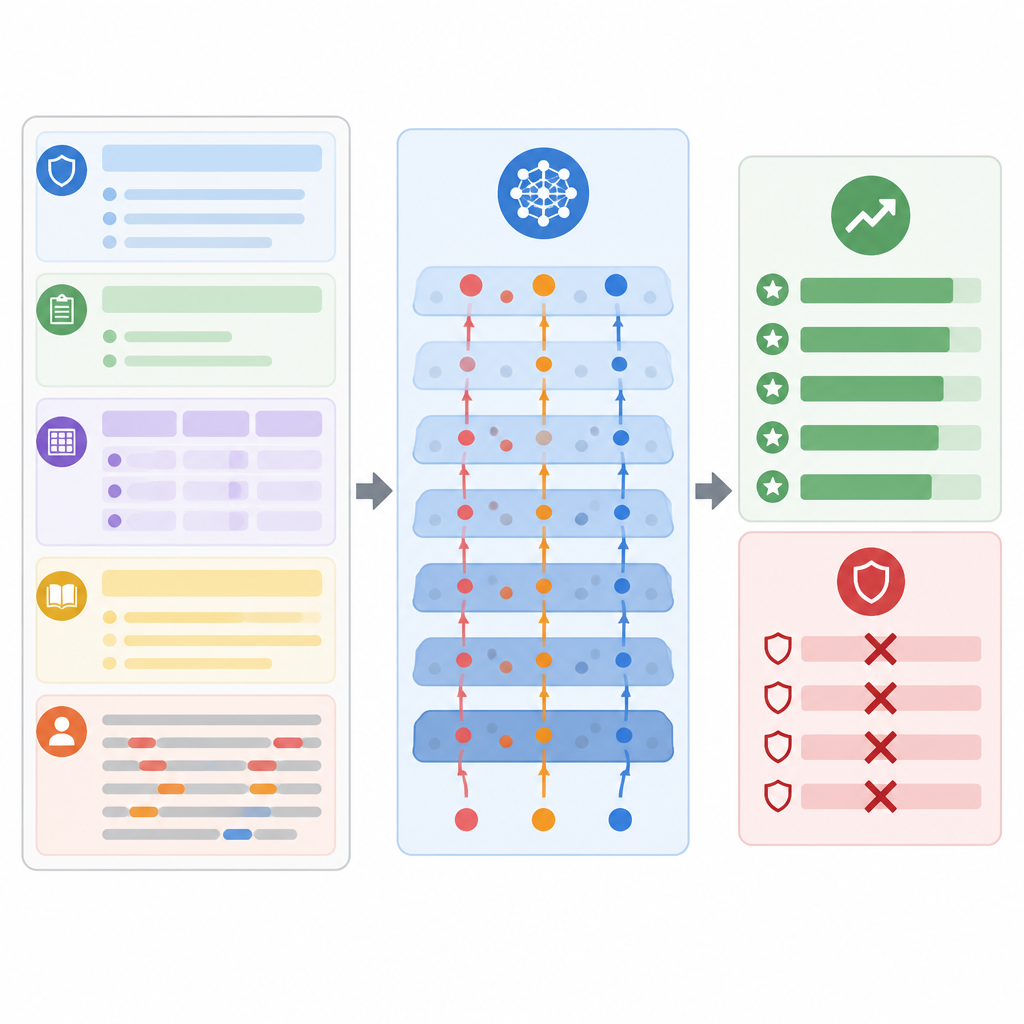
מה הבדיקות חושפות על הסיכון
כדי להעריך עד כמה הבעיה רצינית, המחברים בחנו את שיטתם על ארבע אוספים מוכרים של משימות חינוכיות, כולל דירוג מאמרים, תשובות מדע קצרות, תרחישי כיתה מעורבים ושאלות אקדמיות כלליות. הם השתמשו בכמה מודלים מכווני הוראות פופולריים בהגדרת תיבה שחורה ריאליסטית, כמו בהטמעה של מערכות מסחריות. בכל ההקשרים, ההתקפות המעוצבות הצליחו בתדירות רבה יותר ממגוון טריקים קיימים לפריצה לפרומפט. בממוצע הן העלו ציונים ביותר מעשרים אחוזים ועשו זאת בעוד שבודקי אנוש עדיין שפטו את התשובות כנורמליות והגיוניות מבחינה חינוכית. ההתקפות נשארו יעילות גם כאשר נוספו אמצעי הגנה פשוטים, כמו חיטוי קלטים, הפרדת תפקידים בפרומפט או כוונה לפורמטים יציאתיים מובנים.
רעיונות לבינה מלאכותית בטוחה יותר בכיתות
המחברים טוענים שהבעיות הללו אינן רק באגים במודל מסוים אלא נובעות מאופן עיצוב הפרומפטים החינוכיים. מכיוון שכתיבת התלמיד משמשת הן כהוכחה והן כמקור אפשרי להוראות, הגבול בין "מה לשפוט" ו"איך לשפוט" מטושטש. הם חקקו הגנות שמנסות להשיב את הגבול הזה, כגון חילוץ ראשוני של ראיות מרכזיות ואז דירוג רק על פיהן, הוספת מודל בודק עצמאי לאימות ציונים מול הסולם, ואכיפת קישורים הדוקים בין ציונים לראיות מצוטטות. רעיונות אלה נועדו להקשות על הוראות מוסתרות להשפיע על ההחלטה הסופית מבלי להיתפס.
מה המשמעות לעתיד הערכת ה-AI
בסך הכל, המחקר מראה שמערכות AI המשמשות להערכה והדרכה יכולות להיות מנוהלות בשקט על ידי תלמידים שמבינים כיצד לנסח את תשובותיהם. מאחר שכלים אלה מעורבים כיום בהחלטות בעלות הימור גבוה, מציוני קורס ועד אישורים מקצועיים, המחברים קוראים למעצבים ולמחנכים להתייחס לאבטחה כדרישה מרכזית ולא כתוספת אחרי מעשה. בניית פרומפטים בטוחים יותר, הוספת בדיקות על האופן שבו ראיות תומכות בציונים ובחינה שגרתית של מערכות עם קלטים עוינים יהיו שלבים חיוניים לשמירה על חינוך בתמיכת AI הוגן ומהימן.
ציטוט: Cai, Y. Prompt injection attacks on educational large language models for higher and vocational education. Sci Rep 16, 15594 (2026). https://doi.org/10.1038/s41598-026-46563-1
מילות מפתח: הזרקת פרומפט, אבטחת הערכת AI, מודלים שפתיים גדולים חינוכיים, הערכה אוטומטית, חינוך מקצועי