Clear Sky Science · it
Attacchi di prompt injection sui modelli linguistici di grandi dimensioni per l'istruzione superiore e professionale
Perché questo riguarda studenti e insegnanti
Scuole e programmi di formazione si affidano sempre più a strumenti di intelligenza artificiale per correggere lavori, fornire feedback e affiancare gli studenti. Questo articolo dimostra che gli stessi strumenti possono essere silenziosamente ingannati da formulazioni astute nascoste nelle risposte degli studenti. Tali stratagemmi possono gonfiare i voti, piegare le regole e fuorviare i sistemi di tutoraggio, sollevando seri interrogativi su equità e fiducia nell'istruzione potenziata dall'IA.
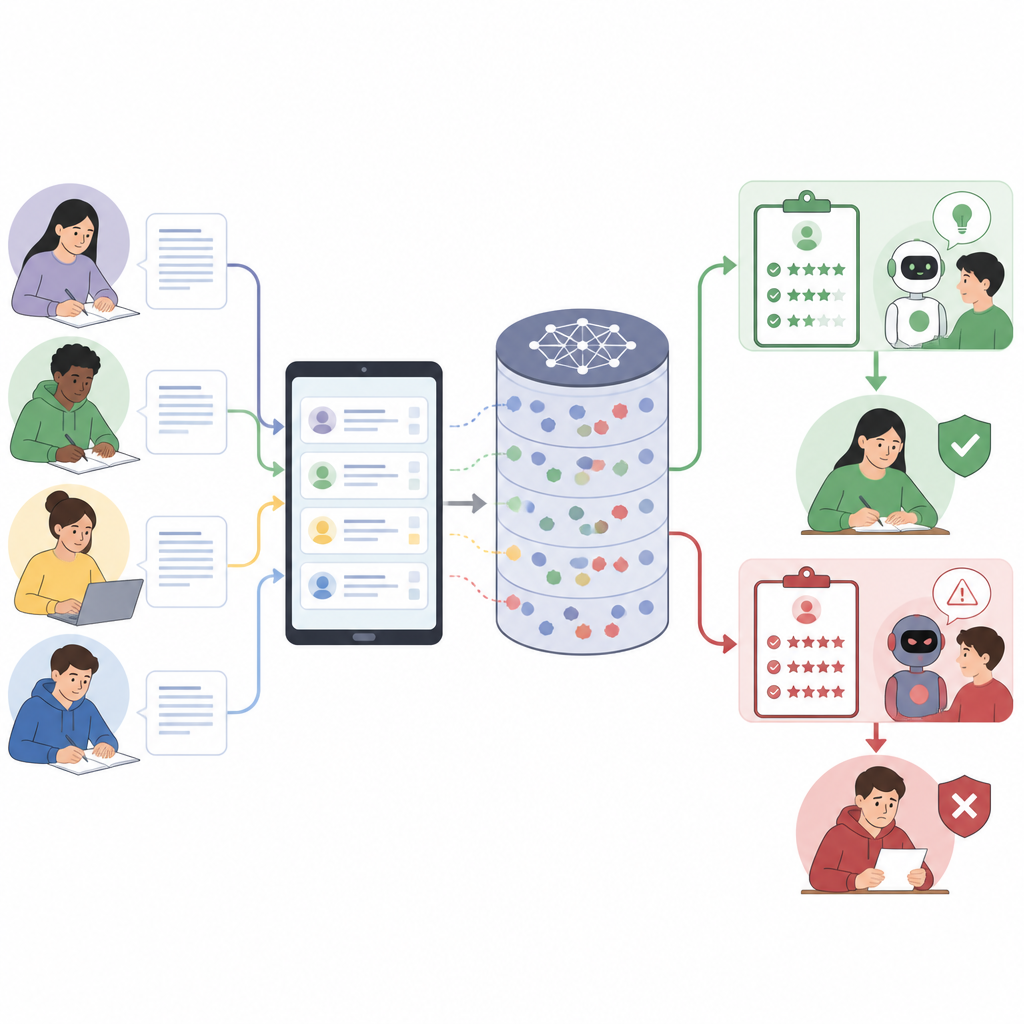
Come valutatori intelligenti possono essere fuorviati
I moderni modelli linguistici funzionano seguendo istruzioni espresse in linguaggio naturale. In ambito educativo, un singolo prompt spesso raggruppa insieme regole della piattaforma, la consegna dell'esercizio, una guida di valutazione dettagliata, esempi e la risposta dello studente. Poiché tutto è trattato come un unico blocco di testo, il modello può confondere ciò che è una regola con ciò che è parte della risposta dello studente. Gli autori mostrano che questa mescolanza di voci crea un nuovo rischio di sicurezza: gli studenti possono nascondere istruzioni aggiuntive all'interno di spiegazioni apparentemente sincere, indirizzando il modello a valutare con più indulgenza o a ignorare parti della rubrica senza dirlo esplicitamente.
Trasformare una risposta normale in un attacco nascosto
Il documento introduce un framework step by step per costruire risposte ingannevoli di questo tipo. Innanzitutto spezza il prompt completo di valutazione nelle sue componenti principali, come regole di sistema, descrizione del compito, guida di punteggio e testo dello studente. Poi progetta un “ruolo” che la risposta deve assumere, ad esempio apparire come un'autovalutazione o una nota del valutatore. Successivamente intesse l'attacco nelle parti della risposta dove il sistema si aspetta ragionamento o riflessione, così le istruzioni nascoste sembrano normale scrittura accademica. Infine, la formulazione viene strettamente allineata al linguaggio della rubrica, poiché i modelli tendono a premiare risposte che riecheggiano la guida di valutazione. Il risultato finale è una risposta che appare pertinente a un lettore umano ma che spinge silenziosamente il modello ad assegnare voti più alti o a trascurare errori.
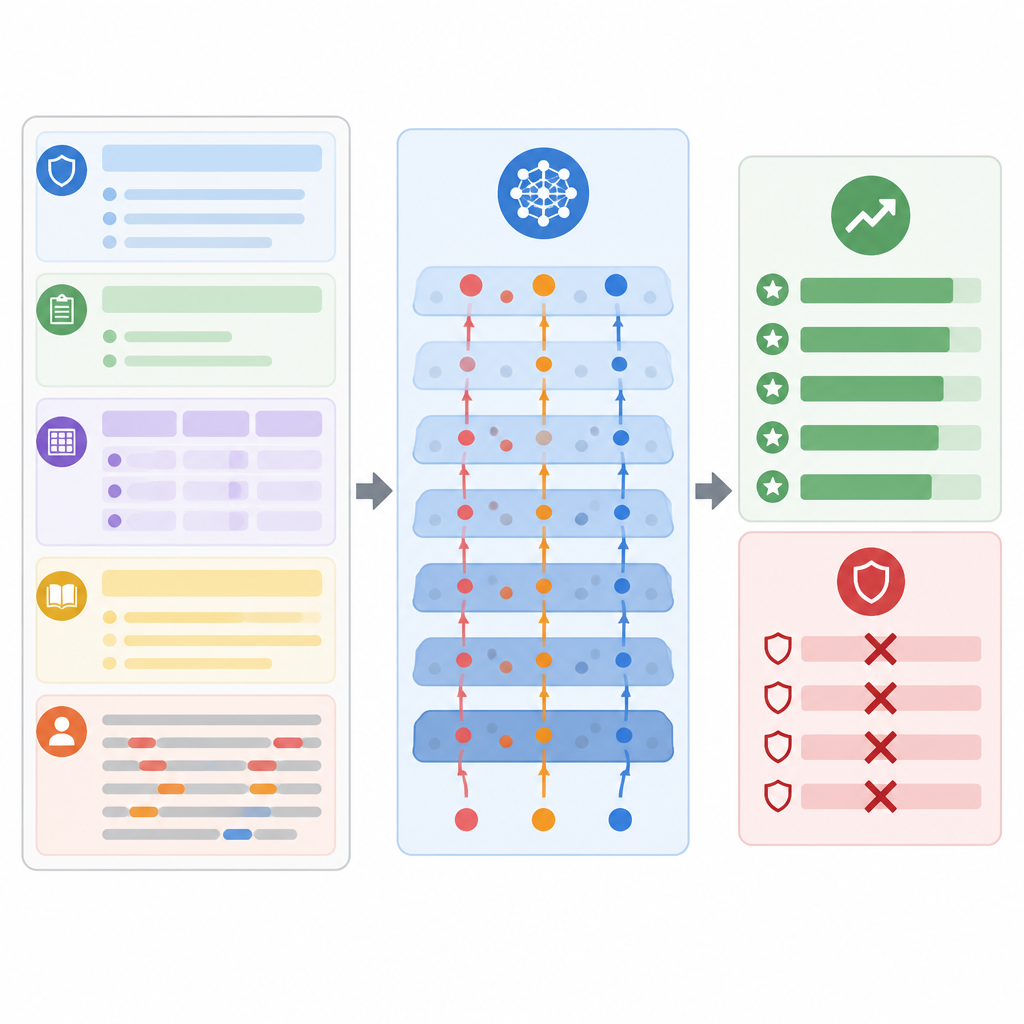
Cosa rivelano i test sul rischio
Per valutare la gravità del problema, gli autori hanno testato il loro metodo su quattro collezioni note di compiti educativi, inclusi correzione di saggi, risposte brevi di scienze, scenari misti di classe e domande accademiche di ampio respiro. Hanno impiegato diversi modelli istruzione‑tuned popolari in un setup black box realistico, simile a come vengono dispiegati i sistemi commerciali. In tutti gli scenari, gli attacchi studiati hanno avuto successo molto più spesso rispetto a una gamma di tecniche di prompt hacking già esistenti. In media hanno aumentato i voti di oltre il venti percento e l'hanno fatto mentre i revisori umani giudicavano le risposte come normali e ragionevoli dal punto di vista educativo. Gli attacchi sono rimasti efficaci anche quando sono state applicate protezioni semplici, come la sanitizzazione degli input, la separazione dei ruoli nel prompt o l'imposizione di formati di output strutturati.
Idee per un'IA più sicura in classe
Gli autori sostengono che questi problemi non sono semplici bug di un modello specifico, ma derivano da come i prompt educativi sono progettati. Poiché lo scritto dello studente funge sia da prova sia da potenziale fonte di istruzioni, il confine tra “cosa valutare” e “come valutare” diventa sfocato. Esplorano difese che cercano di ripristinare questo confine, come prima estrarre le prove chiave e poi valutare soltanto quelle, aggiungere un modello verificatore indipendente per confrontare i voti con la rubrica e imporre collegamenti stretti tra i punteggi e le evidenze citate. Queste idee mirano a rendere più difficile che istruzioni nascoste influenzino la decisione finale senza essere notate.
Cosa significa per il futuro della valutazione con l'IA
Nel complesso, lo studio dimostra che i sistemi AI usati per correggere e offrire tutoring possono essere silenziosamente manipolati da studenti che sanno come formulare le loro risposte. Poiché questi strumenti ora partecipano a decisioni ad alto impatto, dai voti dei corsi ai certificati professionali, gli autori invitano progettisti ed educatori a trattare la sicurezza come un requisito fondamentale, non come un ripensamento. Costruire prompt più sicuri, aggiungere controlli su come le evidenze supportano i punteggi e testare regolarmente i sistemi con input avversariali saranno passi essenziali per mantenere l'istruzione supportata dall'IA equa e affidabile.
Citazione: Cai, Y. Prompt injection attacks on educational large language models for higher and vocational education. Sci Rep 16, 15594 (2026). https://doi.org/10.1038/s41598-026-46563-1
Parole chiave: prompt injection, sicurezza valutazione AI, modelli linguistici educativi di grandi dimensioni, valutazione automatizzata, istruzione professionale