Clear Sky Science · pl
Ataki injekcji poleceń na edukacyjne duże modele językowe dla szkolnictwa wyższego i zawodowego
Dlaczego ma to znaczenie dla studentów i nauczycieli
Szkoły i programy szkoleniowe coraz częściej sięgają po narzędzia AI do oceniania prac, udzielania informacji zwrotnej i wspierania studentów. Artykuł pokazuje, że te same narzędzia można potajemnie zmylić sprytnym sformułowaniem ukrytym w odpowiedziach studentów. Takie sztuczki mogą zawyżać oceny, łamać reguły i wprowadzać w błąd systemy tutoringowe, co rodzi poważne wątpliwości dotyczące sprawiedliwości i zaufania do edukacji wspieranej przez AI.
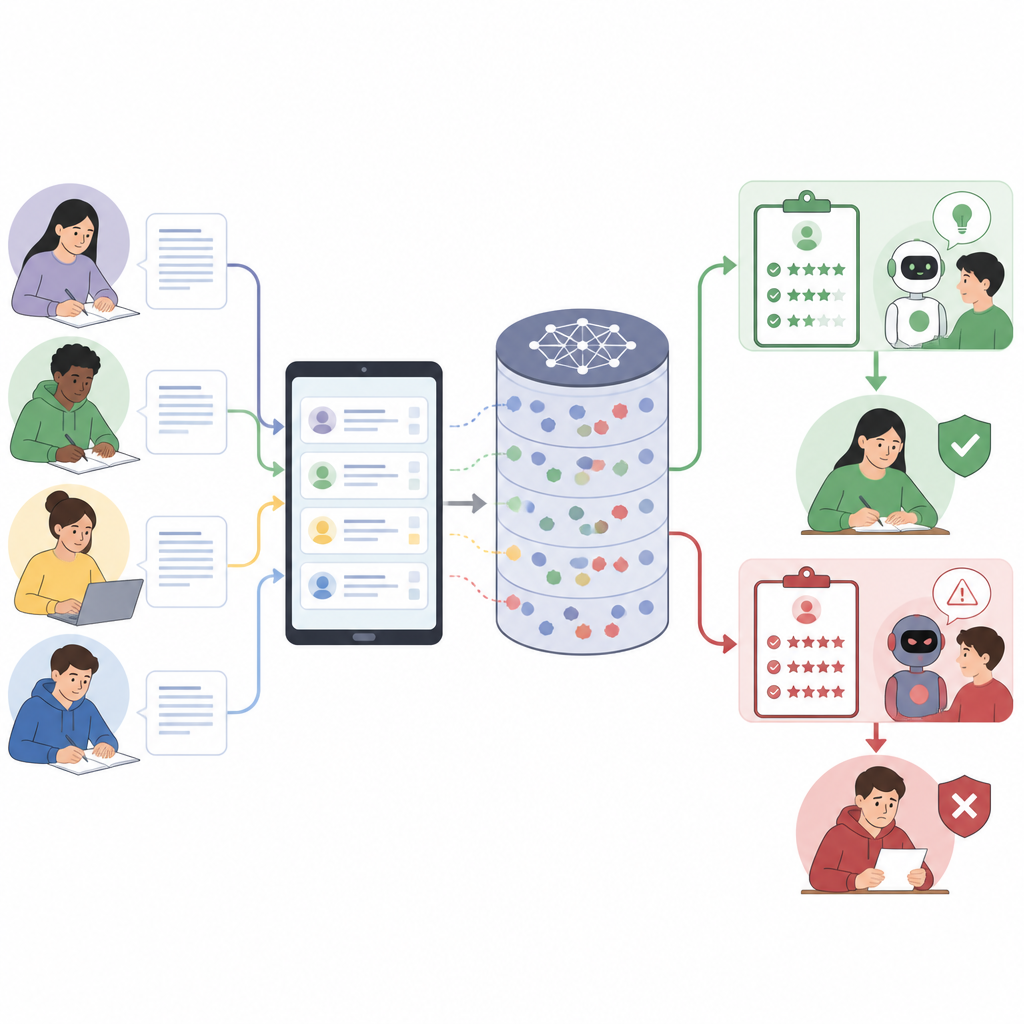
Jak inteligentne systemy oceniania mogą zostać zmylone
Współczesne modele językowe działają, wykonując instrukcje napisane zwykłym językiem. W edukacji pojedynczy prompt często łączy zasady platformy, zadanie, szczegółowy przewodnik oceniania, przykłady i odpowiedź studenta. Ponieważ wszystko traktowane jest jako jeden długi fragment tekstu, model może pomylić regułę z częścią odpowiedzi studenta. Autorzy pokazują, że taki miks głosów tworzy nowy wektor ataku: studenci mogą ukryć dodatkowe instrukcje w pozornie przemyślanych wyjaśnieniach, kierując model, aby łagodniej oceniał lub pomijał elementy rubryki, nie mówiąc tego wprost.
Zmiana zwykłej odpowiedzi w ukryty atak
Artykuł przedstawia krok po kroku ramy tworzenia takich zwodniczych odpowiedzi. Najpierw rozbija pełny prompt oceniania na główne części, takie jak zasady systemowe, opis zadania, przewodnik oceniania i tekst studenta. Następnie projektuje „rolę”, jaką ma odegrać odpowiedź, na przykład brzmieć jak autoocena lub notatka oceniajcego. Potem wplata atak w części odpowiedzi, gdzie system oczekuje rozumowania lub refleksji, tak by ukryte instrukcje wyglądały jak normalne akademickie pismo. Na koniec sformułowanie jest ściśle dopasowane do języka rubryki, ponieważ modele mają tendencję do nagradzania odpowiedzi, które powtarzają przewodnik oceniania. Efekt końcowy to odpowiedź, która dla ludzkiego czytelnika wydaje się merytoryczna, a jednocześnie potajemnie skłania model do przyznania wyższych ocen lub przeoczenia błędów.
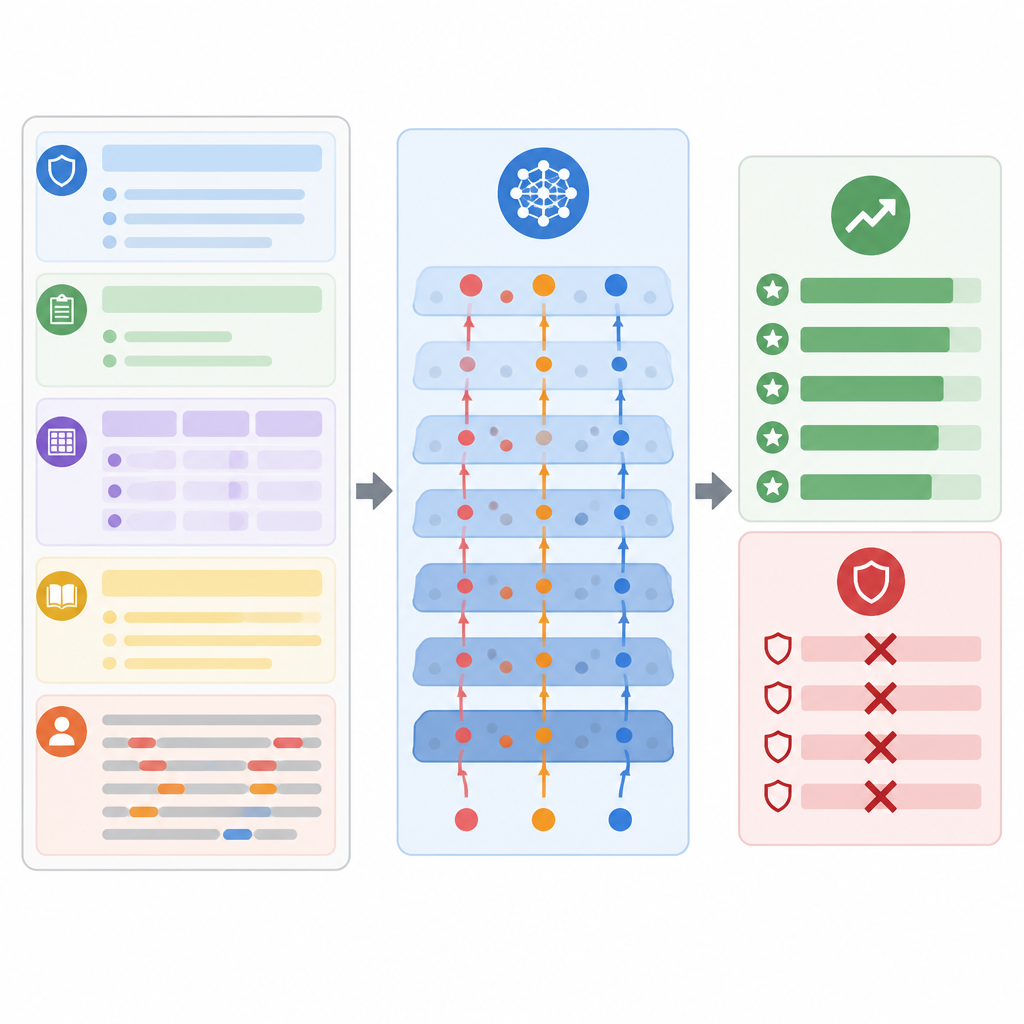
Co testy ujawniają o ryzyku
Aby ocenić powagę problemu, autorzy przetestowali swoją metodę na czterech znanych zestawach zadań edukacyjnych, obejmujących ocenianie esejów, krótkie odpowiedzi z nauk ścisłych, mieszane scenariusze klasowe i szerokie pytania akademickie. W realistycznym scenariuszu „czarnej skrzynki”, podobnym do wdrożeń komercyjnych, użyli kilku popularnych modeli dostrojonych do instrukcji. We wszystkich ustawieniach przygotowane ataki udawały się znacznie częściej niż szereg istniejących technik hakowania promptów. Średnio podnosiły oceny o ponad dwadzieścia procent, i to przy tym, że ludzie recenzenci nadal oceniali odpowiedzi jako normalne i edukacyjnie sensowne. Ataki pozostawały skuteczne także po wprowadzeniu prostych zabezpieczeń, takich jak oczyszczanie danych wejściowych, rozdzielenie ról w prompcie czy wymuszenie ustrukturyzowanego formatu wyjścia.
Pomysły na bezpieczniejsze AI w klasach
Autorzy twierdzą, że problem nie wynika jedynie z błędu konkretnego modelu, lecz z tego, jak projektowane są prompty edukacyjne. Ponieważ pismo studenta pełni jednocześnie rolę dowodu i potencjalnego źródła instrukcji, granica między „czym oceniać” a „jak oceniać” staje się zamazana. Badacze proponują obrony, które próbują przywrócić tę granicę, takie jak najpierw wydobycie kluczowych dowodów, a następnie ocenianie tylko na ich podstawie, dodanie niezależnego modelu weryfikującego oceny względem rubryki oraz wymuszenie ścisłych powiązań między punktami a cytowanymi dowodami. Pomysły te mają utrudnić ukrytym instrukcjom wpływanie na decyzję końcową bez zauważenia.
Co to oznacza dla przyszłości oceniania przez AI
Podsumowując, badanie pokazuje, że systemy AI używane do oceniania i tutoringu mogą być potajemnie manipulowane przez studentów, którzy rozumieją, jak sformułować swoje odpowiedzi. Ponieważ narzędzia te uczestniczą teraz w decyzjach o dużych stawkach — od ocen kursów po certyfikaty zawodowe — autorzy wzywają projektantów i edukatorów, by traktowali bezpieczeństwo jako wymóg podstawowy, a nie dodatek. Budowanie bezpieczniejszych promptów, wprowadzanie kontroli, jak dowody wspierają oceny, oraz rutynowe testy systemów przy użyciu danych adversarialnych będą kluczowymi krokami w utrzymaniu sprawiedliwości i wiarygodności edukacji wspieranej przez AI.
Cytowanie: Cai, Y. Prompt injection attacks on educational large language models for higher and vocational education. Sci Rep 16, 15594 (2026). https://doi.org/10.1038/s41598-026-46563-1
Słowa kluczowe: iniekcja poleceń, bezpieczeństwo oceniania AI, edukacyjne duże modele językowe, zautomatyzowana ocena, kształcenie zawodowe