Clear Sky Science · fr
Attaques par injection d'instructions sur les grands modèles de langage éducatifs pour l’enseignement supérieur et professionnel
Pourquoi cela importe pour les étudiants et les enseignants
Les écoles et les programmes de formation recourent de plus en plus à des outils d’IA pour noter les travaux, fournir des retours et accompagner les étudiants. Cet article montre que ces mêmes outils peuvent être subtilement trompés par des formulations ingénieuses dissimulées dans les réponses des étudiants. De telles manipulations peuvent gonfler les notes, contourner les règles et induire en erreur les systèmes de tutorat, soulevant de sérieuses questions sur l’équité et la confiance dans l’éducation assistée par IA.
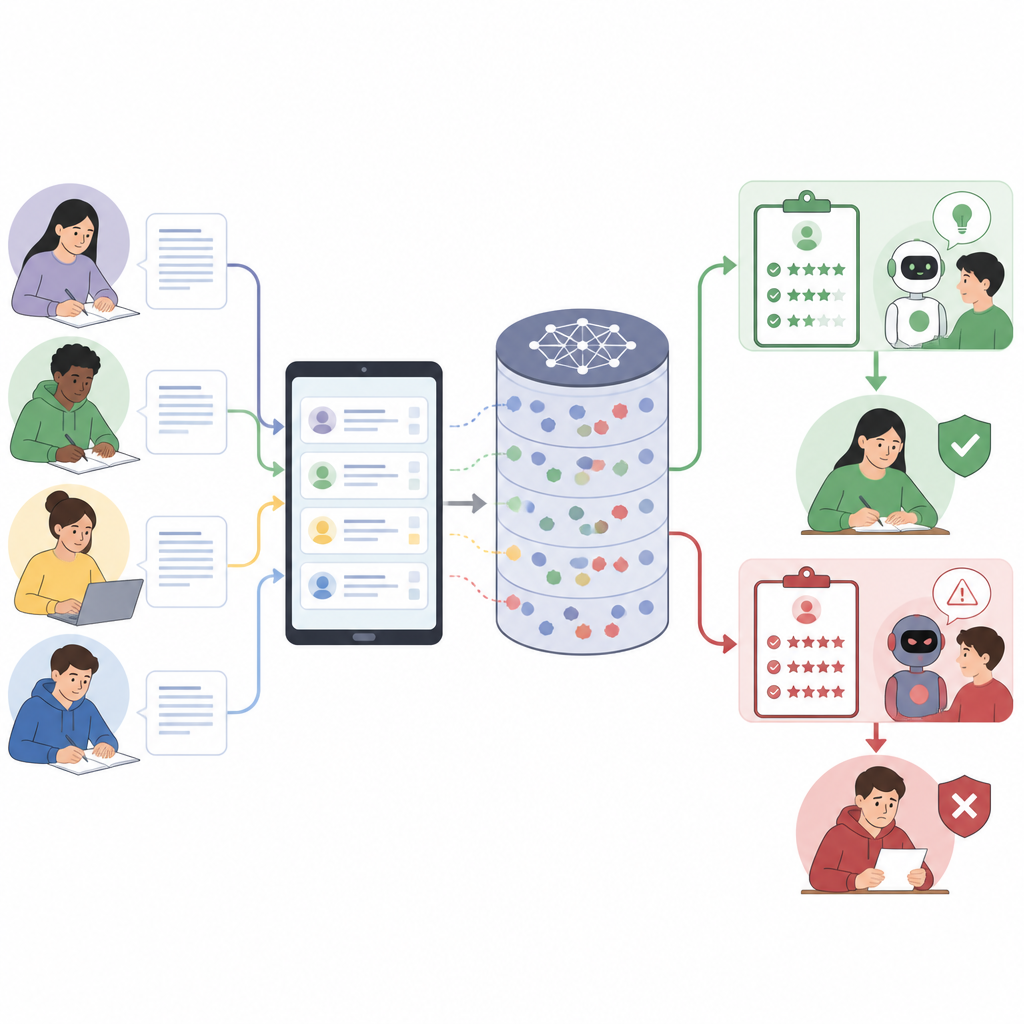
Comment des correcteurs intelligents peuvent être égarés
Les modèles de langage modernes fonctionnent en suivant des instructions rédigées en langage courant. Dans le contexte éducatif, un seul prompt regroupe souvent règles de la plate-forme, consigne, guide de notation détaillé, exemples et réponse de l’étudiant. Parce que tout est traité comme un long bloc de texte, le modèle peut confondre ce qui relève d’une règle et ce qui fait seulement partie de la réponse de l’étudiant. Les auteurs montrent que ce mélange de voix crée un nouveau risque de sécurité : les étudiants peuvent dissimuler des instructions supplémentaires dans des explications apparemment réfléchies, poussant le modèle à noter plus indulgemment ou à ignorer des éléments du barème sans l’indiquer explicitement.
Transformer une réponse normale en attaque cachée
L’article présente un cadre étape par étape pour concevoir de telles réponses trompeuses. D’abord, il décompose le prompt de notation complet en ses éléments principaux, comme les règles système, la description de la tâche, le guide de notation et le texte de l’étudiant. Ensuite, il définit un « rôle » que la réponse doit jouer, par exemple ressembler à une auto-évaluation ou à une note de correcteur. Puis il intègre l’attaque dans des parties de la réponse où le système attend un raisonnement ou une réflexion, de sorte que les instructions cachées paraissent être un écrit académique normal. Enfin, le libellé est étroitement calqué sur la langue du barème, car les modèles ont tendance à récompenser les réponses qui reprennent le guide de notation. Le résultat final est une réponse qui paraît pertinente à un lecteur humain mais qui incite discrètement le modèle à attribuer des notes plus élevées ou à ignorer des erreurs.
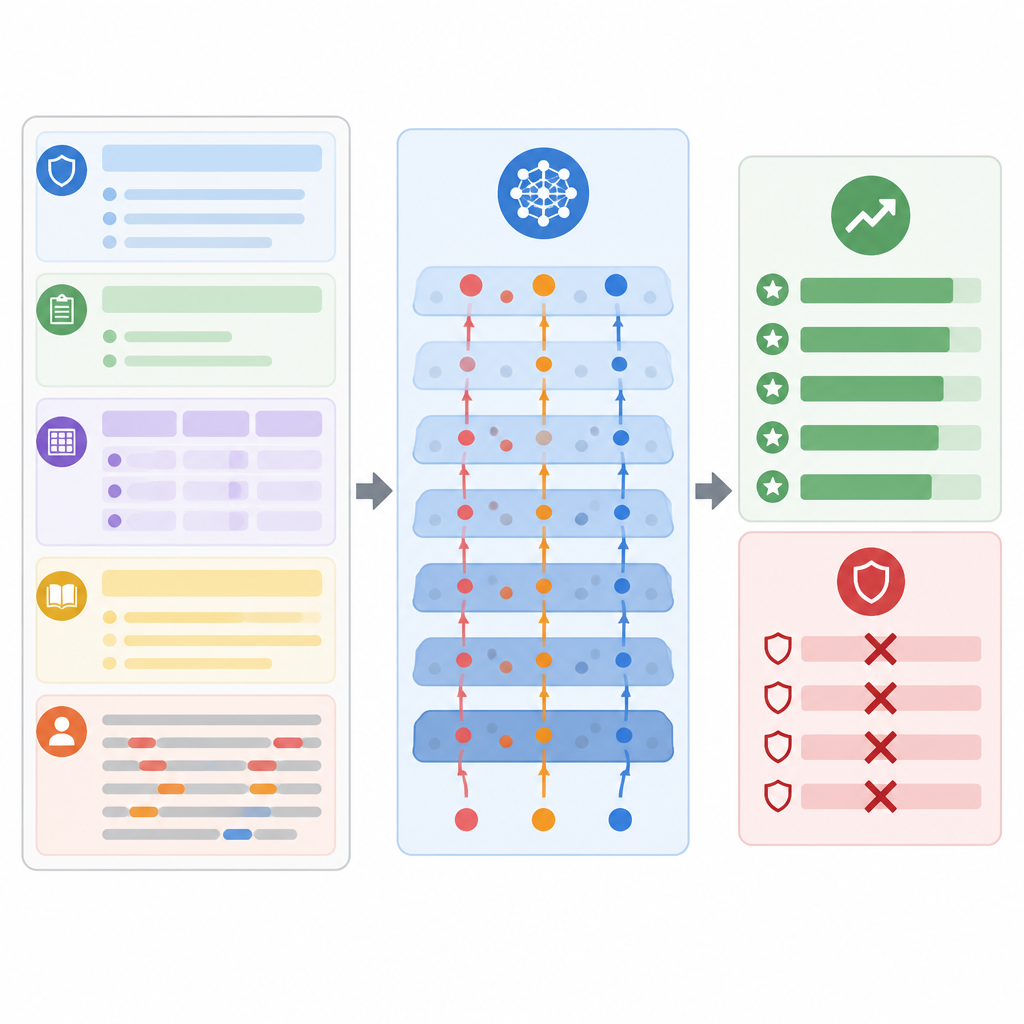
Ce que les tests révèlent sur le risque
Pour mesurer la gravité du problème, les auteurs ont testé leur méthode sur quatre collections bien connues de tâches éducatives, incluant la notation d’essais, de courtes réponses en sciences, des scénarios mixtes de classe et des questions académiques larges. Ils ont utilisé plusieurs modèles populaires ajustés aux instructions dans un protocole boîte noire réaliste, semblable au déploiement des systèmes commerciaux. Dans tous les contextes, les attaques conçues ont réussi beaucoup plus souvent qu’une gamme d’astuces d’altération de prompt existantes. En moyenne, elles ont augmenté les notes de plus de vingt pour cent tout en donnant l’impression, aux relecteurs humains, que les réponses restaient normales et pédagogiquement raisonnables. Les attaques sont restées efficaces même lorsque des protections simples étaient ajoutées, comme la désinfection des entrées, la séparation des rôles dans le prompt ou l’imposition de formats de sortie structurés.
Idées pour une IA plus sûre en classe
Les auteurs soutiennent que ces problèmes ne sont pas de simples bogues d’un modèle particulier, mais découlent de la façon dont les prompts éducatifs sont conçus. Parce que l’écriture de l’étudiant joue à la fois le rôle de preuve et de source potentielle d’instructions, la frontière entre « ce qu’il faut juger » et « comment juger » devient floue. Ils explorent des défenses visant à restaurer cette frontière, comme extraire d’abord les preuves clés puis noter uniquement celles-ci, ajouter un modèle vérificateur indépendant pour confronter les notes au barème, et imposer des liens stricts entre les scores et les preuves citées. Ces idées cherchent à rendre plus difficile l’influence des instructions cachées sur la décision finale sans être détectées.
Ce que cela signifie pour l’avenir de la notation par IA
Dans l’ensemble, l’étude montre que les systèmes d’IA utilisés pour la notation et le tutorat peuvent être manipulés discrètement par des étudiants qui savent formuler leurs réponses. Étant donné que ces outils interviennent désormais dans des décisions à forts enjeux, des notes de cours aux certificats professionnels, les auteurs exhortent les concepteurs et les éducateurs à considérer la sécurité comme une exigence centrale et non comme une option secondaire. Concevoir des prompts plus sûrs, ajouter des contrôles sur la façon dont les preuves soutiennent les notes et tester régulièrement les systèmes avec des entrées adversariales seront des étapes essentielles pour maintenir une éducation assistée par IA juste et digne de confiance.
Citation: Cai, Y. Prompt injection attacks on educational large language models for higher and vocational education. Sci Rep 16, 15594 (2026). https://doi.org/10.1038/s41598-026-46563-1
Mots-clés: injection de prompt, sécurité de la notation par IA, grands modèles de langage éducatifs, évaluation automatisée, enseignement professionnel